在RAG(检索增强生成)搜索场景中,当您同时执行两个或更多查询时,必然会面临一个经典难题:每个查询都会生成一份独立的排名结果集,那么该如何将它们整合成一个既能发挥各自优势、又足够可靠的最终答案?此时,倒数排名融合(RRF)便成为了关键解法。
简单来说,RRF是一种精巧的算法,它逐一评估来自不同排名的搜索结果,并将其融合为一个统一的结果集。无论是混合检索,还是并行执行的多个向量查询,RRF都承担着“一锤定音”的聚合职责。
它的核心思路在于利用“倒数排名”这一概念——即搜索结果列表中第一个相关文档排名的倒数。直白地说,RRF关注的是某个文档在各个列表中的排名位置:排得越靠前,它在最终结果中的权重就越高。
RRF算法详解在深入RRF之前,有必要先明确一个关键背景:RAG系统的成败高度依赖于检索阶段的表现。如果检索器未能找到相关文档,后续生成环节的精度将大幅下降,所谓的“幻觉”问题(模型生成不准确甚至荒谬的内容)也会随之加剧。这是所有从业者都希望避免的局面。
实际情况是,不同的查询往往需要匹配不同的检索策略。有些查询,采用基于关键字的检索(如BM25)效果更佳;另一些查询,则依赖基于语言模型嵌入的密集检索(dense retrieval)更为准确。混合检索技术正是为了融合这两种方法的优势,而RRF则是将各路检索模型的排名结果巧妙合并、输出统一排名的聚合利器。
RRF算法原理RRF的工作原理可以分解为以下几个步骤:
- 用户查询:用户输入一个查询。
- 多重检索器:该查询同时被发送给多个检索器,这些检索器可能分别采用不同的模型,例如密集检索、稀疏检索或混合检索。
- 独立排名:每个检索器独立对相关文档进行排名。
- RRF 融合:利用RRF公式,将所有独立排名结果合并起来。
- 生成最终排名:根据计算出的RRF分数,输出一个统一的文档排名。
- 生成答案:生成模型从排名最高的文档中提取信息,生成最终回答。
- 用户查询:用户输入一个查询。
- 多重检索器:该查询同时被发送给多个检索器,这些检索器可能分别采用不同的模型,例如密集检索、稀疏检索或混合检索。
- 独立排名:每个检索器独立对相关文档进行排名。
- RRF 融合:利用RRF公式,将所有独立排名结果合并起来。
- 生成最终排名:根据计算出的RRF分数,输出一个统一的文档排名。
- 生成答案:生成模型从排名最高的文档中提取信息,生成最终回答。


RRF背后的数学直觉RRF的公式看似简单:分数 = 1 / (rank + k)。但这个公式背后蕴含的直觉十分深刻。
- 排名优先的智慧:公式的核心是给排名靠前的文档赋予更高权重。这很符合常识——排名第一的文档,其相关性通常明显高于第二、第三名,因此理应获得更大权重。
- 收益递减规律:分数贡献随排名增大呈非线性递减。这反映了现实情况:排名第1与第2之间的相关性差异,往往远大于排名第100与第101之间的差异。
- 汇聚多方证据:通过对所有检索器的倒数排名求和,RRF能够有效融合多方信息。这就像让一群专家各自投票,再汇总票数做出判断——最终结果通常比任何单一专家的判断更稳健、误差更小。
- 平滑因子k:常数k起到平滑作用,防止任一检索器的排名结果对整个结果形成过度主导,同时能更妥善地处理低排名项目的平局情况。
k 值的选择在实际应用中,k=60是一个非常经典的默认值。这个数值为何被广泛采用?背后有几点考量:
- 实证典范:在多种数据集和检索任务中,k=60均表现出令人满意的效果。
- 平衡的艺术:它很好地平衡了高排名项目与低排名项目之间的影响力。
- 打破僵局:对于低排名项目,k=60能有效解决平局问题。
- 稳定性强:无论面对何种检索系统或数据分布,该值都展现出强大的鲁棒性。
- 排名优先的智慧:公式的核心是给排名靠前的文档赋予更高权重。这很符合常识——排名第一的文档,其相关性通常明显高于第二、第三名,因此理应获得更大权重。
- 收益递减规律:分数贡献随排名增大呈非线性递减。这反映了现实情况:排名第1与第2之间的相关性差异,往往远大于排名第100与第101之间的差异。
- 汇聚多方证据:通过对所有检索器的倒数排名求和,RRF能够有效融合多方信息。这就像让一群专家各自投票,再汇总票数做出判断——最终结果通常比任何单一专家的判断更稳健、误差更小。
- 平滑因子k:常数k起到平滑作用,防止任一检索器的排名结果对整个结果形成过度主导,同时能更妥善地处理低排名项目的平局情况。
k 值的选择在实际应用中,k=60是一个非常经典的默认值。这个数值为何被广泛采用?背后有几点考量:
- 实证典范:在多种数据集和检索任务中,k=60均表现出令人满意的效果。
- 平衡的艺术:它很好地平衡了高排名项目与低排名项目之间的影响力。
- 打破僵局:对于低排名项目,k=60能有效解决平局问题。
- 稳定性强:无论面对何种检索系统或数据分布,该值都展现出强大的鲁棒性。
- 实证典范:在多种数据集和检索任务中,k=60均表现出令人满意的效果。
- 平衡的艺术:它很好地平衡了高排名项目与低排名项目之间的影响力。
- 打破僵局:对于低排名项目,k=60能有效解决平局问题。
- 稳定性强:无论面对何种检索系统或数据分布,该值都展现出强大的鲁棒性。
当然,需要强调的是:虽然k=60是一个得力助手,但最优值始终取决于具体的应用场景和数据特性。如果您的场景比较特殊,可能需要手动调整这个参数,以获得更理想的效果。
RRF的应用在实际的RAG系统中,RRF的代码实现思路非常清晰:score = 0.0
for q in queries: # 遍历发送到不同搜索引擎的查询
if d in result(q):
score += 1.0 / ( k + rank(result(q), d))
return score
# 其中
# k 是排名常数
# q 是查询集合中的某个查询
# d 是q结果集中的某个文档
# result(q) 是q的结果集
# rank(result(q), d) 是文档d在result(q)中的排名(从1开始)
score = 0.0
for q in queries: # 遍历发送到不同搜索引擎的查询
if d in result(q):
score += 1.0 / ( k + rank(result(q), d))
return score
# 其中
# k 是排名常数
# q 是查询集合中的某个查询
# d 是q结果集中的某个文档
# result(q) 是q的结果集
# rank(result(q), d) 是文档d在result(q)中的排名(从1开始)
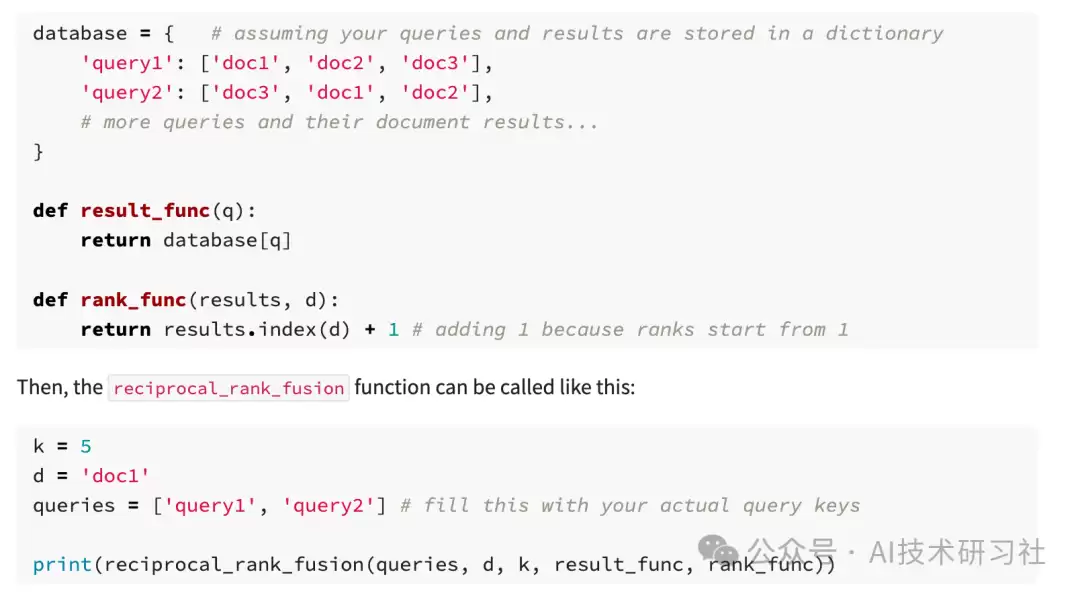
如果用Python,甚至可以写成一行:
def reciprocal_rank_fusion(queries, d, k, result_func, rank_func):
return sum([1.0 / (k + rank_func(result_func(q), d)) if d in result_func(q) else 0 for q in queries])