引言:为什么计算机基础常识是程序员的“内功”?
很多编程新手常问:“直接学 Python、Java 写网站不就行了,为什么非要搞懂 CPU 怎么工作、内存怎么分配、网络怎么传输?”答案其实很直白——缺乏计算机基础常识的程序员,好比只会踩油门却不了解汽车原理的司机:能勉强把车开走,可一旦遇到故障就毫无办法,更谈不上发挥整车性能的极限了。
计算机基础常识,覆盖了从硬件到软件、从底层到上层的完整知识体系。只有真正理解这些,你才能写出效率更高的代码,快速定位性能瓶颈,设计出稳定可靠的系统,并在技术面试中游刃有余。这篇文章会从零开始,帮你搭建计算机基础的全局地图。每个知识点都配有清晰的图示、可运行的代码示例、真实场景分析,以及常见误区提醒。读完以后,你的底层认知将超过80%的初学者。
第一章 计算机硬件组成 —— 程序的物理载体
1.1 冯·诺依曼体系结构
现代计算机几乎都遵循冯·诺依曼体系结构,它的核心理念是:存储程序——将程序和数据都以二进制形式存放在同一个存储器里,CPU 从存储器中读取指令并执行。整个体系由五大部件构成:
---------------- -----------------
||| CPU |<---->| 内存 (RAM) |
|| ---------- || (地址 数据) |
||| 控制器 || -----------------
| ---------- |^
|| 运算器 || |
| ---------- |v
|| -----------------
---------------- | 硬盘 (存储) |
|^ -----------------
|^ |
| v
---------------- ----------------
|输入设备 | |输出设备 |
|(键盘/鼠标) | |(显示器) |
---------------- ----------------
- 运算器(ALU):负责算术和逻辑运算
- 控制器(CU):指挥并协调各部件的运行
- 存储器(Memory):存放程序与数据
- 输入设备(Input):如键盘、鼠标等
- 输出设备(Output):如显示器、打印机等
1.2 中央处理器(CPU)—— 程序的大脑
CPU 的核心指标包括主频、核心数、缓存层级。接下来看指令的执行周期——取指、译码、执行、写回。
; 一个简单的汇编指令示例
MOV AL, 61h ; 将十六进制 0x61 移动到 AL 寄存器
ADD AL, 01h ; AL 加 1,结果 0x62,即 ASCII 'b'
从高级代码到机器指令的转换过程,每一步都有迹可循:
// C 代码
int a = 10;
int b = 20;
int c = a + b;
编译后的近似汇编:
mov dword ptr [ebp-4], 10 ; 存储 a
mov dword ptr [ebp-8], 20 ; 存储 b
mov eax, dword ptr [ebp-4] ; 加载 a 到寄存器
add eax, dword ptr [ebp-8] ; 加上 b
mov dword ptr [ebp-12], eax ; 存储结果到 c
CPU 缓存层次:
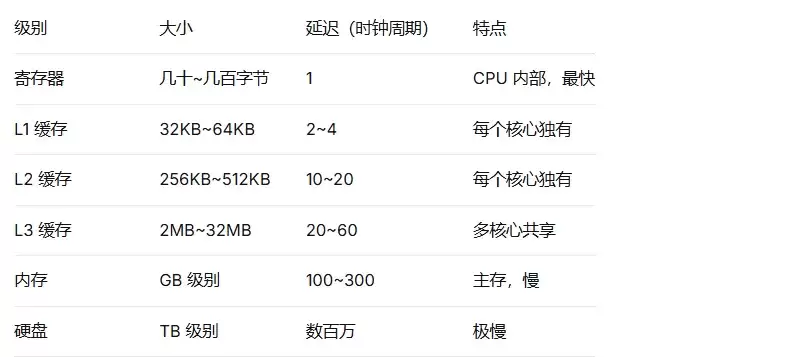
说到缓存,就不得不提起一个经典问题:缓存行与伪共享。下面这个示例演示了两个线程修改相邻变量时,因缓存行失效导致的性能损失:
// 伪共享演示:两个线程修改相邻的变量,导致缓存行失效
public class FalseSharingDemo {
static class SharedData {
volatile long a; // 8 字节
volatile long b; // 8 字节,可能和 a 在同一缓存行
}
static SharedData data = new SharedData();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (long i = 0; i < 1_000_000_000; i++) {
data.a = i;
}
});
Thread t2 = new Thread(() -> {
for (long i = 0; i < 1_000_000_000; i++) {
data.b = i;
}
});
long start = System.nanoTime();
t1.start(); t2.start();
t1.join(); t2.join();
System.out.println("耗时: " + (System.nanoTime() - start) / 1_000_000 + " ms");
}
}
解决方案有两种:使用 @Contended(Java 8+)或手动填充字节实现隔离。
// 通过填充避免伪共享
static class PaddedData {
volatile long a;
long p1, p2, p3, p4, p5, p6, p7; // 填充 56 字节 + 8 字节 a = 64
volatile long b;
}
1.3 内存(RAM)—— 程序的工作台
内存是 CPU 和硬盘之间的缓冲区,断电后数据便会丢失。深入理解内存模型,对于写出高效代码至关重要。
内存地址空间:
// C 语言演示指针和内存地址
#include
int main() {
int x = 42;
int y = 100;
printf("变量 x 的地址: %p, 值: %d", &x, x);
printf("变量 y 的地址: %p, 值: %d", &y, y);
// 指针操作:直接读取内存
int *ptr = &x;
printf("指针 ptr 指向地址 %p, 内容 %d", ptr, *ptr);
*ptr = 99; // 通过指针修改 x
printf("修改后 x = %d", x);
return 0;
}
内存分配区域(以 C 语言为例):
高地址
-------------------------
| 栈 (Stack) | <- 局部变量、函数调用帧,向下增长
| (向下增长) |
-------------------------
| ... |
-------------------------
| 堆 (Heap) | <- 动态分配 (malloc/new),向上增长
| (向上增长) |
-------------------------
| 数据段 (Data) | <- 全局变量、静态变量
-------------------------
| 代码段 (Text) | <- 程序机器指令,只读
-------------------------
低地址
栈溢出示例:
// 递归过深导致栈溢出
int factorial(int n) {
return n == 0 ? 1 : n * factorial(n - 1);
}
// 调用 factorial(100000) 会导致 Segmentation Fault
// 因为每次调用消耗栈空间,超过栈大小限制
堆内存泄漏:
// C 语言忘记释放内存
void leak_memory() {
int *p = (int*)malloc(1024 * sizeof(int));
// 没有 free(p) —— 每次调用泄漏 4KB
}
int main() {
while (1) {
leak_memory(); // 程序内存不断增长,最终耗尽
}
}
Java 内存模型(JMM)—— 并发编程的基础:
// 演示可见性问题(不加 volatile)
public class VisibilityDemo {
private static boolean running = true; // 不加 volatile
public static void main(String[] args) throws InterruptedException {
Thread worker = new Thread(() -> {
int count = 0;
while (running) {
count++;
}
System.out.println("Worker stopped, count=" + count);
});
worker.start();
Thread.sleep(1000);
running = false; // 主线程修改标志
System.out.println("Main set running to false");
worker.join(); // 可能永远不会输出 "Worker stopped"
}
}
// 修复:加上 volatile
private static volatile boolean running = true;
1.4 硬盘(存储)—— 持久化仓库
硬盘分为机械硬盘(HDD)和固态硬盘(SSD)。理解它们的 I/O 特性,对优化数据库性能、文件操作等方面十分关键。
HDD 的寻道时间 vs SSD 的随机读写:
# Python 模拟不同 I/O 模式的性能差异
import time
import os
# 创建一个 100MB 的测试文件
with open('test.bin', 'wb') as f:
f.write(b'0' * 100 * 1024 * 1024)
# 顺序读取 100MB(HDD 和 SSD 都快)
start = time.time()
with open('test.bin', 'rb') as f:
data = f.read()
print(f"顺序读耗时: {time.time() - start:.2f} 秒")
# 随机读取 10000 个位置(HDD 极慢,SSD 依然快)
start = time.time()
import random
with open('test.bin', 'rb') as f:
for _ in range(10000):
f.seek(random.randint(0, 100 * 1024 * 1024))
f.read(1)
print(f"随机读耗时: {time.time() - start:.2f} 秒")
os.remove('test.bin')
内存映射文件(零拷贝技术):
// Java 内存映射文件,利用 OS 的虚拟内存机制
import java.io.RandomAccessFile;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class MmapDemo {
public static void main(String[] args) throws Exception {
RandomAccessFile file = new RandomAccessFile("large.dat", "rw");
FileChannel channel = file.getChannel();
// 映射 1GB 文件到内存(不实际占用物理内存)
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, 1024 * 1024 * 1024);
// 像操作字节数组一样操作文件,操作系统负责异步刷新
buffer.put(0, (byte) 42);
channel.close();
file.close();
}
}




