Opus 4.8 几个百分点背后的野心
时间:2026-05-30 13:05
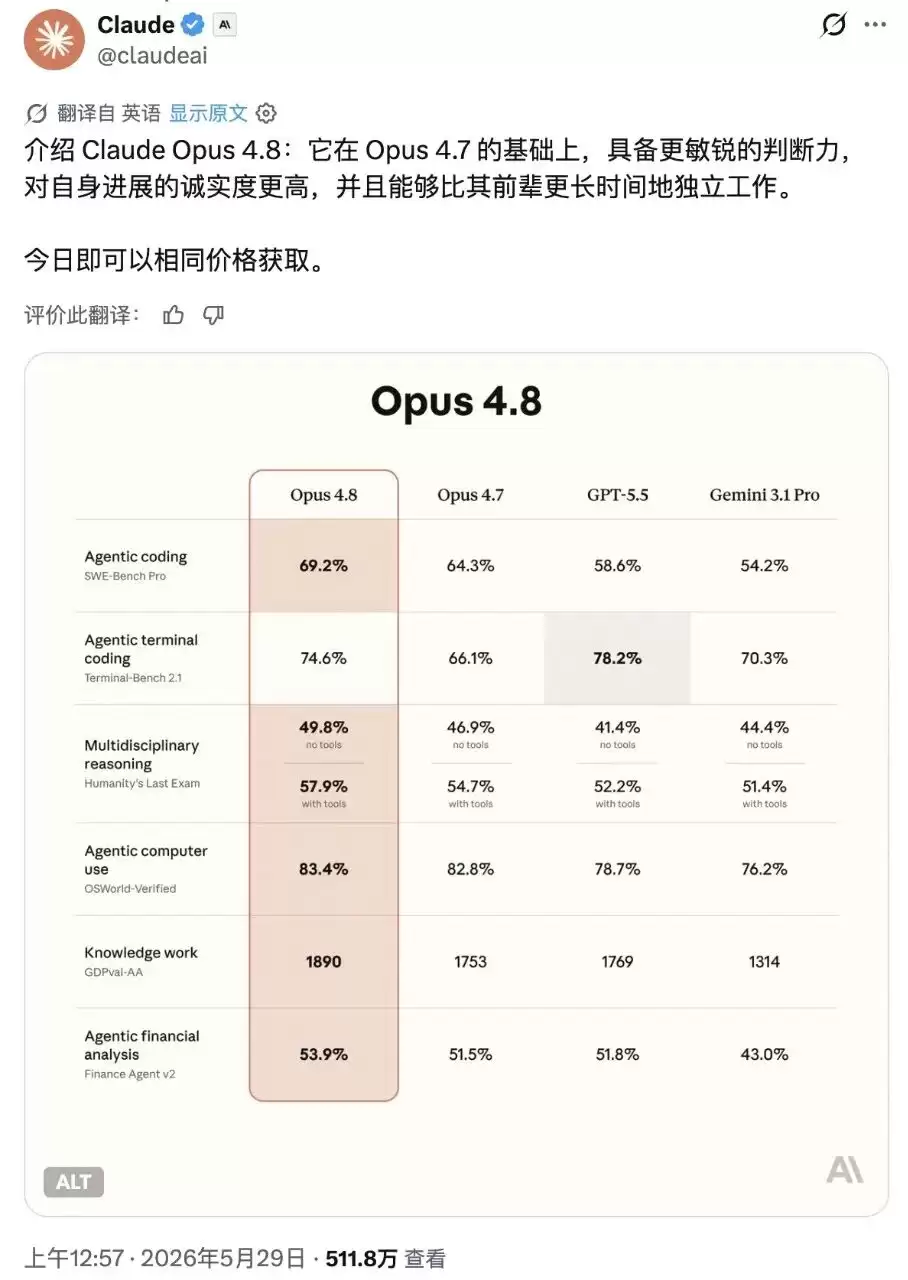
今日凌晨,Anthropic 正式推出了全新旗舰模型 Claude Opus 4 8。 倘若仅从基准测试对比图来看,或许会感到平淡无奇:SWE-Bench Verified 从 64 3 提升至 69 2,OSWorld 从 82 8 升至 83 4,Terminal-Bench 2 1 从 66
今日凌晨,Anthropic 正式推出了全新旗舰模型 Claude Opus 4.8。
倘若仅从基准测试对比图来看,或许会感到平淡无奇:SWE-Bench Verified 从 64.3 提升至 69.2,OSWorld 从 82.8 升至 83.4,Terminal-Bench 2.1 从 66.1 提高到 74.6。区区几个百分点的增长,连热衷博眼球的标题党都提不起兴趣。
社交媒体 X 上最热门的评论之一便是:“这看起来只是一次微不足道的更新?”
但倘若只盯着数字变化,便会错过真正耐人寻味的部分。
41天迭代周期的战略含义
Opus 4.7 于 4 月 17 日发布,而 Opus 4.8 则在 5 月 28 日面世,两者仅相隔 41 天。
值得留意的是,Anthropic 过去旗舰模型的迭代周期通常长达 3 到 7 个月。目前 Sonnet 距上次更新已过去 3 个月,而 Haiku 更是长达 7 个月未获更新。
41 天意味着什么?这绝非从容研究、精雕细琢的节奏,而是竞争对手出牌后必须迅速跟进的紧迫态势。OpenAI 的 Codex、Google 的 Gemini 3.5 Flash 等模型均在近期密集发布,Anthropic 显然无法继续等待。
更具趣味性的背景在于,Opus 4.7 的用户口碑并不尽如人意。Reddit 上有不少用户抱怨其表现反而不及 Opus 4.6,甚至有人直言不再相信基准测试图表。因此,Opus 4.8 的紧急发布,既是对外部竞争压力的回应,也是重塑用户信任的举措。
「诚实」才是此次升级的关键
在众多基准测试数字的背后,Anthropic 隐藏了一项比评分更为关键的提升:诚实(honesty)。
他们专门用一整段篇幅来阐述这一点——Opus 4.8 的核心改进并非「变得更聪明」,而是「变得更诚实」。具体来说:
- 它会更主动地标注自身成果中的不确定因素
- 显著减少缺乏依据的论断
- 相比前代,它在代码中默许缺陷悄无声息通过的几率降低了约 4 倍
在 AI 智能体已开始协助用户执行完整工作流的当下,清楚认知自身未知领域远比盲目宣称无所不知重要得多。回顾那些 AI 智能体误删数据库的新闻——问题通常并非模型不够聪明,而是它缺乏诚实,在不确定时仍强行执行。这一方向的改进,远比 SWE-Bench 上提高两三个百分点更具实际意义。
Dynamic Workflows:被低估的大招
与 Opus 4.8 同步推出的还有一项名为「Dynamic Workflows」的功能(目前处于研究预览阶段)。
简单而言,Claude Code 现在可以在单个会话中并行启动数百个子智能体,分别处理大型任务的不同模块,最后汇总并验证结果。这意味着什么?这意味着 Claude 能够真正执行「代码库级别」的重构任务——例如数十万行代码的迁移,从规划到合并一次完成,并利用现有测试套件作为质量门禁。这已不再仅是聊天机器人的升级,而是工程工具的进化。当模型自身的能力提升遭遇瓶颈时,通过并行架构来弥补单次推理的局限性,无疑是一条明智的路径。
努力程度控制器
另一项虽不显眼却颇具趣味的更新:用户如今可以控制 Claude 投入多少「努力」来回答问题。
- 低努力模式:更快速,节省 token
- 高努力模式(默认):平衡质量与速度
- 超高/最大努力模式:消耗更多 token 以追求更优结果
这实质上将推理深度的选择权交还给了用户。对于简单问题,你无需它思考三分钟;而对于复杂任务,你希望它多花些时间仔细斟酌。这是一个非常实用的改进,尽管看起来不起眼。
Mythos 的影子
最后不得不提的是:Anthropic 在同一篇公告中暗示,更强大的 Mythos 级别模型将在数周内向所有用户开放。这为 Opus 4.8 定下了一个微妙的基调——它并非终点,而是一款过渡性产品。Anthropic 选择将最强的王牌(Mythos)暂时保留,因为网络安全防护措施尚未完善,但相关工作已在加速推进。Opus 4.8 的真正角色可能是:在 Mythos 正式问世之前,稳住旗舰产品的基本盘,避免用户因等待而转向 OpenAI 或 Google。从这个角度理解,41 天的冲刺节奏也就顺理成章了。
写在最后
Opus 4.8 确实并非一个令人惊艳的版本。然而,在几个百分点的基准测试提升之下,隐藏着三个意味深长的信号:
1. 诚实比聪明更为关键——在 AI 智能体时代,自知之明是首要能力
2. 并行成为新的扩展方向——单模型能力天花板逐渐逼近,架构创新开始接力
3. 迭代节奏正在加快——41 天的更新周期,表明 AI 巨头之间的竞争已进入白热化阶段
你说它平平无奇?确实如此。但平静的表面下,格局正在悄然改变。



