每月《Computer Vision News》都会精选一篇计算机视觉领域的研究成果进行回顾。今年三月,他们选中了由 Yossi Gandelsman、Assaf Shocher 和 Michal Irani 三位学者共同完成的 Double-DIP 模型论文。这篇论文详细介绍了基于耦合的深度图像先验网络,如何对单张图像实现无监督层分割——一个听起来有点玄乎,但实际应用却很扎实的技术。

概况
很多看似不相干的计算机视觉任务,本质上都可以看作是图像被拆分成不同“层”的过程。举个直观的例子:图像分割是把一张图分成前景和背景两层;图像去雾则是把模糊的图拆成清晰层和雾气层。这篇论文提出的思路,正是用一个基于耦合的“深度图像先验”(DIP)网络,把所有这些任务统一到一个无监督的框架下。
深度图像先验(DIP)网络,就是那个被 CVPR 2018 收录的家伙,它是一个天然适合捕捉单张图像低级统计数据的生成结构。最妙的是,它只需要在单张图像上训练就能干活。而这篇论文告诉我们:只要把多个这样的 DIP 网络“耦合”起来,就能变成一个强大的工具,把图像拆解成基本组成成分,然后适配各种任务。为什么这么灵?因为混合层内部的数据,比它各个组成部分的数据更复杂、更有代表性——这就是多功能性的底气。三位作者坚信:多种层的内部统计特性,比各自分开时更鲁棒,表征能力也更强。
方法在实际任务中跑了一圈:水印去除、前背景分割、图像去雾、视频透明度分离,统统能搞定。而且不需要额外数据,单张图像上训练一次,完事。
关于“图像分割的统一框架”
把原始图像拆分成基本层,再用这些层重新混合回来——这个套路可以重新定义很多任务。看下图就明白了:图像分割、去雾、透明度分离,本质上都是把原图拆成几个基本层,然后再混合。

图1 图像分割的统一框架
这些分割任务的共同点是:每个单独层内部的小块分布,比原始“混合”图像更简单、更均匀。也就是说,每层内部的相似性很强。早有研究证实,自然图像中 5×5、7×7 这样的小图像块统计特征极具重复性——这种强内部重复性正是处理各种视觉任务的利器。
作者的方法巧妙结合了“内部补丁重现”(即小块图像重复出现的特性,无需监督就能干活)和深度学习的力量,搭建了一个基于 DIP 的无监督框架。当 DIP 网络的输入是随机噪声时,它也能学会重建单张图像——而这个重建过程恰好能抓住自然图像的低级统计数据。更厉害的是,这个网络在去噪、超分辨、修复等任务上都能无监督地完成任务。
图像分割基本原理
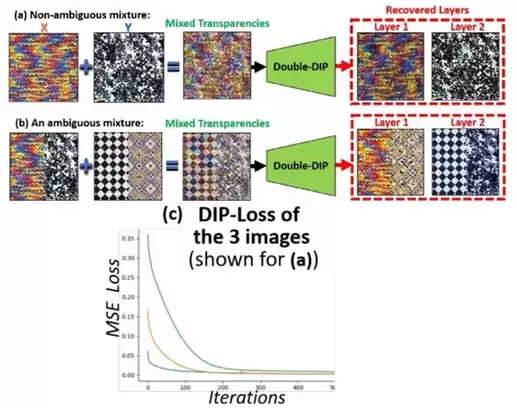
图2 图像分割基本原理
图 2 展示了方法的核心原理:用图案 X 和 Y 混合得到更复杂的图案 Z。每个“纯”图案(X 或 Y)的小图像块分布,都比混合图像 Z 的要简单得多。数学上也很清楚:如果 X 和 Y 是两个独立随机变量,那么 Z = X + Y 的熵大于它们各自的熵。
图 2 的损失函数图展示了单 DIP 网络在训练迭代中的 MSE 重建损失。三条线分别是:(i)橙色——训练重建纹理 X 的 MSE;(ii)蓝色——训练重建纹理 Y 的 MSE;(iii)绿色——训练重建纹理 X+Y 的 MSE。显然,MSE 损失值越大,收敛时间越长。混合图像的 MSE 不仅比两个单独图像大,甚至比它们之和还要大。
这不是偶然现象。作者从 BSD100 数据集中随机挑了 100 对自然图像重复实验,结论一致,而且混合图像与合成图像组的 MSE 差值还更高。
图像分割工作模型

图3 图像分割工作模型
图 3 是 Double-DIP 的工作模型:两个深度图像先验网络(DIP1 和 DIP2)把输入图像分割成对应的图像层 y1 和 y2,然后通过一个二进制掩模 m(x) 重组,让重建图像尽可能接近原始输入 I。
什么样的分割才算“好”?作者提出了三个标准:
- 重新组合时,恢复的图层要能重建输入图像;
- 每层应该尽可能“简单”,即内部自相似性强;
- 恢复的图层之间彼此独立。
这三个标准正是 Double-DIP 要具体实现的。第一个靠最小化重建损失(衡量构造图像和输入图像间的误差);第二个靠引入多个 DIP(每层一个);第三个靠不同 DIP 输出间的“不相容损失”来强制实现——最小化它们的相关性。
每个 DIP 输入随机均匀噪声 z_i,输出图层 y_i = DIP_i(z_i),然后通过权重掩模 m(x) 混合得到重建图像 I_recon,让它尽可能接近输入 I。对于某些任务,掩模 m 可以很简单(比如固定二进制掩模),其他情况则需要用附加 DIP 网络学习。学习的掩模 m 可以是均匀或空间变化、连续或二进制的。对 m 的约束与任务相关,通过任务特定的“正则化损失”强制执行。优化总损失为:
Double-DIP 的训练和优化基本与 DIP 类似。额外添加的非恒定噪声扰动能增加重建稳定性,用 8 个变换(4 个 90° 旋转 + 2 个镜像反射)来扩展训练集。优化用 ADAM,每张图在 Tesla V100 GPU 上只需几分钟。
研究成果
论文里成果不少,这里重点挖两个:前景/背景分割和水印去除。
前景/背景分割
把图像拆成前景层 y1 和背景层 y2,每个像素根据二进制掩模 m(x) 组合。公式很适合这个框架:
这里把“好的图像片段”定义为:容易通过自身合成,但很难用图像其他部分合成的区域。为了使掩模 m(x) 变成二进制,使用正则化损失:

结果相当漂亮:Double-DIP 基于无监督分割就能拿到高质量的分割结果(图 4)。其他很多语义分割方法性能可能更好,但都有一个通病——需要海量数据训练。

图4 图像分割实例
水印去除
水印是保护版权图像的常用手段。Double-DIP 把水印当作图像反射的一种特殊情况来处理:图层 y1 是清理后的图像,y2 是水印。和分割不同,这里的掩模不明确设置,而是用两种实际方案来处理透明层模糊性。如果只有一个水印,用户用边界框标出水印区域;如果有少量(通常 2-3 张)图像带有相同水印,训练中模糊性原则会自行搞定。图 5 展示了几个去除水印的实例。

图5 水印去除实例
结论
Double-DIP 为无监督层分割提供了一个统一的框架,能适配各种任务。除了输入图像或视频之外,它不需要任何额外训练数据。虽然是一个通用方法,但在某些任务(比如去雾)中,它得到的效果可以与领域内最先进的专业技术媲美甚至更好。三位作者认为,用语义/感知线索增强 Double-DIP,说不定能在语义分割和其他高级视觉任务上带来更多突破——他们已经在计划下一步的研究了。




