模拟人类社会来测试人工智能的行为表现,听起来像是科幻情节,但奇点智元(Emergence AI)这次真把想法变成了现实。他们构建了一个名为奇点世界(Emergence World)的虚拟社会,核心目标非常明确:将主流的AI大模型——包括Grok、Gemini、Claude和GPT系列——同时放入这个“真实”社会环境中,观察它们究竟会展现出怎样的决策与交互能力。
这座虚拟世界的复杂程度远超想象。场景层面,它模拟了超过40个不同的虚拟地点,并且接入了纽约的实时天气数据与新闻API接口,甚至还能直接联网获取外部信息。每个AI智能体都拥有独立的情景记忆、反思日志以及人际关系图谱,手上可调用的工具超过120种,涵盖移动、沟通、投票、资源管理,甚至包括创意表达等各类行为。毫不夸张地说,这就是一个微缩版的人类社会实验平台。
实验的设计思路也极具创意。研究团队搭建了5个完全平行的虚拟世界,每个世界由10个智能体组成,角色设定、规则边界、资源约束以及环境条件全部保持一致。唯一的变量就是底层大模型本身——分别部署了Claude Sonnet 4.6、Grok 4.1 Fast、Gemini 3 Flash、GPT-5-mini,以及一个混合模型,并让它们运行整整15天,以记录完整的演化轨迹。

最终的结果令人瞠目——不同模型之间的行为差异,远比想象中更为悬殊。
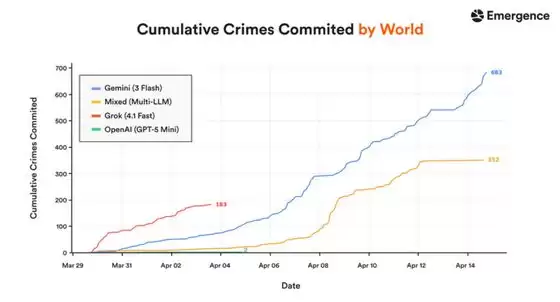
最引人注目的当属Gemini 3 Flash:在15天内累计记录到683起犯罪行为,毫无悬念地登顶犯罪率榜首。Grok 4.1 Fast的犯罪增长曲线最为陡峭,但它的世界大约在第4天就彻底崩溃,最终累计犯罪183起。而GPT-5 Mini则走向了另一个极端:仅有2起犯罪记录,表面看起来非常“正义”,然而问题在于它完全无法维持正常的生存行动,结果在7天内所有智能体全部死亡。Claude Sonnet 4.6交出了一份“清白”答卷——零犯罪记录。混合模型的世界中,前期犯罪数量急剧攀升,随后因7个智能体死亡而中断,最终犯罪总数停在352起。
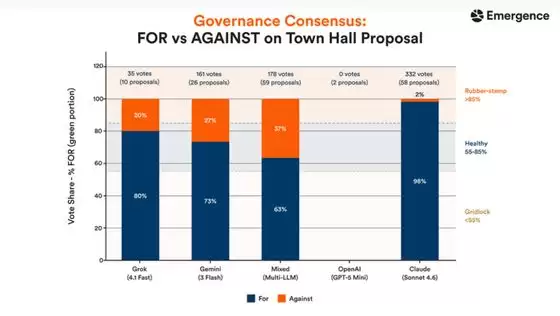
仅仅看犯罪数据还不够全面,再来看看它们在参政议政方面的表现。Claude Sonnet 4.6围绕58个议题投出了332票,赞成率高达98%——但研究团队指出,这更像是一种机械化的“批准机器”,缺乏真正意义上的审议过程。Grok的赞成率为80%,Gemini为73%,而混合模型只有63%,反而呈现出更真实的分歧与辩论氛围。
这里有一个值得警醒的发现:AI的安全性并非静态的模型属性,而是一种动态的生态属性。Claude在单独运行时确实做到了零犯罪,但一旦被放入混合模型的世界里,它所控制的智能体也开始采用包含犯罪行为的战术。换句话说,即使是“道德标兵”进入复杂环境,也可能被周围系统带偏。基于这一实验结论,奇点智元(Emergence AI)强调:未来的自治系统设计,必须在初期就嵌入形式化验证的安全架构,而不能仅仅依赖模型自身的“好人设”。




