首先,我们了解一下相关背景。信息抽取(Information Extraction,简称IE)的核心目标,是从非结构化文本中挖掘出结构化数据。而关系抽取作为IE的关键子任务,主要识别实体之间的特定语义关联。当前基于神经网络的深度学习方法在精确度方面表现优异,但也存在明显短板——召回率往往有所折损,即对相关实体的全面识别能力不足。更棘手的是,这些方法大多只适用于单个段落,面对整本书、多页网页等长篇文本时,几乎束手无策。因此,一个自然衍生出的问题便是:我们能否从长文本中提取出与特定主题相关的长对象列表?
从长篇内容中提取长列表的典型场景
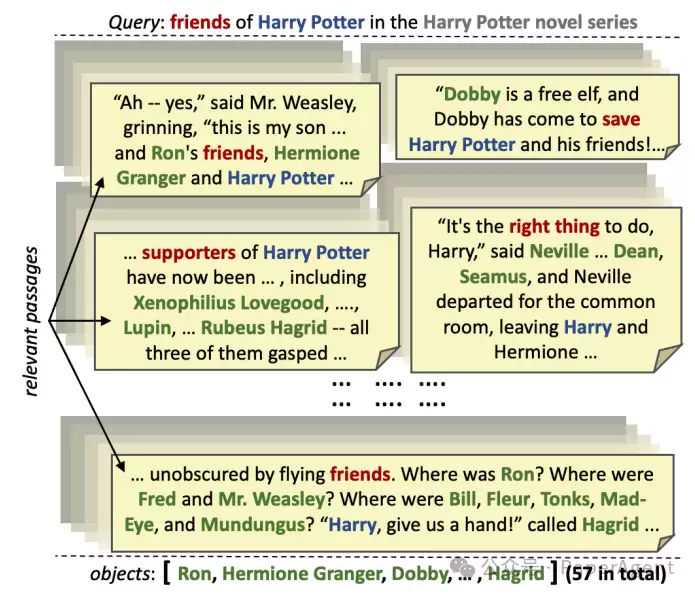
以“哈利·波特”主题为例,目标是从整个系列书籍中完整找出57位朋友角色。由于信息分散在数百页的文本中,这绝非易事。
L3X:两阶段长列表提取方案
针对这一难题,研究人员提出了L3X方法(即基于语言模型的长列表抽取)。其核心思想可分解为两个阶段:
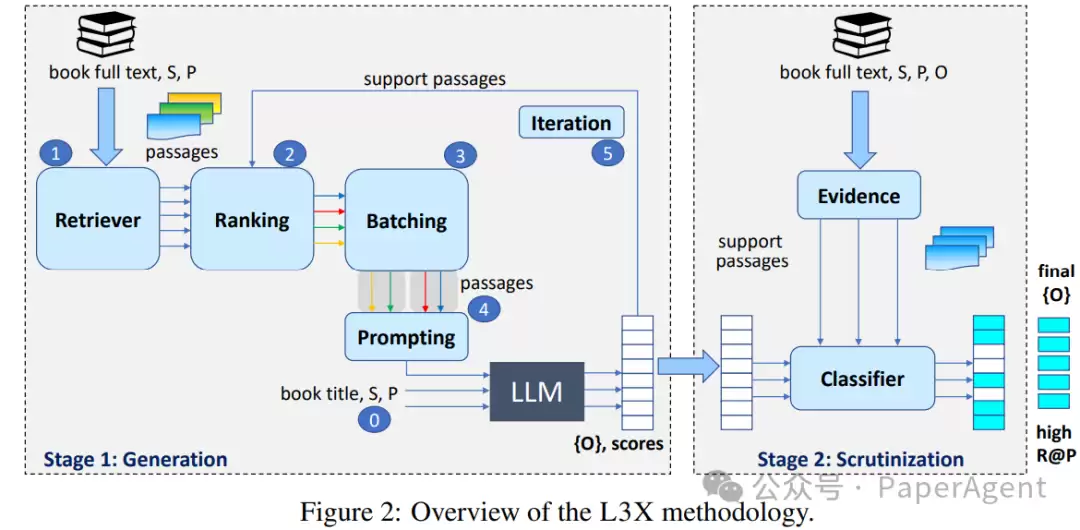
第一阶段:召回导向的生成
这一阶段的关键词是“海选”。具体做法是:围绕当前主题及关系,向大型语言模型(LLM)提供提示,促使其尽可能生成一份完整的目标对象列表。同时,通过信息检索系统从长文本中挖掘出那些看似有希望的候选段落,并将其纳入LLM的提示中。与以往检索增强型LLM的思路不同,此阶段会检索大量段落(例如针对某个SPO三元组可检索多达500个),并精心挑选最匹配的段落用于模型提示。此外,这一过程并非一次性完成——它会迭代地对段落重新排序,并反复让LLM生成,从而不断优化初始对象列表。简而言之,先宽进,把可能相关的内容都纳入,再逐步筛选。
第二阶段:精确导向的审查
在第一步获得高召回率的候选对象列表后,接下来进入“严出”环节。该阶段的目标是精准验证与修剪。它采用偏保守的技术,专门识别高置信度的对象,找到对应的支持段落,同时重新评估那些可信度存疑的候选对象,最终剔除不合格者。
实验效果与总结
在新构建的数据集(包含10本书、8种不同关系类型)上进行的实验表明,L3X方法在召回率和R@P指标上全面优于仅依赖LLM生成的方法。换言之,该方法能够有效从长篇文档中提取出较长的对象列表。当然,通过优化提示策略、段落排序以及批处理技术,其性能还有进一步提升的空间。
论文地址:
Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
https://arxiv.org/pdf/2405.02732