可解释且高效能的图神经加性网络
The Intelligible and Effective Graph Neural Additive Networks
https://arxiv.org/pdf/2406.01317v2


摘要
图神经网络(GNN)已成为处理图结构数据的主流技术。然而,大多数GNN属于黑盒模型,其预测依赖事后解释,这在透明度与公平性要求严苛的领域(例如医疗、金融、司法)远远不够。本文提出的图神经加性网络(GNAN),是对可解释广义加性模型家族的一次重要扩展。它的核心优势在于:设计上天然具备可解释性,用户可以直接可视化并完整理解模型的决策逻辑。无论是分析特征还是图结构,无论是全局还是局部视角,GNAN都能提供清晰的可视化结果,精确描述模型如何利用目标变量、特征和图之间的关系。我们在多个任务和数据集上展示了GNAN的可理解性,同时证明其准确度能够与黑盒GNN相媲美。对于既要透明度又要高精度的关键应用场景,GNAN是一个切实可行的选择。
1 引言
从生物学到欺诈检测,人工智能已广泛渗透到各类图数据应用中。神经网络,尤其是GNN,成为这些领域的主流方法(参见Zhou等人的综述[1])。GNN的预测精度确实出色,但问题在于它通常是一个黑盒——决策过程不透明。透明度至关重要,我们需要评估偏见、安全风险,尤其是在刑事司法、医疗、金融等直接影响人们生活的领域。此时,一个可解释的模型,即使准确度略低,也比复杂的黑盒模型更有价值[2]。此外,自动化决策过程的透明化正成为法律硬性要求。欧盟《通用数据保护条例》(GDPR)是否包含“解释权”尚有争议[3,4],但拟议的《欧洲人工智能法案》已明确指出:“高风险AI系统在投放市场前必须满足透明度要求”[5]。
那么“可解释性”到底是什么?简言之,就是用户能否轻松理解模型为何做出某个决策。需注意,这与“可说明性”并非同一概念[2]。可解释性指模型在设计上就易于理解;可说明性则是事后通过各种方法解释黑盒模型[6]。这些事后解释通常缺乏正确性保证[7,8],可能无法完整描述模型的预测逻辑,甚至无法暴露隐藏的缺陷[9,10,11]。
无论是可说明性还是可解释性,方法都可分为局部和全局两种。局部方法(如SHAP[12]、LIME[13])解释单个预测,全局方法(如特征重要性[14]、部分依赖图[15])揭示整体逻辑[16]。但已有研究发现,局部解释有时会与全局解释相矛盾[17],且仅依赖局部解释来验证公平性并不足够[8]。
本项工作中,我们提出了图神经加性网络(GNAN)——一个兼具透明度和准确度的“玻璃盒”模型[18],能够同时提供局部和全局可解释性。GNAN将广义加性模型(GAMs)[19]扩展到图数据上。GAMs能够拟合复杂的非线性函数,同时保持可解释性,已在多个领域被证明有效[20,21,22,23,24]。其原理是为每个特征学习一个形状函数,然后通过线性组合得到预测——每个特征对预测的影响相互独立,通过观察形状函数即可理解。类似地,GNAN的可解释性源于巧妙的设计:限制了特征与图拓扑的交叉乘积,因此比其他GNN更简单,但请勿低估其能力——我们在多个真实数据集上证明,尽管GNAN容量有限,但其表现可与更强大的GNN相当。此外,GNAN不依赖迭代式的局部消息传递,避免了此类GNN常见的计算瓶颈[25]。
第4节我们将通过一系列例子展示:用户如何解读GNAN,如何精确洞察目标与图、目标与特征、特征与图信息之间的相互作用。在某些情况下,仅用一两张图就能将模型的逻辑解释清楚。我们还将展示GNAN的可解释性如何帮助用户调试模型——这一过程可用于确保一致性并避免偏见。第5节我们将GNAN与其他GNN架构进行性能对比,结果直接表明:为了可理解性而牺牲性能是没有必要的——GNAN的表现与常见黑盒GNN相当。
本项工作的主要贡献包括:
- 将广义加性模型(GAMs)扩展到图数据领域。
- 提出一个专门为图预测任务设计的完全可解释模型,通过模型自身的可视化提供全局和局部洞察,并可用于调试。
- 证明GNAN在常见真实图数据集上性能优异——尽管容量有限,但结果支持一个先前的发现:某些现实世界的图问题其实非常简单,根本不需要其他GNN那么大的容量。
因此,我们认为GNAN因其兼具可解释性和性能,特别适合高风险应用场景。
2 相关工作

广义加性模型(GAMs) 比广义线性模型更灵活,同时保持了可解释性——因为每个预测变量的影响是单独建模的。例如,它可以捕捉特征的非单调效应,这在广义线性模型中不做特征工程是无法实现的。传统上,GAMs使用样条函数或其他平滑函数来建模每个特征与目标之间的非线性关系,也有人采用决策树[24]。最近,Agarwal等人[26]提出用神经网络来学习形状函数,这种方法将深度学习的表示能力与加性模型的可解释性结合在一起。
图神经网络 图神经网络[27,28,29,30]已成为图数据学习的主流。基本思想是利用神经网络将节点特征与图结构结合起来。最常见的是消息传递GNN,通过邻域聚合反复更新节点表示,例如使用类卷积操作或注意力机制[31,32,33]。
此外,也有研究者探索非消息传递的方法,将节点特征与图结构解耦。这类方法已被证明能提升跨不同应用的性能[34,35,36],并且可以减少过拟合——因为流行的GNN确实会纠缠特征和图结构,容易对非信息性的图信息过拟合[37]。GNAN借鉴了这些概念,实现了一个既高性能又完全可解释的模型。
图上的预测任务分为几种类型[38]:图任务预测整个图的属性(例如一个分子图的毒性);节点任务预测图内节点的属性(例如社交网络中用户是真人还是机器人);链接预测任务判断两个节点之间是否存在边。我们本次关注的是图任务和节点任务。链接预测不在当前研究范围内,但可以将其视为对偶线图上的节点任务[39]。
GNN解释 图结构数据的复杂性给可解释性带来了独特挑战。大多数解释黑盒GNN的方法,要么是做事后解释[40,41,42](例如寻找一个子图来解释某个样本),要么是预先调整数据[43,44,45]。举例来说,Ying等人[41]的方法通过最大化预测与子图结构、节点特征分布之间的互信息,来识别重要子图。Yin等人[43]使用预训练的方式学习结构模式。与这些方法不同,GNAN不需要事后解释,也不需要修改数据或训练过程。它是设计上就可解释的——通过学到的形状函数就能精确描述模型逻辑,目标、特征、图之间的关系都能被可视化并传达给用户。
3 图神经加性网络




该数学公式揭示了每个节点和每个特征如何对整体图表示做出贡献。第一个方程说明节点的作用,第二个方程说明所有节点中各个特征的影响。因此,模型可以从多个角度帮助我们理解局部行为。

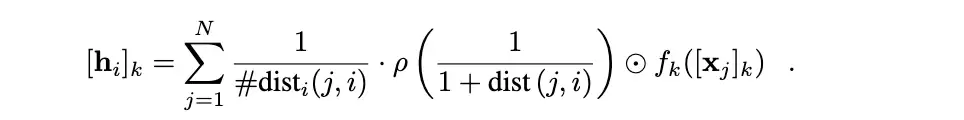
在预测时,求和算子独立地作用于每个类别的维度,并加上softmax作为激活函数。
4 可理解性
本节我们使用可视化来展示GNAN的可理解性。每个GNAN模型的核心是一组单变量学习到的形状函数
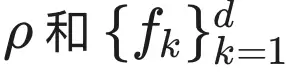
,因此可以将模型绘制成一系列说明性的图表。下面我们展示这类图表的示例,并解释它们如何产生洞察。本节重点讨论全局可解释性,因为局部可解释性也可以用类似方法实现。我们在两个数据集上进行了示范,更多示例见附录。


这里必须强调:图1是完整地展示了整个模型。也就是说,结合偏置项(本例中为-5.6672),你想理解这个模型、想用它来做预测,所有关键信息都包含在这一张图里。这与特征重要性等全局方法完全不同——那些方法只提供一个有限的视角。虽然单张图已提供了完整信息,但有时增加其他视图会更有帮助。


这张热力图显示了特定距离的原子如何影响最终结果。例如,模型已经学到:Ca原子的存在(单元格(Ca, 0))或者它离得近(单元格(Ca, 1))都会增加致突变性。这种可视化还能用于调试。比如,如果已知Ca原子实际上对致突变性有负面影响,用户就能发现并纠正模型的不一致。更进一步,这种细致的理解让用户能够选出一个不仅在给定样本上准确、而且符合先验知识的模型——性能和可靠性都得到保障。
正如Zhang等人[6]所指出的,多类预测任务的解释是一个重大挑战。我们使用PubMed数据集[48]来展示GNAN在多类场景下的表现。该数据集包含19717篇与糖尿病相关的科学出版物(来自PubMed存档),分为三个类别:1型糖尿病、2型糖尿病、妊娠糖尿病。引用网络包含44338条链接。每篇论文作为一个节点,特征是用包含500个独特单词的字典导出的TF/IDF加权词向量。
由于有三个类别,我们训练GNAN时让距离函数和特征函数的输出维度都为3。这样,比较三个类别对应的三个函数就非常有意义,我们将它们绘制在同一张图上[6]。图3显示,模型只利用每个节点的局部邻域,距离越远,信息利用率越低。而且类别之间也存在差异:对于2型糖尿病,距离越长,信息利用率越低(收敛到0),而对于1型糖尿病和妊娠糖尿病,远距离节点反而有负面影响。

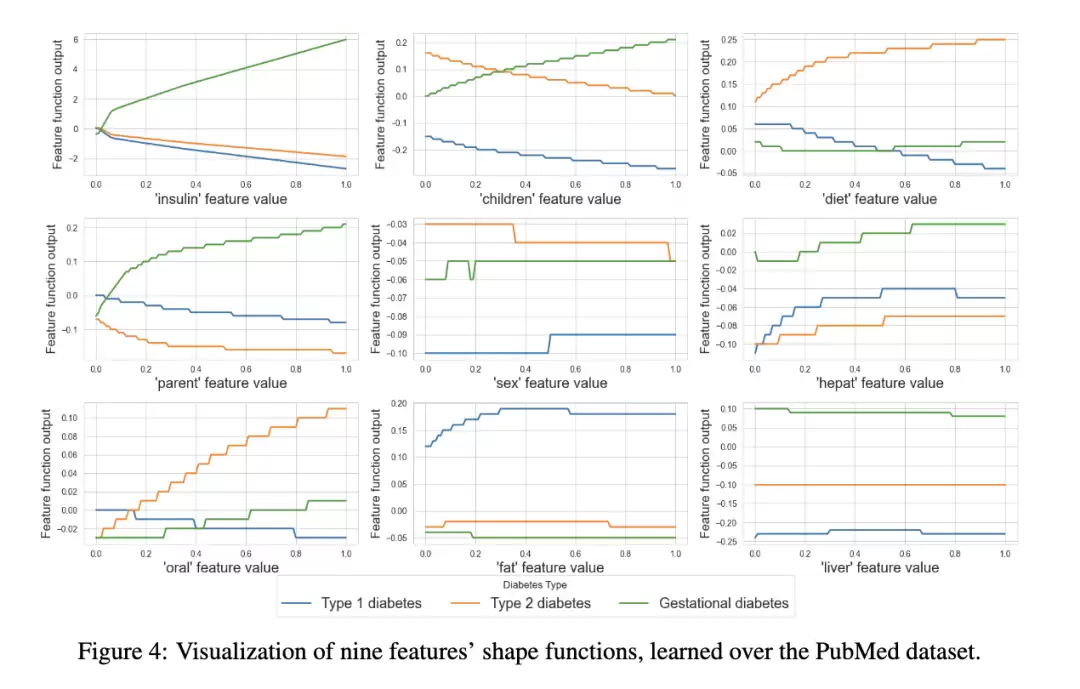
图4展示了九个选定特征的形状函数——这能看出GNAN学习复杂非单调函数的能力,例如“diet”(饮食)和“hepat”(肝脏)这两个特征。同时观察三个类别的形状函数,有助于理解模型如何利用不同特征值来区分类别。举个例子,“insulin”(胰岛素)特征的形状函数揭示:文档中该单词缺失(特征值接近0)并不能明显指示类别;但随着“insulin”出现频率增加,它对预测的影响越来越显著——不过这种影响在1型、2型和妊娠糖尿病之间差异很大。
为了可视化特定距离下特征值的贡献,我们为每个类别绘制热力图——将特征函数在输入范围[0,1]上的输出,乘以对应距离函数的输出。图5以“children”(儿童)特征为例展示了这种方法。观察发现,“children”这个词的存在,对不同糖尿病类型的预测影响差异显著:模型已经学到,关于1型糖尿病的论文很少提及“children”,相关论文也是如此;而妊娠糖尿病的文献中这个词经常出现。更多GNAN可视化示例见附录。

5 实证评估
本节在真实世界的图任务和节点标注任务上评估GNAN,包括大规模、长程和异质性数据集。² 对比的基线是多种常用黑盒GNN:GraphConv[49]、GraphSAGE[30]、图同构网络(GIN)[33]、图注意力网络的表达性版本(GATv2)[29,50]、图变换器(GTransformer)[51],以及将节点特征与图结构解耦的FSGNN[35]。每个基线的超参数调整细节见附录。使用的基准数据集如下:
- 节点标注任务:Cora、Citeseer、PubMed、ogb-arxiv[52,53]是论文引用网络,目标是论文分类。ogb-arxiv是一个大规模网络。Cornell[54]和Tolokers[55]是异质性数据集。Cornell是网页链接网络,节点分为5类。Tolokers基于Toloka众包平台,节点代表参与过至少13个项目的Tolokers,边连接在一起工作过的人,目标是预测哪些Tolokers曾在某个项目中被禁止。节点特征来自个人资料和任务绩效统计。
- 图标注任务:NCI1、Proteins、Mutagen和PTC[56]是化合物数据集,目标是根据某些属性分类化合物。Thr μ, α, αHOM O[57]是长程分子属性预测回归任务,基于大规模QM9分子数据集。
协议:所有任务都使用文献中常用的现有数据划分、协议和评估指标。完整协议见附录。指标方面:Cornell、Cora、Citeseer、PubMed、ogb-arxiv、Mutagenicity、PTC、NCI和Proteins报告准确率;μ, α, αHOM O报告平均绝对误差(MAE);Tolokers报告ROC-AUC。节点标注任务使用预定义划分,结果用5或10个随机种子在测试集上取平均。Proteins和NCI1采用[58]的数据划分和嵌套交叉验证,最终结果是30次运行(10折×3个随机种子)的平均值。NCI1和PTC采用[39]的划分和协议,报告10折嵌套交叉验证的平均准确率和标准差。
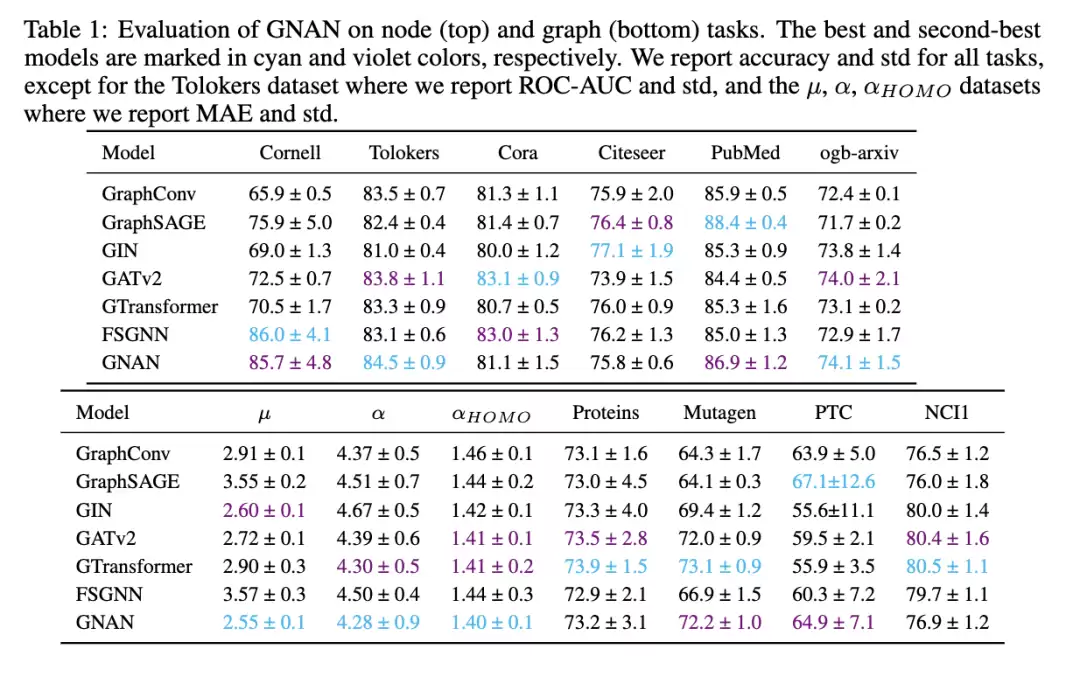
结果:结果见表1。在13个任务中,GNAN在9个任务上取得了最好或次好的结果。请注意,GNAN中每个节点从所有其他节点收集信息,确保完整的信息流动,同时ρ函数根据距离调节影响——这样就避免了某些消息传递GNN的计算瓶颈[25]。特别是在长程任务μ、α、αHOM O上,GNAN超过了所有其他基线,这与Alon和Yahav[25]强调长程信息益处的发现一致。虽然可理解性有时可能会牺牲准确度,但我们的结果表明:增强可理解性并不必然导致准确度大幅下降。尽管容量有限,GNAN却能匹配更具表达力的GNN,这看起来有些出人意料。不过之前的研究[59,58,60]已经指出,即使是容量有限的GNN(例如线性GNN)也能在很多真实数据集上达到高准确度——这说明有些真实的图问题其实比预想的简单。我们的结果再次印证了这一点。
6 结论
本文提出了图神经加性网络(GNAN)——将可解释的广义加性模型扩展到图数据上。GNAN本身具备可解释性,直接从架构中提供全局和局部解释,无需事后解释,显著提升了透明度。与此同时,GNAN的性能与流行GNN不相上下,说明可理解性不一定需要牺牲准确度。
未来有很多方向可以增强GNAN:例如整合最近提出的柯尔莫哥洛夫-阿诺德网络(Kolmogorov–Arnold Networks)[46]来生成更平滑的形状函数;或者为每个特征学习独立的距离函数以增加容量;降低容量方面也值得探索,比如在特征特别多时使用正则化限制形状函数的数量。此外,将GNAN应用于生物网络数据集(如蛋白质相互作用)可能成为支持科学发现的实用工具。这些就留给后续研究。
原文链接:https://arxiv.org/pdf/2406.01317v2




