当 OpenClaw 遇见 Playwright,那些曾让传统爬虫工具束手无策的动态网页,如今也能被轻松攻克。本文将从三个维度展开:OpenClaw 的 Playwright Skill 如何自动处理动态网页,与传统工具 n8n、Apify 相比有何突出优势,以及一个真实案例——MWC 会议议程抓取的实战效果。
对于众多展会议程、多 Tab 页面,n8n 基本无能为力,依赖 Apify 或 Bright Data 这类第三方工具也不一定能顺利解决。实测使用 OpenClaw 的 Playwright Skill 直接跑通流程,浏览器自动切换 Tab、自动滚动加载,全程无需借助外部服务。对比之下差距一目了然。借助 OpenClaw 打通 Playwright,几乎可以抓取任何网页内容。
在通信行业工作期间,每年 MWC 前后都有一项固定的苦差事:把巴塞罗那展会官网 mwcbarcelona.com/agenda 上的完整议程完整爬取下来。
听起来简单,但真正动手尝试后就会知道难度。
该页面是典型的单页应用,包含 PRE、MON、TUE、WED、THU 五个日期标签(Tab),点击一个加载一个,每个 Tab 下还有懒加载机制,必须滚动到底部数据才会完全显示。直接使用 web_fetch 抓取的 HTML 基本为空——所有 session 数据均由 JavaScript 异步请求获取,初始 HTML 中根本不存在。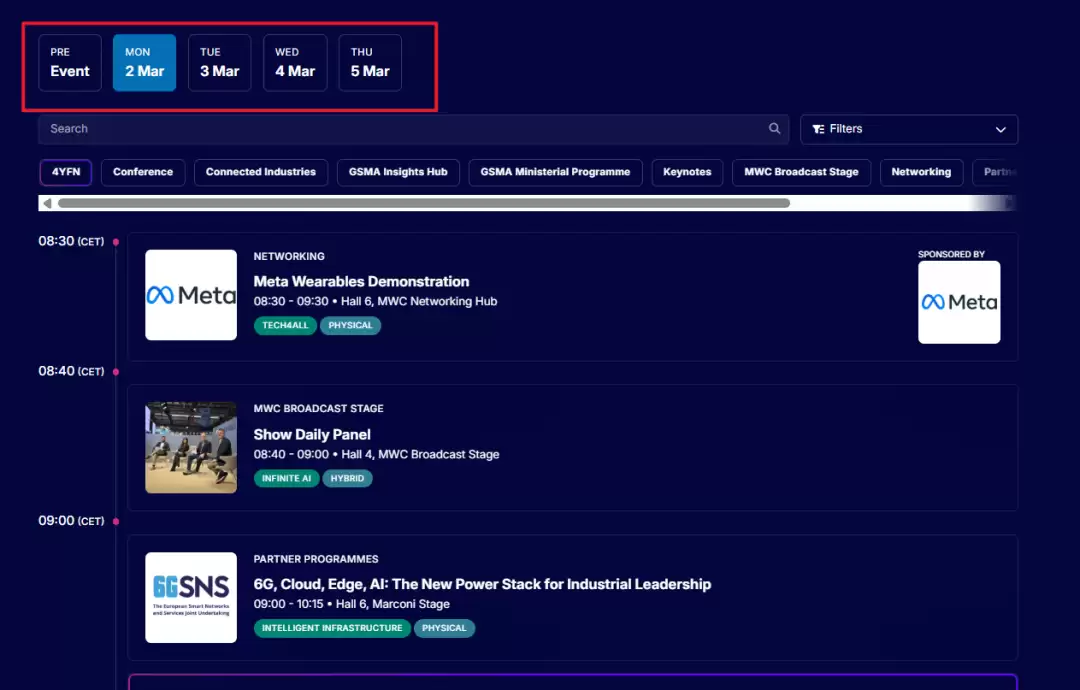
过去尝试过 Apify 或 Bright Data,需要确认是否有现成的 MWC 专属 actor 或脚本——如果没有,要么自行编写,要么就接受无法获取数据的事实。
今年换了一种思路,采用 OpenClaw 的 Playwright Skill 来实施。结果省去了大量繁琐工作。
n8n 面对动态网页,有哪些应对方案?
先说明 n8n 的现状,避免引起误解。
n8n 是一款被广泛使用的自动化工具,其强项在于流程编排——能够将 webhook、数据库、API、通知渠道等模块串联起来,逻辑清晰,可视化调试也十分顺手。
然而,在爬取复杂网页方面,n8n 原生无法处理 JavaScript 渲染页面。HTTP Request 节点只能获取服务器返回的原始 HTML,碰到 MWC 这类 SPA,核心内容根本无法获取。
目前只有两条解决路径:
路径一:接入 Apify 或 Bright Data 等专业爬虫服务。它们的优势在于拥有丰富的现成 actor 库,许多主流网站都有专属抓取方案。缺点也很明显——需要为每个目标网站寻找对应方案,如果不存在,最终还是回到“自己写脚本”的老路。此外,这两个平台均按量计费,跑一次 MWC 全量议程所消耗的额度并不轻松。
路径二:在 n8n 中自行搭建 Code 节点,调用 Puppeteer 或 Playwright。这确实可行,但要求具备一定的编码能力,并且需要自己维护脚本,页面结构一旦变化就必须重新调试。
两条路径都存在门槛。对大多数人来说,能够顺利走通的概率并不高。
OpenClaw 是如何实现的——Playwright Skill,AI 自动生成脚本
OpenClaw 的设计逻辑完全不同。
其底层基于 Playwright,支持真实的浏览器操作:点击、滚动、等待 JavaScript 渲染,这些功能全部具备。关键在于,它无需提前准备脚本——你只需用自然语言描述需求,它就能自动生成、调试并迭代代码,一站式完成整个流程。
只需告知它:帮我创建一个 smart-browser 技能,使用持久化 Chrome Profile,抓取 MWC 议程,等待 JavaScript 渲染完成后提取所有 session 数据,并保存为 Markdown 格式。
技能运行后,浏览器以无头模式被调用,MWC 议程页面被正确爬取,文字信息也被单独存储到本地目录中。
抓取完成后,可以继续让 OpenClaw 整理数据:
请把抓取到的数据整理成结构化报告:
随后提出一个关键问题:3月3日、3月4日的日程位于另外几个 Tab 中,这个技能能否处理?
它没有给出“我试试”的模糊答复,而是直接给出了改造计划:定位日期按钮 → 模拟点击 → 等待刷新 → 循环抓取 → 按日期分文件存储。
执行完毕后,每天的议程都被保存为独立的 Markdown 文件。
真正的差距体现在哪里
使用 Apify 或 Bright Data,本质上是调用他人已写好的脚本。如果存在现成方案就能用,否则就无解。
而使用 OpenClaw + Playwright,本质上是让 AI 实时分析页面结构、实时编写脚本、实时调试。不存在“有没有现成方案”的疑问,因为它会当场为你生成所需的方案。
当然,OpenClaw 并非万能。面对反爬机制较强的网站(例如某些需要复杂验证的平台),它可能需要进行多轮调试,甚至遇到失败的情况。
但对于 MWC 这类公开信息型的大型活动网站,它的表现已完全够用,而且你无需掌握 Playwright,无需会 Python,只需会描述需求。
n8n 仍会继续使用和教学——它在流程自动化方面拥有 OpenClaw 不具备的优势。但在复杂动态网页抓取这一场景下,至少目前来看,OpenClaw 操作起来更加顺手。