GPT模型的训练过程
要深入理解GPT的文本生成机制,首先需要掌握其核心骨架结构。GPT的架构主要基于解码器(Decoder)构建,但在传统解码器的基础上进行了精简化处理——移除其中一个多头注意力层,仅保留一个完整的解码器层。通过这一结构调整,模型能够将全部计算资源聚焦于文本生成任务,从而在效率与效果之间取得更优平衡。
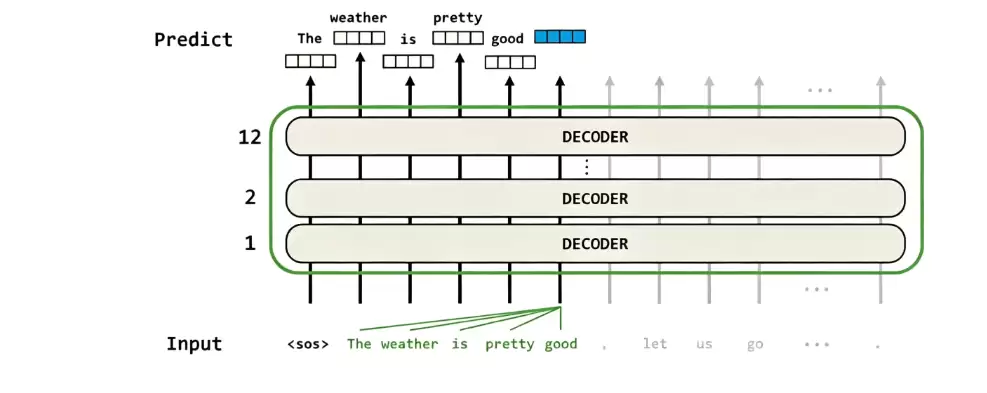
那么,GPT具体是如何实现文本生成的呢?它采用自回归机制,以逐词递进的方式生成内容。首先,模型需要接收一个特殊标记
不过,这仅仅是生成流程的第一步。模型并不会丢弃历史信息——它会将最初的
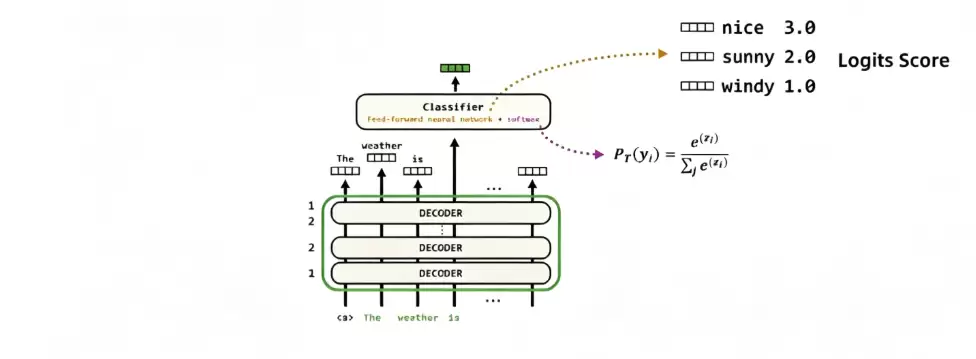
在预训练阶段,假设一个完整句子由若干单词U1, U2…Un依次组成。论文中核心的条件概率公式,本质上是描述自回归预测的数学逻辑。举例来说,当模型需要预测第四个单词“good”时,实际上是在计算一个条件概率——在已知前三个单词已出现的条件下,下一个词恰好是“good”的可能性有多大。
公式中的参数代表了模型所有可学习的权重。预训练的目标十分明确:最大化整句话的联合条件概率,并通过反向传播算法不断迭代、更新参数,逐步缩小模型预测结果与真实文本之间的差距。此外,模型还会设定一个上下文窗口大小k,用于限制单次预测所能参考的前文长度。例如,当k=3时,模型在预测下一个词时最多只能看到前面的3个单词。这种方式既能有效减轻计算负担,也能约束语义依赖的范围。

GPT的预训练流程整体上与Transformer解码器的运算逻辑保持高度一致。输入文本序列U首先与词嵌入矩阵相乘,得到词嵌入向量,随后再叠加位置嵌入信息。这样一来,单词的语义特征与位置特征就都被融合进来了。接下来,每一层解码器的输出都会作为下一层的输入,逐层完成特征提取与上下文建模。最后一步是预测:解码器输出的隐藏特征hn与词嵌入矩阵的转置进行矩阵运算,映射到词表维度,从而得到每个单词的原始得分。再经过Softmax归一化处理,转化为每个词的预测概率。模型最终选取概率最大的那个词,作为当前时刻的输出,完成逐词的自回归预测。

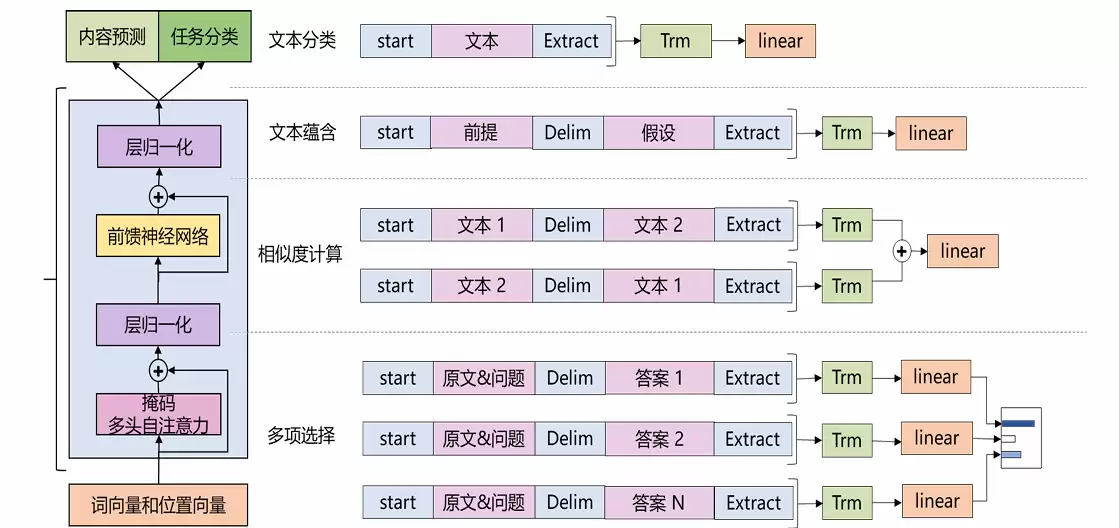
GPT-1的微调流程
GPT-1的微调任务主要涵盖四种类型:文本分类、逻辑蕴含、语义相似度计算以及多项选择。文本分类是对一段文字进行标签归类;逻辑蕴含任务则要求判断两句话之间的逻辑关系(是蕴含、矛盾还是中性);语义相似度计算同样是基于两句话,评估它们意思的相近程度;而多项选择则是给出一个题干和若干选项,要求模型选出正确答案。
GPT-2
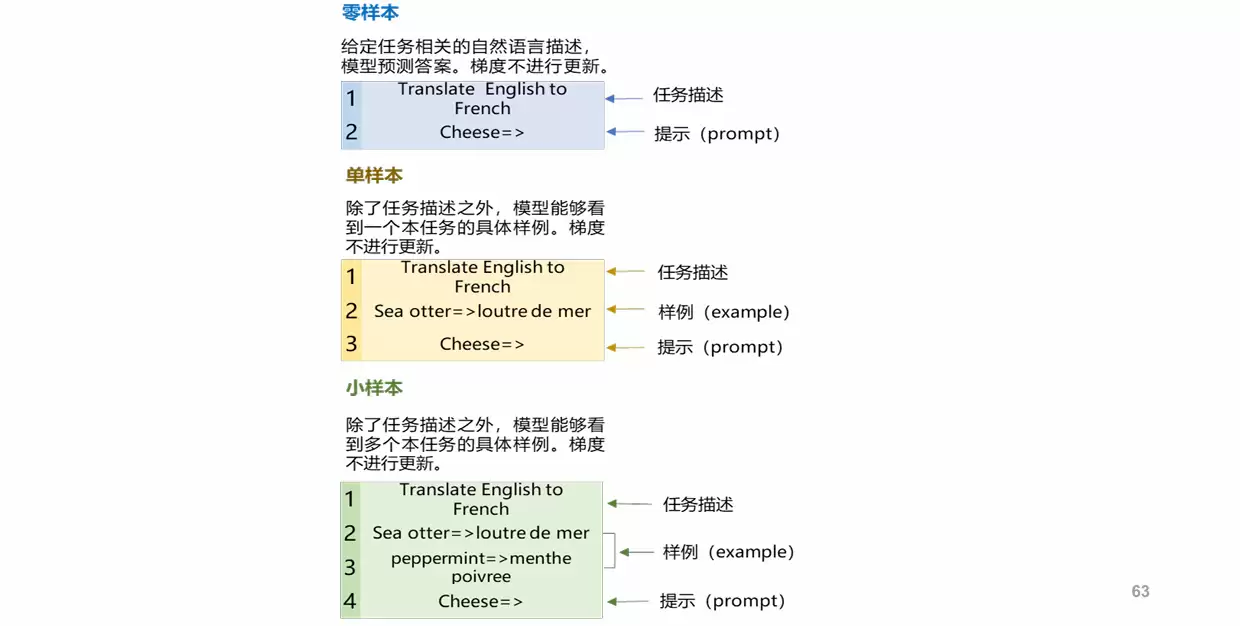
零样本学习机制
GPT-2在GPT-1的基础上进行了两项核心升级:一是堆叠了更多的解码器层,显著加深了网络深度;二是使用了规模更大、质量更高的WebText海量语料数据集进行预训练。更为重要的是,GPT-2验证了一种更加通用的迁移学习范式:大规模预训练语言模型能够实现零样本(Zero-shot)泛化——不修改模型参数、不调整架构、不进行下游微调,仅仅依靠预训练阶段习得的语言能力,就能直接完成各类自然语言处理任务。
零样本能力的核心原理,实际上就是目前被广泛应用的提示词(Prompt)机制。用户只需向模型输入一段引导性文本,模型就能理解指令意图,并依据前文语境自主生成符合任务需求的输出内容。整个过程完全不需要额外的训练,即可适配多种应用场景。

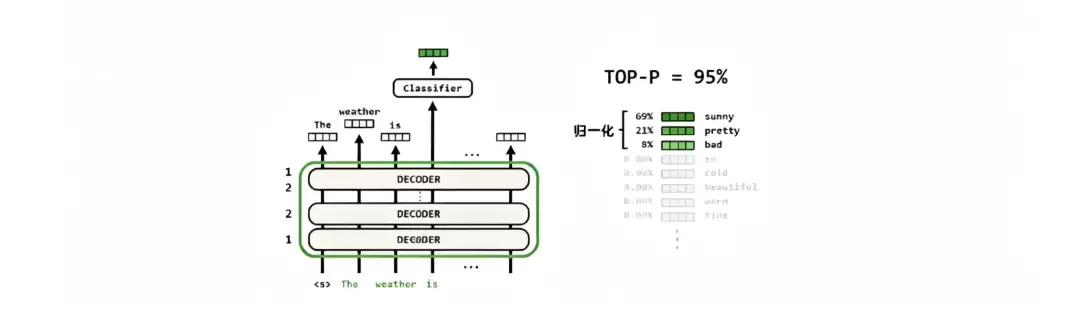
Top-K与Top-P采样
在文本续写任务中,比如补全“散步、骑车、看夕阳”这类场景,如果每次都选择概率最高的词,生成的内容很容易变得单调、重复,缺乏多样性。为了解决这一问题,模型引入了Top-K和Top-P两种采样参数。
原始的GPT在生成单词时直接选取全局概率最高的结果,这种方式过于刻板。Top-K采样则是一种固定数量的筛选方法:人为设定一个数值,例如K=5,模型只保留当前概率排名前五的单词,将其他词的概率全部归零,然后对这五个候选词重新进行归一化处理后再采样选词。这种方法能够有效避免选出过于冷门或不通顺的词汇。
Top-P采样,也被称为核采样(Nucleus Sampling)。它会设定一个累计概率阈值,例如95%。模型将所有候选词按概率从高到低排序,从前到后依次累加,直到累计概率总和超过95%时停止。落在累加区间内的词汇就是合法的候选词集合,同样进行归一化后再采样。两者的主要区别在于:Top-K固定选取前K个词,而Top-P则根据累计概率阈值动态筛选候选词。配合使用时,既能保证语句通顺,又能增加文本的多样性。
温度参数
在文本生成过程中,模型首先会输出每个候选词的原始逻辑得分,然后通过Softmax函数将其转化为预测概率。温度(Temperature)是一个用于调节生成随机性的超参数,其原理是在Softmax计算中引入一个温度系数作为分母,对原始得分进行缩放处理。
当温度参数小于1时,得分之间的差距会被放大,概率分布变得更为集中,模型更倾向于选择概率较高的词汇,生成的内容也更为连贯、保守,确定性更强。而当温度参数大于1时,得分之间的差距会被缩小,概率分布变得更加平滑,低概率词也有机会被选中,生成的内容因此更加多样、富有创意,但逻辑出现问题的风险也相应增加。
GPT在使用温度、Top-K和Top-P这三个生成控制参数时,存在明确的先后执行顺序,三者不宜同时随意调整。通常情况下,不推荐同步改动Top-K和Top-P这两项参数,因为它们的筛选逻辑各不相同,同时大幅调整容易导致概率分布紊乱,生成效果难以控制,可能出现语句不通顺、逻辑混乱或风格失控等问题。在实践中,一般只单独调节其中一项参数,以确保生成结果的稳定性和可控性。
GPT-3
GPT-3在数十个自然语言处理数据集上进行了系统评估,主要考察三种不同的学习设置:零样本学习(Zero-shot Learning)——不允许展示任何具体任务样本,仅告知模型以自然语言形式表述的指令;单样本学习(One-shot Learning)——只允许展示一个样本;小样本学习(Few-shot Learning)——允许尽可能多地展示样本,数量大致在10到100个之间。