如果你最近经常浏览科技新闻或行业报告,大概率会频繁看到“聊天机器人”、“大语言模型(LLM)”和“GPT”这几个词。每周都有新模型发布,这已经不是什么新鲜事。但在这轮AI爆发中,有一个底层技术往往被大众忽略,却扮演着至关重要的角色——没错,就是向量数据库。今天,我们就来聊聊这个看似冷门、实则关键的基础设施。

什么是向量数据库?
要理解向量数据库,得先从“向量嵌入”说起。所谓向量嵌入,本质上是一种数据表示方式,它携带了语义信息,能够帮助AI系统更好地理解数据,并且维持长期记忆。你可以把它想象成一种“语义密码”——模型通过这些向量来记住和理解信息。
嵌入由AI模型(比如LLM)生成,包含大量特征,正因为特征太多,它的表示形式变得非常复杂,难以直接管理。这些嵌入实际上是在用不同维度来刻画数据,目的就是让AI模型能够理解数据之间的关系、模式以及那些隐藏在表面之下的结构。
那么问题来了:传统的基于标量的数据库,能搞定向量嵌入吗?答案是否定的。传统数据库根本无法应对这种数据的规模和复杂性。考虑到向量嵌入带来的这些技术挑战,你大概能猜到——我们需要一个专门的数据库。这正是向量数据库登场的理由。
向量数据库针对向量嵌入的独特结构,提供了高度优化的存储和查询能力。它通过比较向量值、寻找彼此之间的相似性,实现了高效搜索、出色的可扩展性以及快速的数据检索。
听起来很美,对吧?看起来终于有个方案能搞定向量嵌入的复杂结构了。但现实是,没那么简单。向量数据库的落地实现,难度相当高。
到目前为止,有能力开发和维护向量数据库的,基本还是那些大型科技公司。毕竟这东西成本高昂,而且要想发挥出高性能,必须把数据库的各项参数校准得恰到好处——这才是真正的技术门槛。
向量数据库是如何工作的?
有了对向量嵌入和数据库的基本概念,我们来拆解一下它的运行机制。
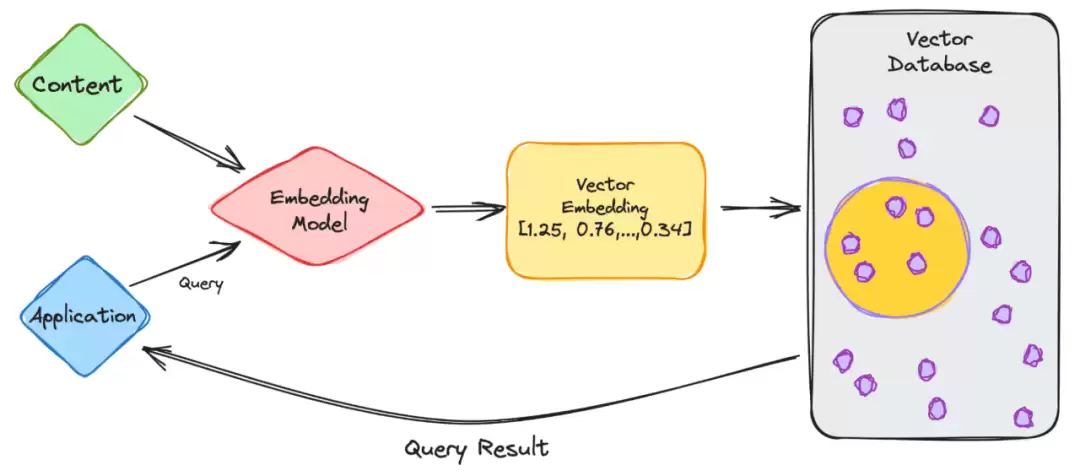
以ChatGPT这类LLM为例,模型本身拥有海量数据,最终呈现给用户的是一个方便使用的应用。整个流程大致分为以下几个步骤:
- 作为用户,你在应用中输入查询请求。
- 你的请求被送入嵌入模型,该模型根据待索引的内容,生成对应的向量嵌入。
- 这些向量嵌入随后被发送到向量数据库中,数据库会结合嵌入所代表的内容进行处理。
- 向量数据库完成计算后,输出查询结果,并将其返回给你。
当你继续发起新的查询时,系统会通过同样的嵌入模型来生成新嵌入,然后到向量数据库中寻找相似的向量嵌入。这些向量嵌入之间的相似度,归根结底取决于生成它们时所使用的原始内容。
想更深入地了解向量数据库的运作方式?我们继续往下看。
传统数据库以行和列的格式存储字符串、数字这类数据。查询时,我们寻找的是与查询条件精确匹配的行。但向量数据库完全不同,它处理的是向量,而非字符串。它还会应用“相似度度量”这一机制,来帮助找到与查询请求最相似的向量。
向量数据库内部集成了多种算法,这些算法共同服务于“近似最近邻搜索”。具体实现路径包括哈希、基于图的搜索或量化等手段,这些算法组合在一个管道中,最终目标是检索出查询向量的“邻居”。
输出的结果质量,取决于与查询向量的接近程度或者说近似程度。因此,准确度和速度是两大核心考量。有一个基本规律:查询速度越慢,结果往往越精准。
向量数据库查询通常经历三个主要阶段:
1. 索引:如同上面提到的流程,一旦向量嵌入进入数据库,系统就会利用各种算法,将这些嵌入映射到特定的数据结构中,目的是为了实现更快速的搜索。
2. 查询:搜索完成后,向量数据库会将查询向量与已索引的向量进行比对,通过应用相似度度量来锁定最近的邻居。
3. 后期处理:根据具体使用的向量数据库类型,系统会对最终找到的最近邻居进行后期处理,生成最终的查询输出。同时,还可能对这些最近邻居重新排序,以便为后续查询提供参考。
总结
随着AI的持续演进,新系统几乎每周都在发布,向量数据库的重要性也在同步增长。正是向量数据库,让企业能够通过精准的相似性搜索,实现更高效的交互,最终为用户提供更优质、更快速的输出体验。
所以,下次你在ChatGPT或Google Bard中输入问题并等待结果时,不妨想一想:在你敲下键盘的瞬间,背后那一整套精密的流程——从嵌入生成到相似度计算——正在毫秒之间完成。这,才是现代AI真正的底层功力所在。