安全帽检测实战项目:从数据准备到模型部署
准备训练数据:如何获取高质量标注数据集
首先解决一个基础问题:训练数据从何而来?在本项目中,我们直接前往Kaggle平台搜索现成的数据集即可。尝试搜索“Safety Helmet”或“worker safety”,你会找到不少高质量的标注数据。
这里强烈推荐使用“YOLOv8 - Safety Helmet Detection”数据集,其标注质量较高,且类别覆盖相当全面。
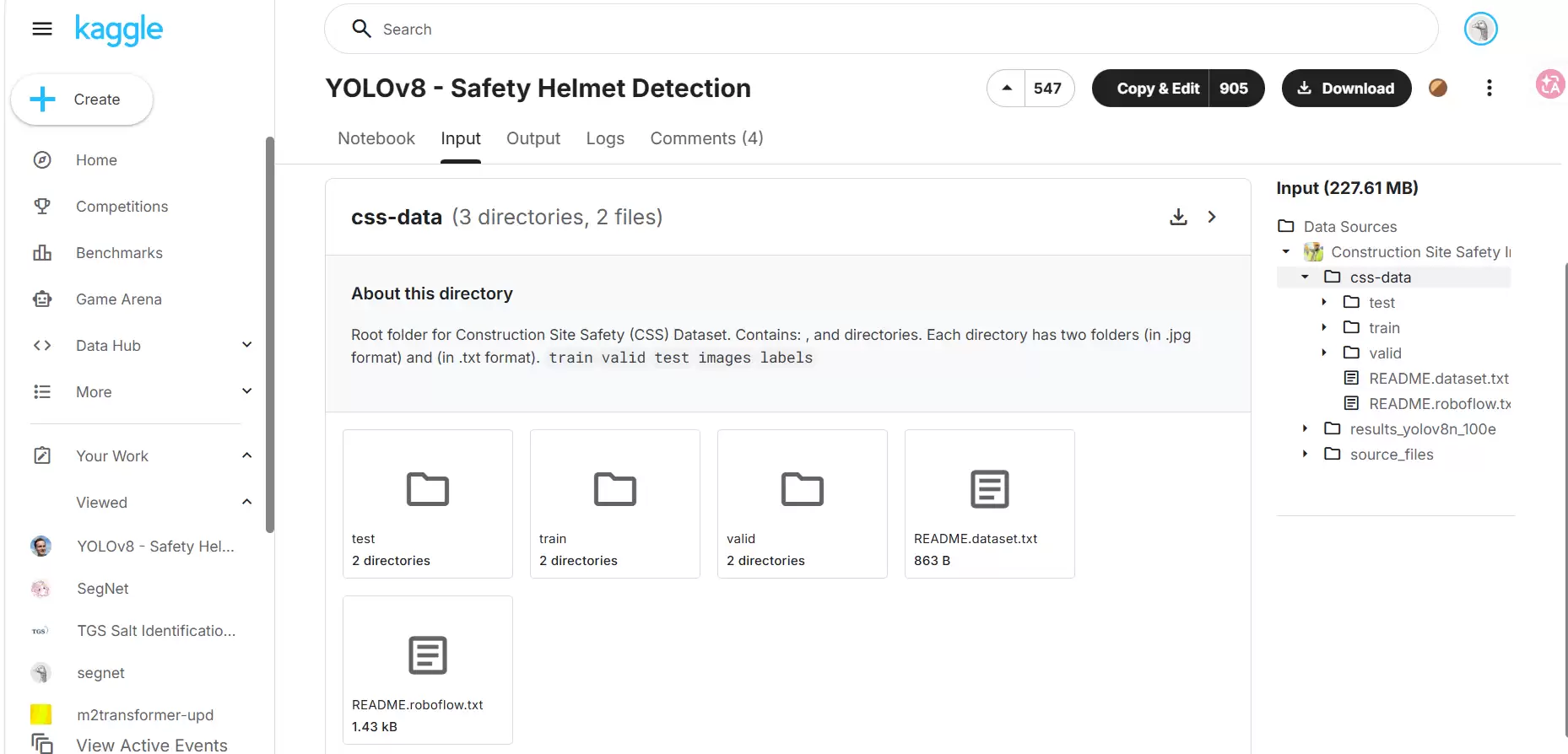

接下来,我们需要提前准备好数据集的配置文件。让我们看看safehat.yaml中包含了哪些内容:
配置文件准备完毕后,就该编写训练脚本了。创建一个yolo_train.py文件,其核心逻辑相当简洁:
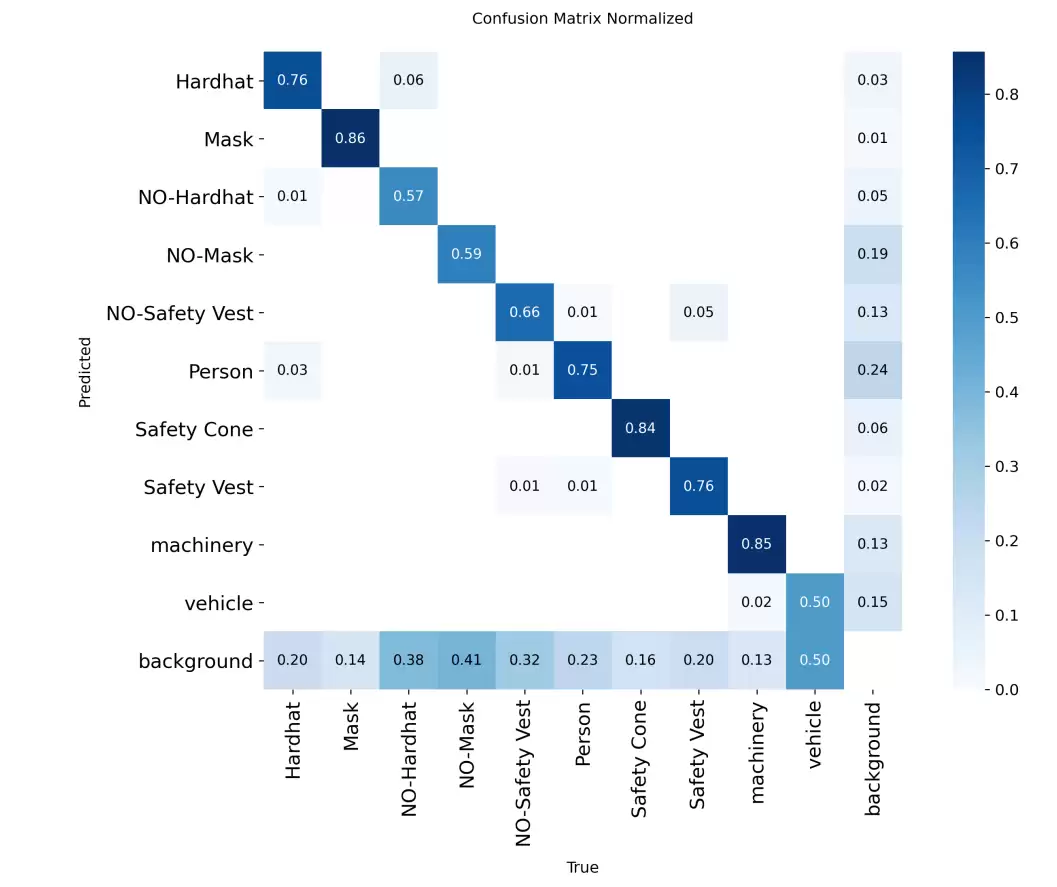
这里我们采用了YOLOv8的预训练模型进行微调,这能显著缩短训练时间,同时取得更优效果。训练结束后,所有结果都会保存在runs > detect > train路径下,其中包含损失曲线、效果图等可视化输出。
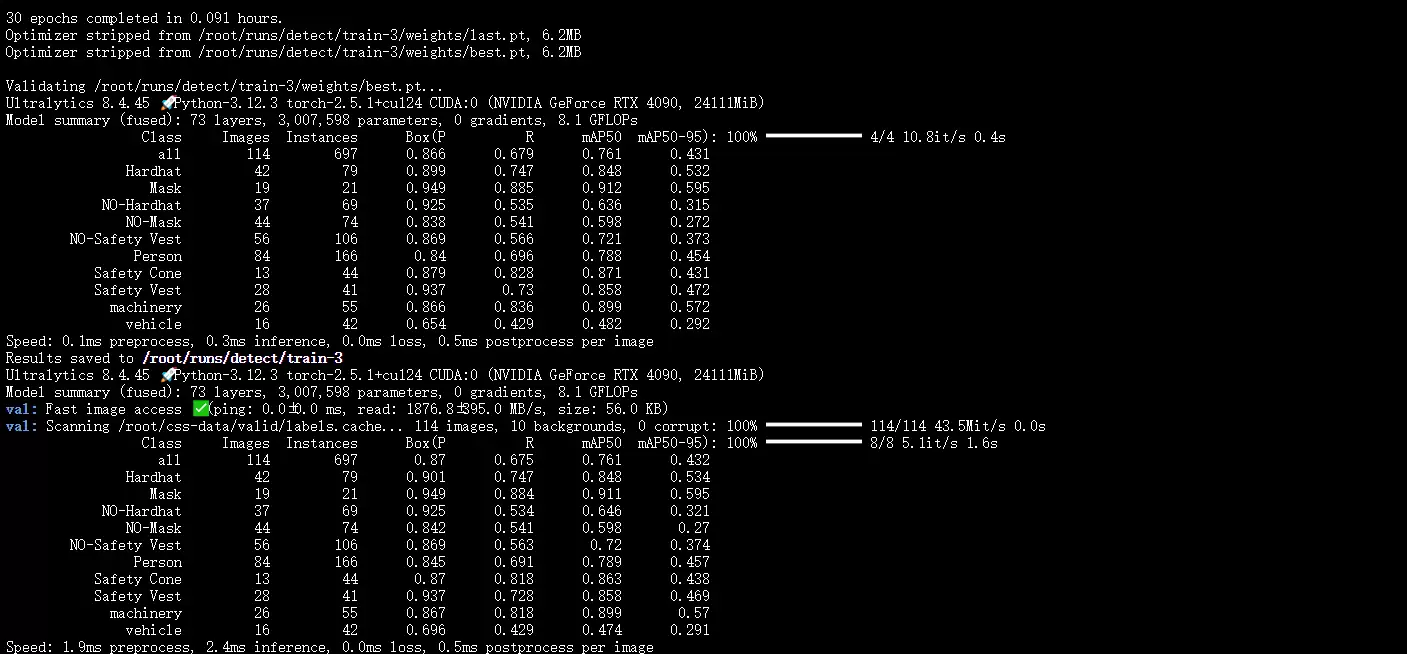

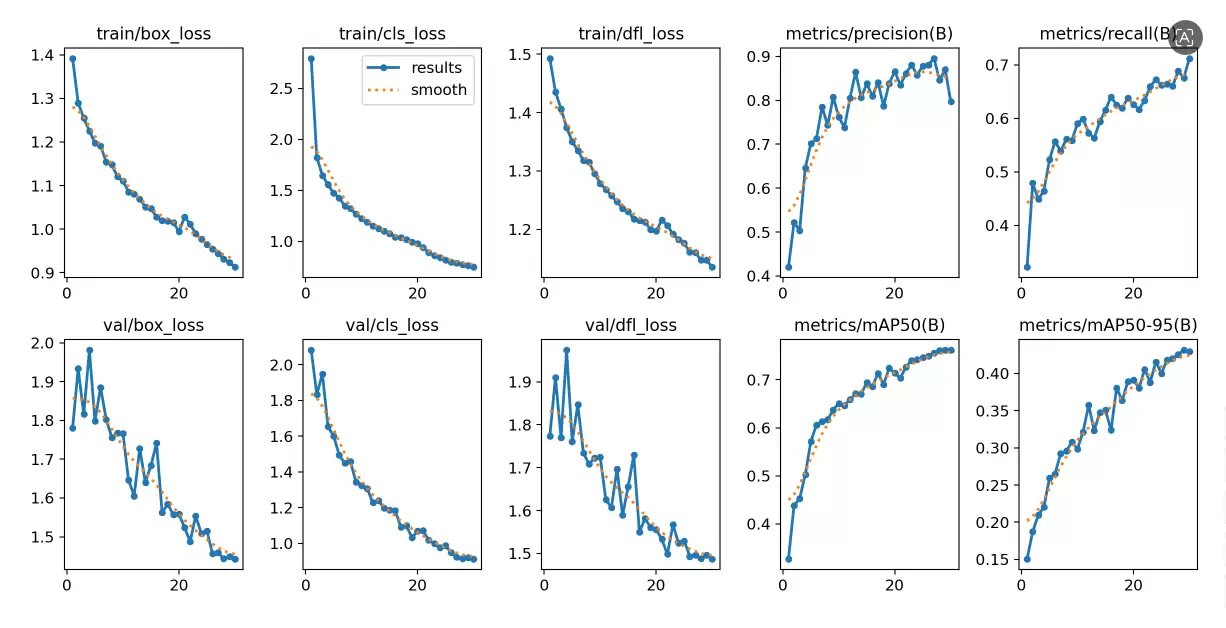
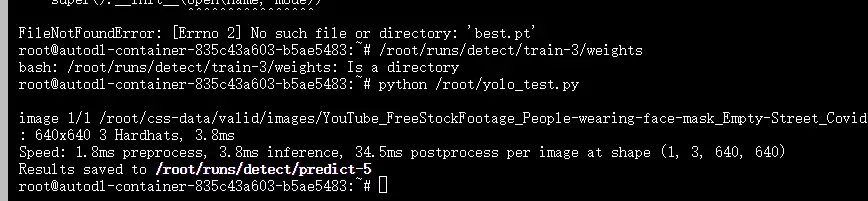
模型训练完成后,当然需要实际测试其效果。测试脚本yolo_test.py同样非常简洁:
识别结果将自动保存在目录runs/detect/predict中。通过观察可以看到,模型已经能够准确区分工人是否佩戴了安全帽。

安全帽模型部署方案详解
模型训练完毕,下一步就是部署上线。部署的首要工作是格式转换。
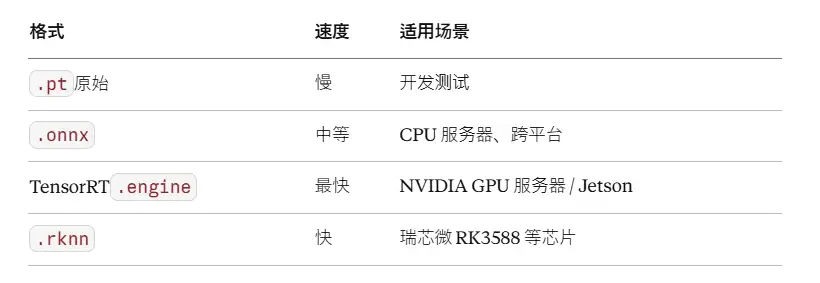
转换过程非常简单,利用Ultralytics一行代码即可实现:
接下来,针对不同应用场景,我们提供了三种主流的部署方案。
场景一:服务器/云端部署(适合多用户远程调用)
这一方案适用于哪些情况?
- 需要多人、多系统同时调用模型
- 算力集中在服务器端
- 用户通过网页或App上传图片进行检测
核心思路:
模型始终运行在服务器上,不会暴露给用户,安全性也得到了充分保障。
第一步:用 FastAPI 封装推理接口
第二步:用 Docker 打包应用
第三步:外部调用测试
高并发场景:Triton 推理服务器
如果遇到大量用户同时并发请求(比如同时服务几十个工厂),普通的FastAPI可能难以承受。这时推荐使用NVIDIA Triton推理服务器,配合负载均衡:
场景二:Jetson 边缘设备部署(适合本地实时推理)
这一方案适用于哪些情况?
- 需要在设备本地进行实时推理,不依赖网络
- 典型场景:工厂产线检测、智能摄像头、机器人视觉
- 常用设备:Jetson Nano / Xavier / Orin 系列
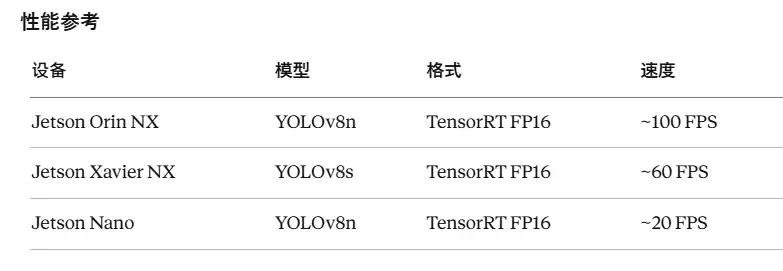
核心:转换为 TensorRT 格式
Jetson设备自带NVIDIA GPU,使用TensorRT可充分利用硬件加速,性能提升非常明显。
在 Jetson 上推理
场景三:RK3588 嵌入式部署(低成本国产平台)
这一方案适用于哪些情况?
- 低成本嵌入式设备,无NVIDIA GPU
- 典型场景:工业检测设备、国产嵌入式平台
- 常用设备:RK3588 / RK3566 / RK1808 等瑞芯微芯片
核心:转换为 RKNN 格式
RK3588内置NPU(算力6 TOPS),必须转换为.rknn格式才能利用NPU加速。转换链路如下:
best.pt → best.onnx → best.rknn
pt → onnx(PC上操作)
onnx → rknn(PC上操作)
第三步:将模型传到 RK3588
第四步:在 RK3588 上推理

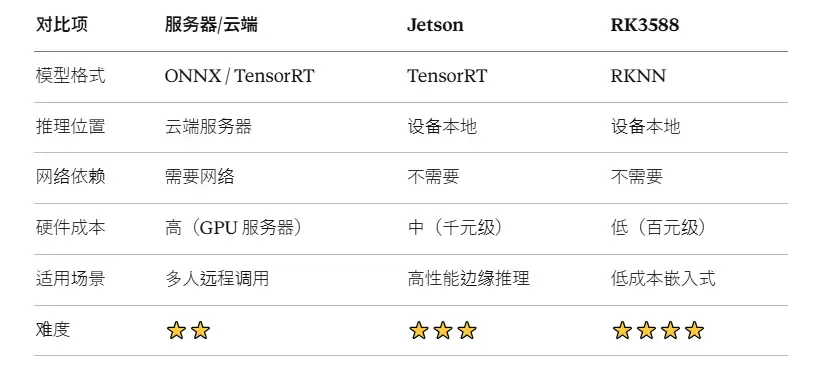
最后,用一张简单的决策树来总结不同场景的选择方案:




