科学研究正在以前所未有的速度向前推进,这一点已成为广泛共识。然而,与此同时,一个潜在的危机也在悄然加剧——那些至关重要的知识正在不断流失。大量阴性研究结果始终未能公之于众,资深研究员退休时带走的隐性经验无法有效传承,而知识保存工作长期陷入碎片化的困境。这直接导致了科研资源的浪费、重复试错成本居高不下,以及一些可能改变局面的重要发现被无限期延误。
好消息是,科学研究共同体如今已具备采取行动的条件。借助更开放的知识传播渠道、更规范的研究记录与文档体系,以及真正可持续的数字基础设施,构建一套完整的科研知识保存体系并非遥不可及。有人还提出一个更具想象力的场景:阴性结果与实践经验可以在一个受监管的平台上共享,由社区共同制定标准,而AI工具则帮助研究人员降低成本、提升效率。在这一生态中,科学研究不但会更加开放与高效,也将更具韧性——今天产生的智慧,才能真正服务于未来世代。

现代科学研究正在经历一场深刻的转型。实验自动化、高通量技术以及计算能力的爆发式增长,让研究人员能够以前所未有的规模生成实验数据与模拟数据。在生命科学领域,自动化实验平台与高通量测序技术已彻底改变了研究模式,而大型计算模型与AI系统则可以批量输出理论预测,甚至从零开始设计全新的生物系统。
与此同时,跨学科研究已成为主流。如今的科研项目往往需要实验、生物信息学、数学建模、软件工程以及AI方法的协同配合。这意味着,研究数据不仅体量巨大,而且形式更加复杂。多模态、异构化的数据,必须依靠专门的软件、定制化的分析流程以及深厚的领域知识才能得到准确解读。
然而,传统的科研知识保存体系显然未能跟上这一节奏。同行评议论文依然是科学传播的核心形式,但该模式的局限性正日益凸显。论文篇幅有限,实验细节、参数设置、关键排错经验往往很难写入;补充材料与外部链接要么缺失,要么难以持续维护。更不用说,人员的高流动性使得大量隐性知识随着人员离职而彻底消失。
如果不建立全新的知识保存与传播机制,现代科学赖以发展的累积式基础将岌岌可危。因此,构建一种更开放、更可持续、社区驱动的新型科研知识生态系统,已成为当务之急。
科学研究中的“知识流失危机”
首先来看一个最直接的问题:可重复性与可重用性危机。
很多研究虽然发表了论文,但关键信息严重不足。实验条件细节、参数设置、失败经历,以及那些只有操作者才熟知的“小窍门”,几乎从未被系统记录下来。论文相关的数据、代码、元数据、材料与分析流程,往往分散在不同平台,毫无统一标准可言。
长期保存更是困难重重。实验室的冷冻样本可能因设备故障而报废,软件依赖关系随时间的推移不断失效,文件格式持续演变,而项目结束后又普遍缺乏维护资金。跨学科研究中的术语差异,进一步加重了混乱。举个简单的例子:“in vivo”“gene”这类术语,在不同学科语境下的内涵可能完全不同。
科研成果的“可重用性”会随时间推移不断衰减。实验材料可能丢失、污染或标记错误,代码因依赖环境变化而无法运行,文档又不足以支撑新人独立使用。一旦原始研究人员离开,局面便会迅速恶化。
阴性结果被系统性忽视
在整个知识流失问题中,最触目惊心的莫过于对“失败结果”的系统性忽视。
学术出版体系偏爱显著性、创新性与阳性结果,而阴性结果、失败的实验以及未能复现的工作,几乎找不到发表的机会。这种偏差引发了连环恶果:Meta分析被阳性结果偏倚所扭曲,研究人员不断重复别人已经踩过的坑,理论模型建立在片面的数据之上,甚至连AI模型也继承并放大了这种偏差。
但必须强调的是,失败实验本身往往蕴含着极其宝贵的信息。一个实验为什么会失败、哪些条件不可行、哪条理论路线是死胡同——这些经验对后来者而言,是效率最高的教科书。可惜的是,此类知识只存在于研究人员个人的记忆里。
尤其在计算科学领域,隐性知识的流失格外突出。哪些参数组合会导致模型不稳定?哪些计算方法更适合特定类型的数据?如何解释模糊的模型输出?这些难以形式化的知识,恰恰是实际研究中最关键的部分。
现有开放科学体系的进展与局限
不可否认,开放科学体系已取得不少实质性进展。
FAIR原则的推广,有效推动了数据的可发现性、可访问性、可互操作性与可重用性。BioFAIR、CURE等框架也开始尝试构建更规范的数据与模型标准。在生命科学领域,一批专用数据库(如PDB、GenBank、ENA、SynBioHub)已发挥了巨大作用。FASTA、GFF、SBOL等标准文件格式,也显著提升了数据互操作性。
GitHub、GitLab等版本控制系统让计算研究的可重复性得到了质的提升,代码协作与追踪变得透明。Galaxy等工作流平台则让标准化分析流程更加普及。实验领域同样涌现出一批重要平台,比如Addgene用于共享质粒,LabArchives用于记录流程,AiiDA用于追踪复杂工作流,CellRepo和OpenBioSim则开始记录实验lineage与质量标签。
这些系统已充分证明了开放科学的可行性,但彼此割裂、各自为政的问题依然突出。真正统一的生态体系,尚未形成。


建立“失败知识”的共享平台
未来科研必须系统性地保存“科学失败”,这不是一个选项,而是一项基础设施。
目前愿意接收阴性结果的期刊寥寥无几,大量小规模的失败观察根本无法进入传统论文体系。一个更合理的方案是:建立经过适度监管、但不依赖传统同行评议的新平台,专门用于共享阴性结果、失败实验、排错经验、小规模重复以及方法学问题。
这些平台应将发表标准放在方法学合理性上,而非结果是否“新颖”。同时,每个记录都应分配DOI,让失败实验也能成为正式的科研贡献。一旦这种机制运转起来,科学界对“失败”的理解将从根本上发生改变:失败不再是需要被藏起来的东西,而是知识体系中不可分割的一部分。
分布式知识保存体系
建立一个单一的“超级数据库”并非良策,更合理的路径是构建一个联邦式、社区维护的知识网络。未来的知识保存体系,应采用分布式存储、社区协作维护、联邦式平台连接、AI辅助管理的模式。
有人提出了一个很有意思的概念——元数据仓库。它可以连接论文、代码、实验材料、失败结果和各类分析,让科研成果形成一个完整、可检索的知识网络。更有趣的是,他们还以fan fiction社区的标签系统为例,说明社区驱动的标签机制也能帮助科研领域建立更统一、更可搜索的术语体系。这个类比虽然听起来有些跨界,但逻辑是相通的。
个体知识与隐性经验的保存
科研中最有价值的知识,往往恰恰是那些无法被正式表达出来的“隐性知识”。如何调整复杂实验的条件?如何处理特殊的软件环境?有哪些从未被文档化的技巧能显著提高实验成功率?如何根据具体问题灵活调整分析流程?
这些经验无法通过论文完整表达,但它们是科研成功的关键要素。当前学术界长期依赖短期合同和高流动性人才体系,这让知识传承变得极不稳定。一个直接的应对策略是:科研机构应设立更多长期技术岗位,而不是过度依赖短期研究人员。
未来的平台还应支持视频记录、注释协议、交互式教程,甚至由AI自动生成protocol。已有先行者——Cultivarium的PRISM系统可通过头戴设备录制实验过程,并自动生成带注释的视频协议,这为隐性知识的保存打开了一扇窗。
教育、社区与跨学科协作
知识保存不仅仅是技术问题,教育与文化问题同样关键。可重复性应成为科研训练的核心内容,coding groups、hackathons、peer mentoring等协作形式需要被广泛推广。生物学家需要学习AI与软件开发,计算研究人员也必须理解实验背景。只有真正实现跨学科协作,知识保存系统才能有效运转。
workshops、summer schools、社区标准制定、living documentation——这些都将成为未来科研基础设施中不可或缺的部分。
AI在知识保存中的角色
AI在未来知识保存生态中将扮演重要驱动力。它可以自动生成元数据、发现失效链接、更新代码依赖、自动整理文档、提供故障排除建议,甚至帮助研究人员发掘隐藏的阴性结果。
当然,需要清醒认识到:AI只能“增强”人类,不能替代人类。关键决策必须保留人工监督。一个值得期待的正循环是:更好的知识保存会产生更强大的AI,而更强大的AI又会进一步降低知识保存的成本。这种飞轮效应,有望持续推动科学研究效率的提升。
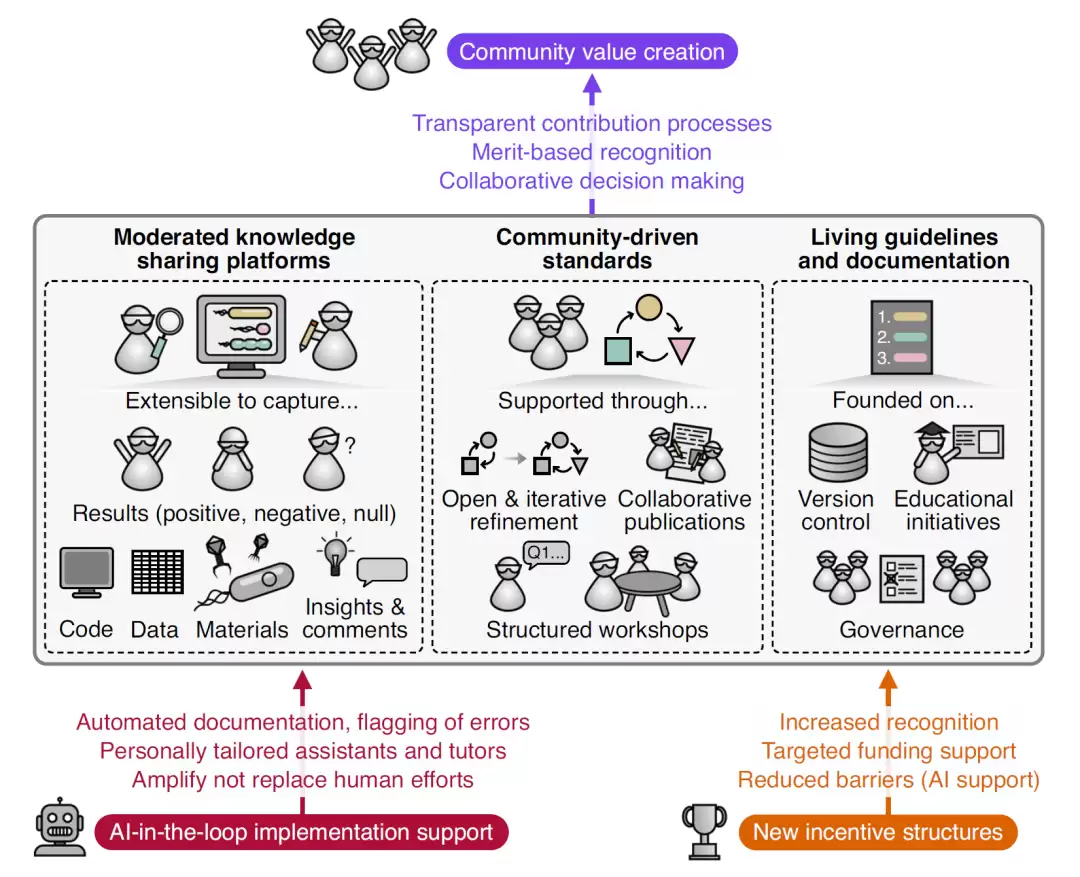
图1. 面向可持续科学研究的知识保存框架,包括社区驱动标准、受监管知识共享平台、AI-in-the-loop 支持体系以及新型激励机制之间的协同关系。
讨论
说到底,未来科研知识保存体系的核心不是技术,而是人。
真正可持续的科研生态,需要机构认可知识保存的贡献,需要基金支持开放科学实践,需要社区建立共享文化,需要AI与人类形成协同关系,更需要科研人员拥有专门的时间来进行知识整理与传承。
这个体系的建成不会是一场革命,而是一连串渐进式改进的累积结果。现有工具、开放科学平台、AI系统和社区标准会逐渐融合,最终构建出一个能够跨越实验、计算与人员经验的“科学知识网络”。在这个网络里,今天产生的科研知识将不再随时间流失,而是持续被连接、解释、重用与扩展——真正成为面向未来世代的可持续科学基础设施。
参考资料
Rainford, P.F., Occhipinti, A., Wang, B. et al. Knowledge preservation in the era of big science and AI: strategies for sustainable scientific research. Nat Commun 17, 4069 (2026). https://doi.org/10.1038/s41467-026-72667-3




