YOLOv2网络架构详解:Darknet-19与多尺度训练策略
YOLOv2选择Darknet-19作为主干特征提取网络,这一设计背后有精妙的考量。与YOLOv1不同,Darknet-19彻底舍弃了7×7大尺寸卷积核,仅采用1×1和3×3两种小卷积核。原因很直观:一个7×7卷积核需要49个参数,而用三个3×3卷积核堆叠,感受野完全相同,参数却仅需27个。即便是替换5×5卷积核,两个3×3堆叠也能将参数从25降到17。更关键的是,每次卷积后都紧跟批量归一化操作,显著提升了训练稳定性和收敛速度。
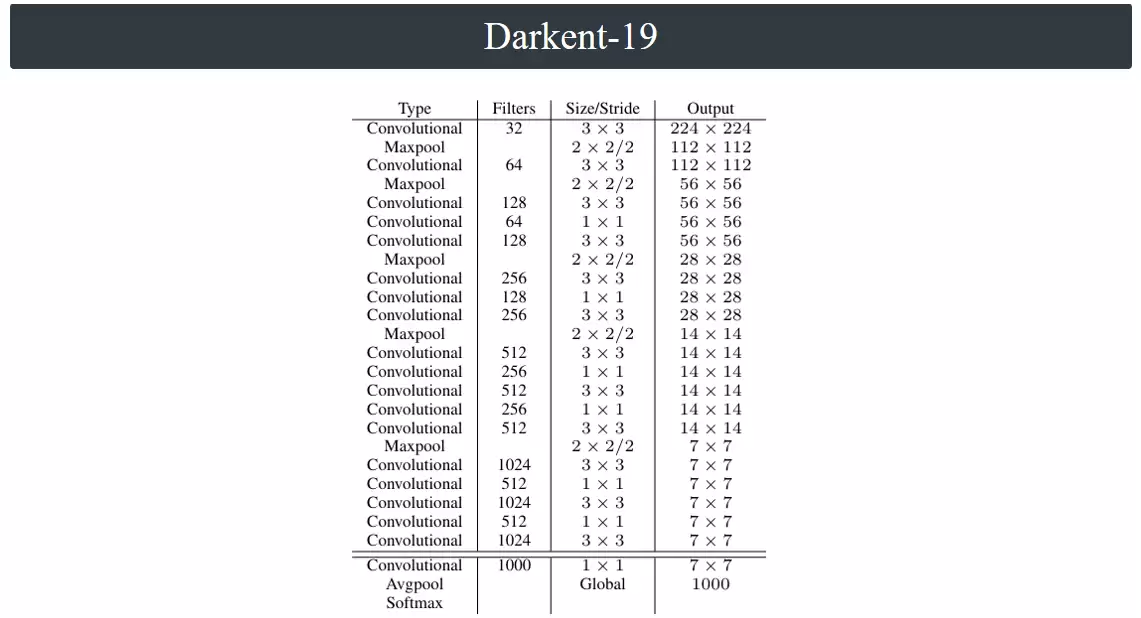
YOLOv1的训练流程是先用224×224的ImageNet数据预训练分类模型,再放大到448×448在检测数据集上微调。YOLOv2延续了“先预训练,再检测微调”的核心思路,但在细节上进一步优化,划分为两个更精细的阶段:
| 阶段 | 输入尺寸 | 数据集 | 目标 |
|---|---|---|---|
| 分类训练阶段(左) | 224×224 | ImageNet | 学习通用图像特征 |
| 检测训练阶段(右) | 448×448 | Pascal VOC 等检测数据集 | 学习目标定位与检测 |
YOLOv2也遵循这一模式,但增加了一个关键步骤:预训练阶段先用224×224训练160个epoch,再用448×448微调10个epoch,最后检测阶段使用416×416(或352/608)的输入,尺寸必须为32的倍数,且每10个批次会随机更换一次尺寸。
| 阶段 | 子步骤 | 输入尺寸 | 数据集 | 关键信息 |
|---|---|---|---|---|
| 预训练阶段 | Train | 224×224 | ImageNet | 160 个 epoch |
| Fine-tune | 448×448 | ImageNet | 10 个 epoch | |
| 检测阶段 | Detection | 416×416(或 352/608) | Pascal VOC & COCO | 尺寸是 32 的倍数,每 10 个批次更换尺寸 |
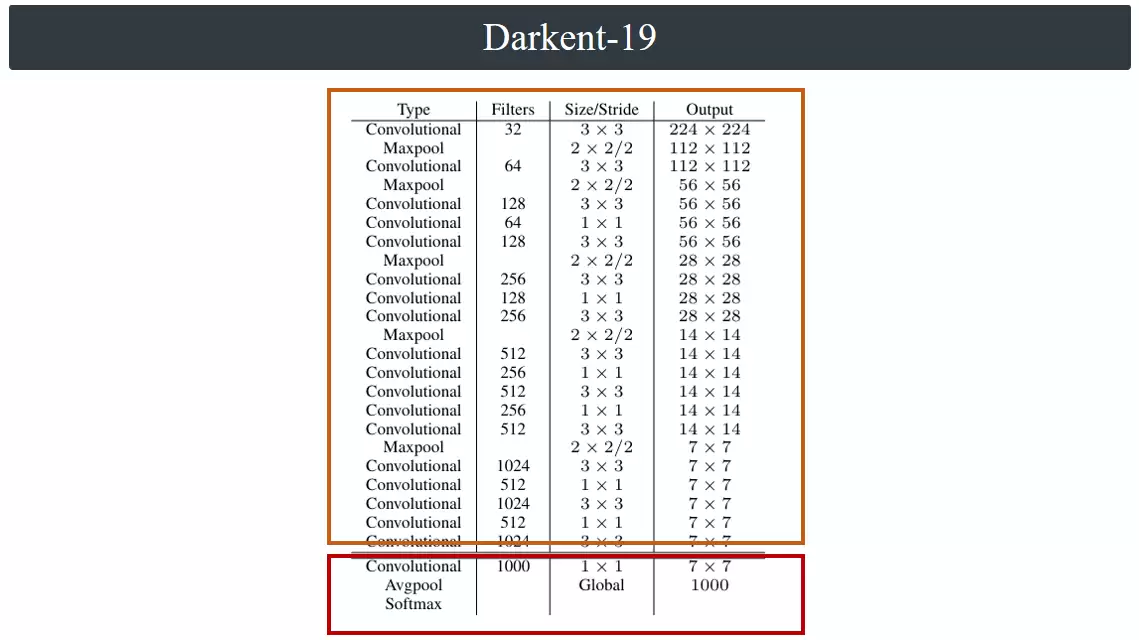
上面这张网络架构图实际上只对应预训练阶段的分类网络。进入检测阶段后,模型后部会被替换,仅保留主干部分作为特征提取器。
实际的YOLOv2检测网络保留了Darknet-19作为骨干,随后堆叠了两个卷积层。为了融合不同层级的特征图,引入了直通层(Passthrough Layer):将骨干网络第5组卷积层输出的高分辨率浅层特征(26×26×512),通过空间到深度(Space-to-Depth)重排后,再与网络尾部卷积层输出的低分辨率深层特征(13×13×1024)进行通道拼接。最终经过两个卷积层直接输出检测结果。这种特征融合设计使模型能够同时利用浅层的细粒度位置信息与深层的抽象语义信息,对小目标检测能力的提升非常显著。
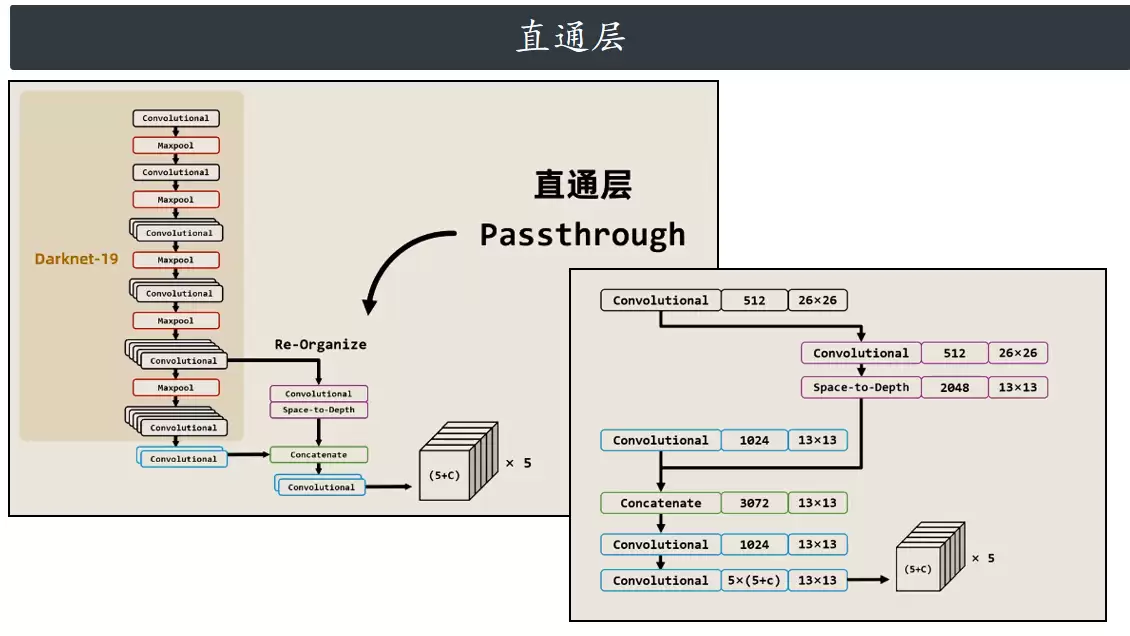
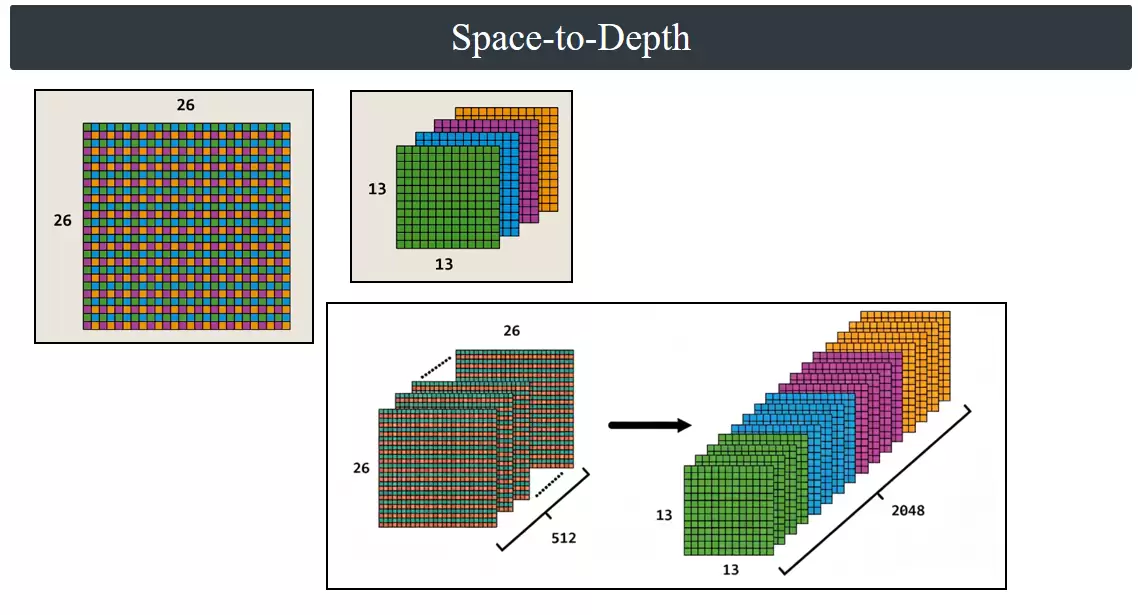
具体操作步骤:以26×26特征图为例,将其左上角的2×2区域划分为四个不同颜色的格子,然后用步长2遍历整个特征图。遍历完成后,将所有相同颜色的格子按通道维度堆叠到一起,原来的26×26特征图就变成了13×13×4的张量——这就是Space-to-Depth重排。在YOLOv2的直通层中,该操作应用于骨干网络输出的512通道26×26特征图,最终得到13×13×2048的张量。然后与网络深层输出的13×13×1024特征进行通道拼接,形成一个13×13×3072的融合特征图。
直通层的本质是将浅层细粒度的位置信息与深层抽象的语义信息有机结合,有效解决了YOLOv1在检测小目标时精度偏低的问题,使模型能够捕捉到更多的物体细节。
锚框机制与位置偏移回归:YOLOv2的边界框预测核心
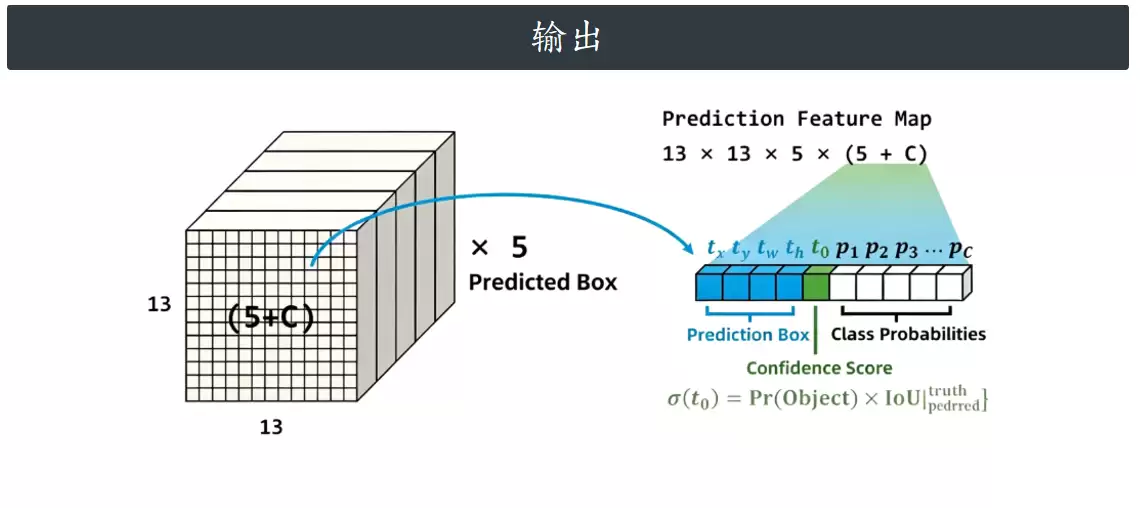
模型最终输出的是一个13×13×5×(5+C)的三维特征矩阵。其中5代表每个网格预设了5组先验锚框,整张特征图被划分为13×13个网格单元,每个网格独立预测5个边界框。每个预测框的输出向量长度为5+C,含义如下:前4个数是边界框的中心偏移量和宽高,第5个数是目标置信度,最后C个数对应各个类别的预测概率。
在后处理阶段,置信度分支的输出需要经过Sigmoid激活函数,映射到0~1之间,才能得到真正有效的置信得分。这一步骤虽然简单,但直接决定了最终检测结果的解码质量与输出精度。
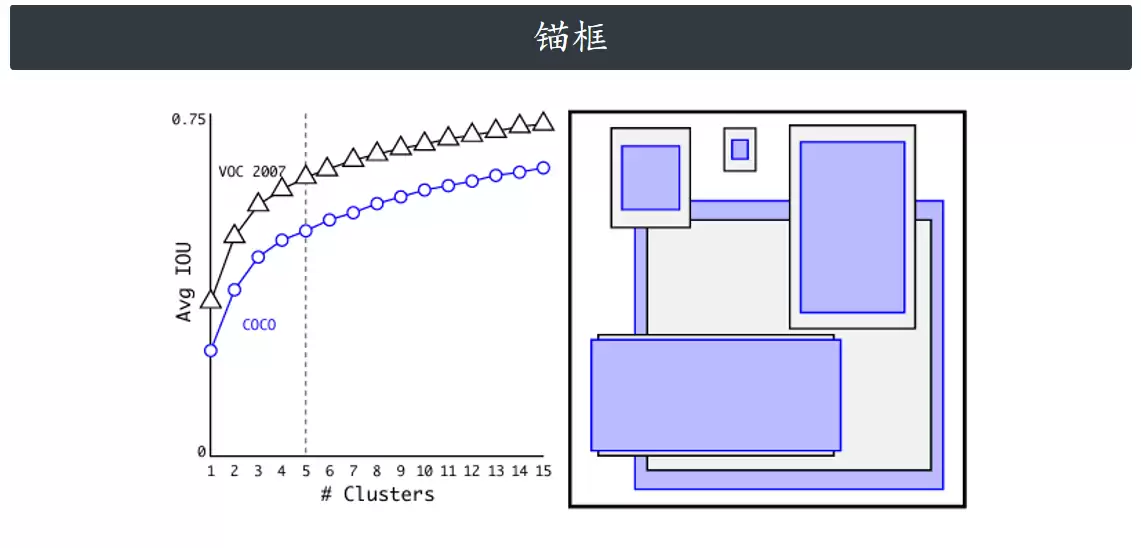
现实场景中的目标物体,外形和尺寸往往具有固定的规律。例如行人通常呈竖向长条状,俯视视角下的车辆则呈现宽矩形。不同类别物体的边界框长宽比和大小都存在明显的共性。如果能够从数据集中归纳出一些具有代表性、普适性强的基准框,让模型以此为参考,就能显著降低学习难度。这些基准框就是锚框(Anchor)。
为了让锚框更适配特定数据集,YOLOv2和YOLOv5不再依靠人工经验手动设定尺寸,而是采用聚类算法对所有真实标注框进行维度聚类分析,自动统计并归纳特征,最终选出5组最具代表性的锚框作为先验基准。这一改进有效提升了边界框回归的精度,使模型能够更快收敛。
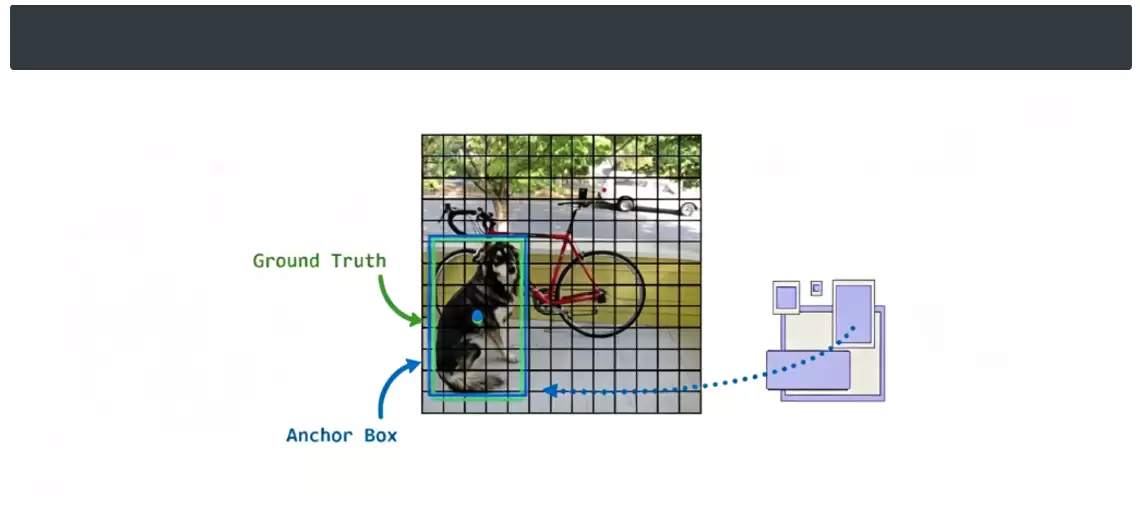
训练时,模型将特征图划分为13×13个网格,每个网格从预设的5组锚框中匹配最优的那一个。具体做法:针对每个真实目标框,计算它和所有候选锚框的IoU,选出IoU最大的锚框作为匹配基准。这个匹配锚框的中心落在对应网格内,然后模型以它为参照,结合预测的边界框参数,计算坐标和宽高的偏移误差,完成回归训练。通过不断修正预测框位置,定位精度逐步提高。
锚框的尺寸是相对于数据集图像的比例尺,具有很强的数据依赖性。因此在训练自己的数据集时,必须根据目标分布定制专属锚框,否则检测效果会大打折扣。
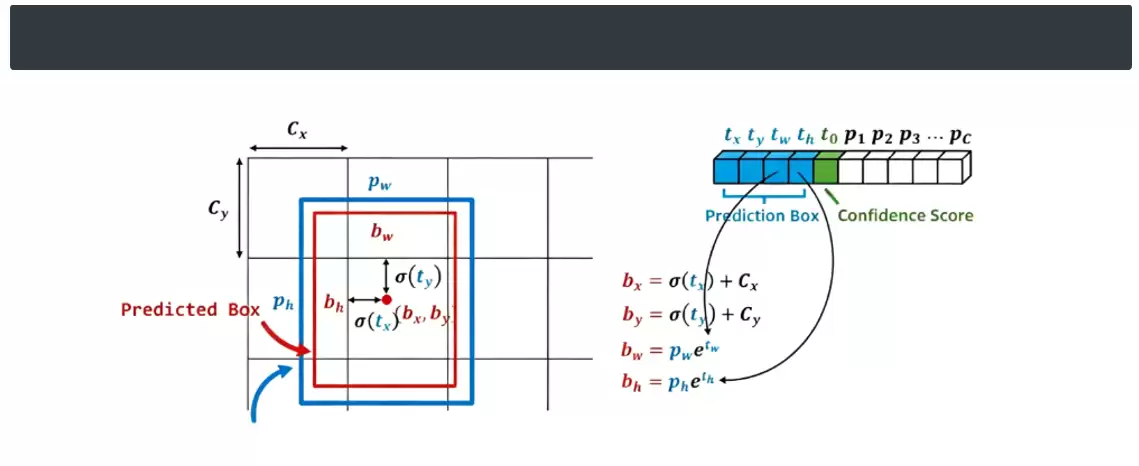
以单个网格为例:假设第二行第二个网格中,红色框是模型输出的预测边界框,蓝色框是匹配的先验锚框。目标中心的偏移由模型直接回归预测得到。训练时,模型以蓝色锚框为基准,结合预测框的坐标、宽高、置信度和类别信息,与真实标注框比对,计算坐标偏差损失、置信度损失和分类损失,通过迭代优化不断逼近真实位置。
总结锚框的核心价值:
- 锚框是基于数据集目标特征预先设定的先验基准框,提前归纳了常见物体的尺寸和长宽比例。
- 为模型提供固定的参考模板,避免网络凭空预测目标尺寸,大幅降低学习难度。
- 模型不需要直接预测完整边界框,只需要以匹配的锚框为基础,微调中心坐标和宽高即可,回归任务显著简化。
- 适配不同形态的检测目标,有效提升定位精度、加快收敛速度,尤其对改善小目标、异形目标的检测效果尤为突出。




