借助AI为无声视频自动配乐已不稀奇——只需输入画面,模型就能智能生成匹配的背景音效。当效果出色时,甚至让人误以为“原片自带音效”。
然而,挑战也随之浮现:如果模型只会通过画面猜测声音,创作者几乎无法对输出结果进行精准调控。换言之,用户想让画面配上脚步声,模型却偏偏生成风声,而且难以干预修改。
视频音效生成的下一阶段,显然需要从“看画面配声音”升级为“按意图配声音”。这正是小米大模型应用团队近期开源的 ControlFoley 项目的核心价值所在。

三大可控能力,一个模型全搞定
ControlFoley 的定位十分清晰:它不仅是“视频生音频”模型,更是一个面向创作控制的多模态音频生成框架。该框架一次性支持三种不同的任务场景:
- TV2A(文本引导视频配音):结合视频与文字提示生成同步音效,文本用于补充画面本身难以清晰表达的声音语义。
- TC-V2A(文本控制视频配音):即使文字描述与画面提示存在差异,模型也能优先遵循文本意图生成目标声音,同时保持与视频动作的时间同步。
- AC-V2A(参考音频控制视频配音):提供一段参考音频后,模型会模仿其音色与风格进行配音,但节奏由视频画面自主决定,互不干扰。
这意味着用户可根据实际需求灵活选择控制方式——不再是“模型替我做决定”,而是“我明确告诉它我想要什么”。
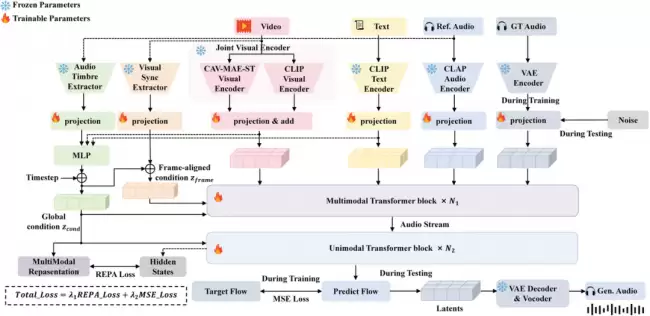
联合视觉编码:既理解画面,也听懂控制意图
在视频音效生成中,视觉信息往往占据主导地位——画面本身就携带强烈的语义提示,容易在多模态融合时压制文本输入。为解决这一问题,团队专门重新设计并自训练了一个全新的时空音视频编码器 CA V-MAE-ST,用于增强模型对动作节奏以及音视频时间对应关系的理解能力。
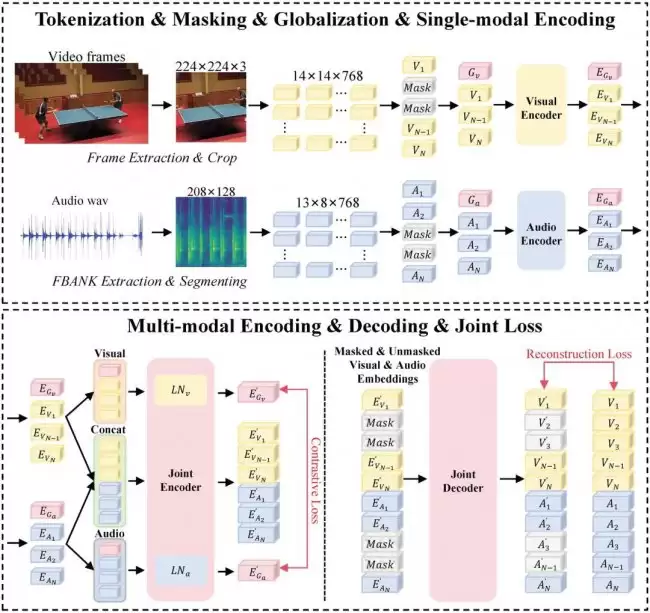
简单来说,CLIP 擅长理解视觉与文本之间的通用语义关系;而 CA V-MAE-ST 则更专注于“动作何时发生、声音何时出现”这类音视频时空匹配问题。两者结合后,ControlFoley 在画面与文本发生冲突时,不会一味被画面牵着走,而是能更有效地执行用户的控制指令。
时间-音色解耦:让参考音频控制风格,而不打乱同步
参考音频控制面临的一大难题是:一段声音既包含“听起来像什么”(音色),也包含“何时发生”(节奏)。如果模型直接照搬参考音频,很容易将其中的时间结构带入结果,反而破坏与视频画面的同步性。
ControlFoley 的解决方案是采用时间-音色解耦策略,抑制参考音频中冗余的时间信息,仅保留关键的全局音色特征。这样一来,声音“像什么”由参考音频决定,声音“何时响起”依然由视频画面主导,两者互不干扰。
模态鲁棒训练:一个模型适配多种输入条件
实际应用场景中,用户提供的条件组合多种多样——有时只有视频,有时有视频加文本,偶尔还会附加参考音频。如果模型仅为单一条件组合优化,换到不同场景就容易表现不稳定。
ControlFoley 通过随机模态 dropout 和统一多模态表示对齐训练,使模型在面对不同输入组合时都能稳定输出。再配合统一的 REPA 对齐目标,确保生成音频的内部表示与多模态条件高度一致,语义对齐效果和控制鲁棒性均获得显著提升。
在常规视频配音任务 TV2A 上,ControlFoley 在 VGGSound-Test、Kling-Audio-Eval、MovieGen-Audio-Bench 等多个 benchmark 中均取得了开源 SOTA 表现。效果对比非常直观——语义对齐、时间同步、声音质量指标全线领先。

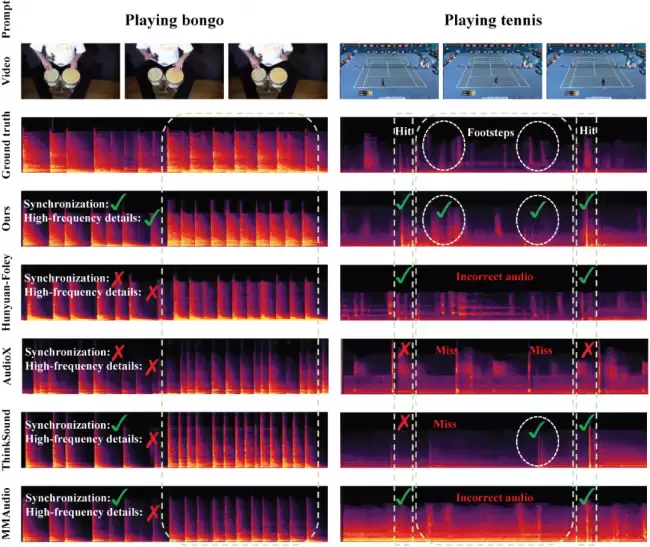
不仅是榜单成绩优异,下图频谱对比也显示:在乐器演奏和体育运动这两类典型场景中,ControlFoley 生成的音频不仅在关键时刻精准对齐视频节奏,还保留了更多高频细节。相比之下,某些方法会出现声音事件错位、漏掉关键动作音效,甚至生成与画面完全不匹配的声音。简而言之,ControlFoley 不仅“配得上声音”,而且配得更准、更精细。
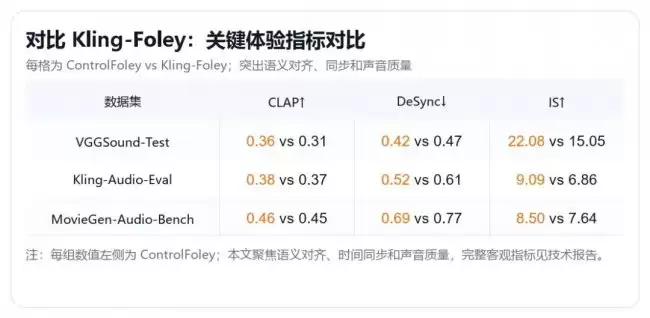
此外,与商业闭源系统 Kling-Foley 的对比同样值得关注——在语义对齐、时间同步和声音质量等关键体验指标上,ControlFoley 展现出稳定的竞争力。完整客观指标可查阅技术报告。