
今天我们来聊聊那个常被忽视但至关重要的环节——GPU之间的通信网络。在AI工厂时代,这不再是“管道”那么简单,它本身就是计算机的一部分。
本课程是英伟达认证专业人工智能网络工程师(NCP-AIN)培训体系的一部分,核心目标就是带你掌握面向AI业务的高性能网络拓扑设计与优化方法。
简单介绍一下,NCP-AIN是英伟达的专业级AI网络认证,全称是AI Networking。它主要考核从业者运用英伟达高速网络技术,来部署、配置和运维AI数据中心网络环境的能力。
(考试信息可以访问:https://www.nvidia.cn/training/certification/ai-networking-professional/)
NCP-AIN 备考(3):人工智能数据中心轨道优化架构
NCP-AIN 备考(2):人工智能数据中心打造AI算力工厂
NCP-AIN 备考(1):网络拓扑优化核心知识
我们开始进入正题。今天,我们将重点拆解GPU间通信的关键领域——它堪称现代AI工厂的命脉。
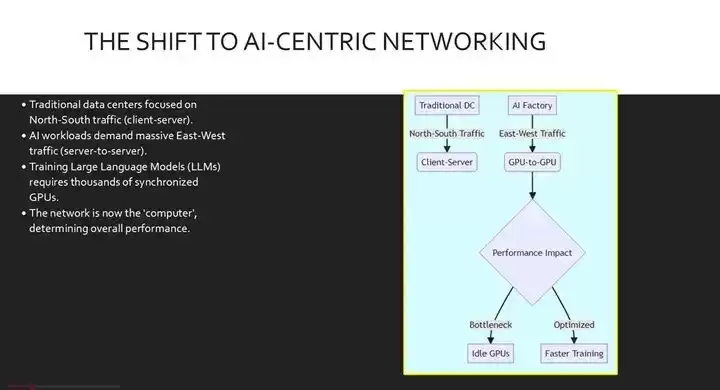
先看一个根本性的变化。在传统的云数据中心里,流量模式主要是南北向的,也就是数据在数据中心内外流动,服务于用户与应用程序的交互。但AI时代的到来,彻底改变了这个模式。
现在,我们面对的是专为大规模工作流设计的AI工厂,比如训练那些动辄千亿、万亿参数的大语言模型。这些工作负载计算密集,必须依赖分布式计算,将单个作业拆分到数千个GPU上并行执行。因此,最主要的流量模式变成了东西向,也就是服务器与服务器之间的通信。
在这种新环境下,网络不再是简单的管道,它变成了计算机本身。一旦网络出现瓶颈,那些价格昂贵的GPU就会闲置,白白浪费时间和资源。上图很好地展示了这一流量模式的根本性转变:左侧是传统的南北向流量主导模型,右侧则是AI工厂模型,东西向的GPU间通信占据绝对主导。这里有一个关键的决策点——这种东西向通信的质量,直接决定了GPU是在“酣畅淋漓”地训练,还是“无所事事”地空转。
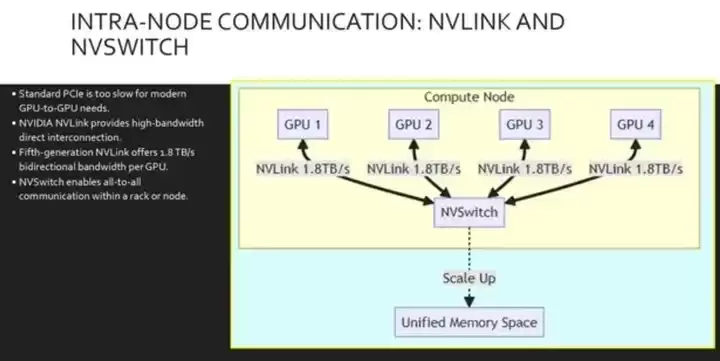
在我们考虑整个网络之前,先把目光聚焦到服务器节点内部。标准的PCIe接口,根本处理不了GPU高效共享内存和计算所需的带宽。为了解决这个瓶颈,NVIDIA推出了NVLink——一种高速纵向扩展的互连技术。
第五代NVLink,每个GPU能提供高达1.8TB/s的双向吞吐量,这个带宽是PCIe Gen 5的14倍以上。为了连接多个GPU,我们引入了NVSwitch。这款芯片连接多个NVLink,以全速提供完全的全对全通信。这意味着,一整排GPU可以作为一个单一、巨大的翻跟斗来运行。
我们来看看这个节点内部的拓扑结构图。注意,每个GPU都通过NVLink直接连接到NVSwitch,完全绕过了速度较慢的PCIe总线进行点对点流量传输。这就创建了一个高带宽的网状结构,数据以1.8TB/s的速率在GPU之间自由流动,实际上形成了一个统一的内存空间。这种结构对“模型并行”至关重要——当你训练的单个AI模型太大,无法塞进单个GPU时,就得靠这个。
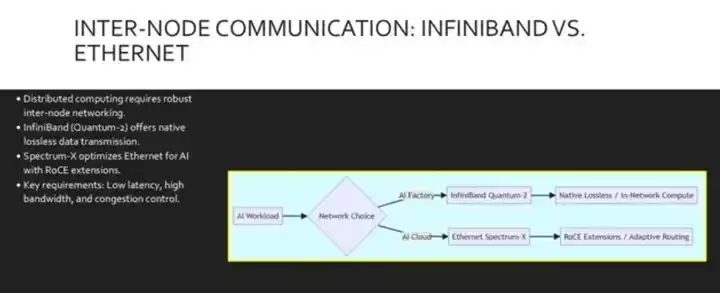
一旦流量离开节点,我们就进入了节点间网络的领域。对于AI工厂,NVIDIA Quantum 2 InfiniBand通常是首选平台。原因很简单:它拥有超低延迟、自愈能力,以及对网络内计算的原生支持(比如Sharp技术)。
然而,很多AI云平台更倾向于使用以太网。问题在于标准以太网会有丢包,且并非为AI这类强耦合工作负载设计。为了弥合这个差距,NVIDIA推出了Spectrum-X平台,它通过融合以太网RoCE(RDMA over Converged Ethernet)扩展了以太网的RDMA功能。它为以太网引入了自适应路由和拥塞控制,从而提供了多租户AI云所需的性能隔离。
怎么选?这个流程图帮了我们大忙。如果你在构建专用的AI工厂,那就选InfiniBand Quantum 2,它有原生的无损特性以及网络计算能力(比如Sharp)。如果你在构建多租户AI云,那就走以太网+Spectrum-X的路线,它为标准以太网补上了RoCE和自适应路由等关键功能。
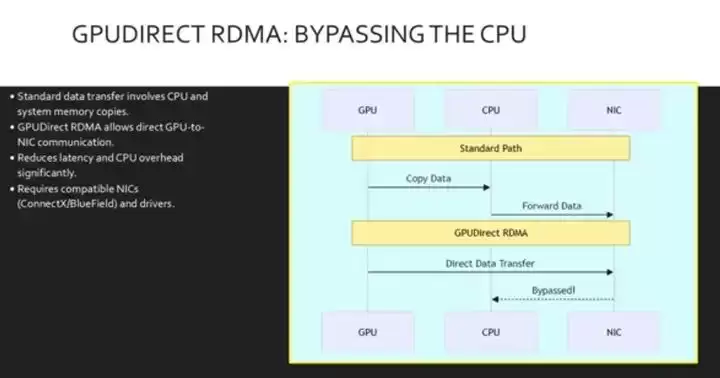
在标准网络中,要把数据从GPU搬到网络上,需要先复制到CPU的系统内存里。这无疑增加了延迟,还消耗了宝贵的CPU周期。GPU直接RDMA(远程直接内存访问)技术,就消除了这个瓶颈。
它允许网络接口卡(NIC)直接访问GPU的内存,在GPU和对等设备之间建立了一条直接的数据交换路径,完全绕过了CPU。这个序列图清晰地对比了两种传输方式。上半部分是标准路径,数据从GPU到CPU再到NIC,多次“跳转”引入了延迟。下半部分是GPU直接RDMA,GPU直接把数据发送给NIC。注意,CPU被完全绕过,可以去处理其他任务,从而加速了整个数据流水线。这个机制对于高性能训练和推理来说,是必不可少的。
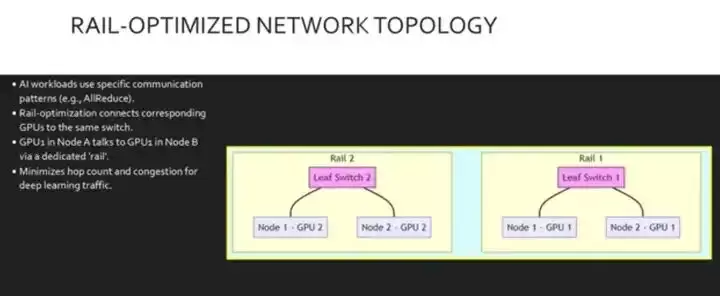
拓扑结构也很关键。AI集群通常会采用“轨道优化”设计,而不是标准的叶脊式配置。在深度学习中,像AllReduce这样的操作,需要跨不同节点的特定GPU进行同时通信。在轨道优化拓扑中,我们会确保每个服务器上的GPU 1都连接到同一个叶交换机,从而为该GPU等级创建一条专用“轨道”。
这种设计能保证不同节点中对应GPU之间的流量,通常只需经过零个或极少的额外交换机,从而显著降低拥塞和延迟。这张图形象地可视化了两条轨道。左侧的叶交换机1只连接节点1和节点2的GPU 1;叶交换机2则只连接节点1和节点2的GPU 2。这种物理隔离意味着GPU 1的流量永远不会和GPU 2的流量争夺带宽。
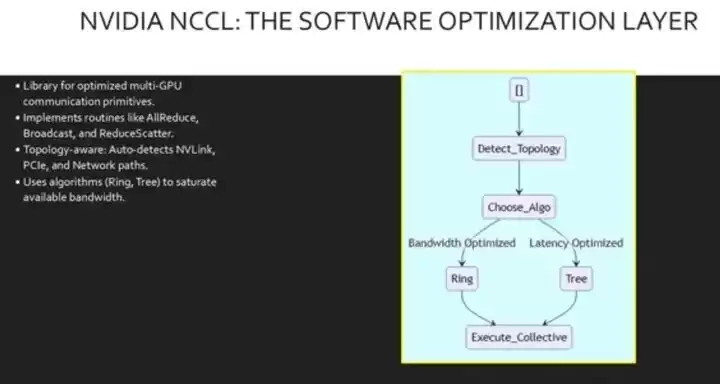
这种并行的高速网络系统,就是轨道优化拓扑结构。硬件有了,还得有软件来驱动。NVIDIA集体通信库(NCCL)就是GPU间通信的标准。它为AllReduce、Broadcast等集体操作提供了优化过的原语,这些操作对深度学习至关重要。
更重要的是,NCCL是“拓扑感知”的。它会自动检测可用的硬件路径——无论是PCIe、NVLink、InfiniBand还是RoCE——并选择最有效的算法(比如环型或树型)来传输数据。这让开发者能够跨节点扩展应用,而无需手动针对特定硬件配置去费劲调整。NCCL会先探测底层拓扑,确定NVLink或InfiniBand是否可用,然后据此选择算法:环型算法通常带宽最优,树型算法则延迟最优。最后,执行具体的集体操作。
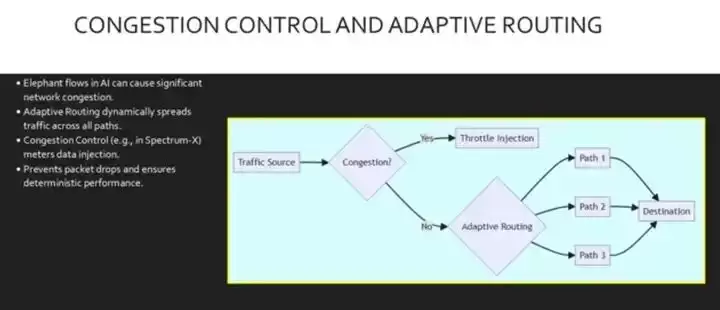
AI工作负载会产生大量数据流,持续时间长且数量庞大,很容易把静态网络路径堵死。自适应路由就是解决这个问题的。与静态哈希和ECMP不同,自适应路由会动态地为每个数据包选择当前拥塞程度最低的路径,从而确保链路利用率的均衡。
此外,NVIDIA Spectrum-X这类技术还实现了细粒度的拥塞控制。通过在网卡级别利用遥测技术来精准控制数据注入速率,可以防止缓冲区溢出和数据包丢失,从而确保AI训练时间可预测的确定性性能。这个流程图展示了实现稳定性的双管齐下方法:首先系统检查拥塞状况,如果检测到流量过大,就在源头限制注入;如果流量正常,自适应路由就会接管,动态地把数据包分发到不同的路径上,避免静态路由造成的热点,确保所有带宽都被有效利用。
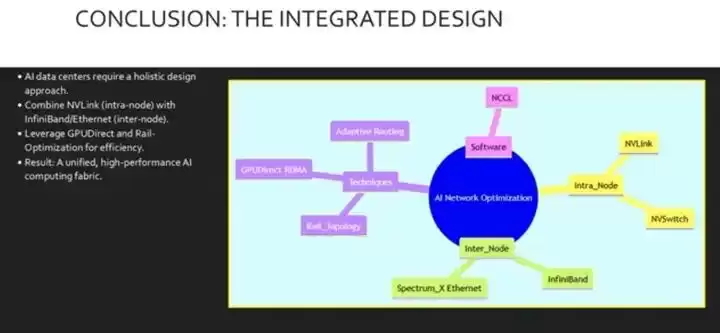
总结一下。优化GPU通信需要一种系统性的方法。它绝不仅仅是换一根线或一台交换机那么简单。它需要将高速的节点内连接(如NVLink)与强大的节点间架构(如InfiniBand或Spectrum-X以太网)结合起来。我们还得利用GPU直接RDMA这样的技术来绕过CPU瓶颈,并设计轨道优化的拓扑结构,让物理布线与逻辑流量模式保持一致。
最后,把这些硬件策略与NCCL这样的软件层集成起来,才能构建出一个统一的高性能架构,高效地训练世界上最先进的AI模型。最终的思维导图很好地总结了这些关键支柱:根基在于AI网络优化;由此延伸出节点内部技术(如NVLink);节点间选项(如InfiniBand);关键技术(如轨道拓扑和GPU直接RDMA);以及最后的软件层——NCCL,将这一切串联起来。理解这些要素如何相互作用,是成功构建AI数据中心的关键。




