Views are my own.
“Yet Another Chapter”,Generated by Google Lyria
我们来深入探讨这个话题:OpenAI 的一个团队,在短短五个月内借助 Codex 完成了百万行代码的编写,三位工程师平均每天合并 3.5 个 PR,而且所有代码均为 AI 生成,无一行人工手写。Anthropic 推出的 Claude Code 可以连续数日不间断工作,最终构建出一个完整的应用程序。LangChain 的 Coding Agent 在 Terminal Bench 2.0 测试中,得分从 52.8% 跃升至 66.5%,但仔细分析后发现,底层模型并未升级,唯一改变的是 harness 本身。
随着 Coding Agent 的能力在近期急速提升,软件工程师的日常工作也悄然发生了变化:从以往专注于“编写代码”逐步转向“设计一个能让 AI 可靠运行的环境”。
这种设计能力在业界有了一个明确的名字:Harness Engineering。
一、什么是 Harness Engineering?
关于这个定义,Anthropic 在其官方文档中给出了自己的阐述:
Parallel AI 则提供了一个更为详尽的版本:
用通俗的话来说:Harness 就是设计一套系统,让 AI 能够稳定、可靠地完成复杂任务。
从一个简单例子开始
假设你希望 AI Agent 帮助你重构一个包含 10 万行代码的庞大项目。
裸 Agent 的做法是:直接将整个代码库扔给 GPT 5.2 或 Claude 4.6,留下一句“帮我重构”。结果如何?Agent 只看了 1000 行就开始随意修改,3 小时后,整个代码库彻底崩溃。
有了 Harness 的情况则截然不同:
- 首先向 Agent 注入完整的架构文档
- 限制它每次只能修改一个模块
- 强制要求每次修改后必须运行测试
- 一旦检测到测试失败,自动执行回滚
最终,Agent 用了 2 天时间,成功重构了 80% 的代码。
这正是 Harness Engineering 的核心价值:精心设计一个环境,使 AI 能够可靠地完成复杂工作。
核心维度
一个常见的误解是,将 harness 单纯看作“给 LLM 连接工具的胶水层”。实际上,真正的 Harness Engineering 包含三个核心维度:
Context Engineering:提供充分的结构化上下文。不是把所有信息一股脑儿塞给 Agent,而是给它一份清晰的“地图”。例如,OpenAI 的 AGENTS.md 虽然仅有 100 行,但它能够指向并串联起整个知识库。
Tool Engineering:设计受控且高效的工具。不让 Agent 直接操作数据库,而是提供封装好、自带约束的 API。Hightouch 的 Agent 就不能执行任意 SQL,它只能调用预先定义好的查询函数。
Workflow Engineering:构建值得信任的验证循环。不再让 Agent 自己判断“任务是否完成”,而是用外部标准化的流程来验证。LangChain 的 middleware 会强制要求 Agent 在退出前跑完所有测试。
Harness Engineering 要解决的核心问题是:如何让 LLM 在长时间、多步骤的复杂任务中,始终保持一致性和可靠性。
二、Harness Engineering 为什么会出现?
Agent 的核心挑战
当我们说“AI Agent 能够自主完成复杂任务”时,其实隐含了一个前提:Agent 能够在长时间、多步骤的复杂任务中保持一致性。
但这个前提,与 LLM 本身的特性存在根本性的冲突:
LLM 是无状态的。每次推理都是一次独立的函数调用,f(context) → output。而复杂工作恰恰是有状态的,它需要记住“我做了什么”、“为什么这么做”、“下一步该做什么”。
LLM 的模式是 next token prediction,给定 context,预测下一个 token。这个模式从根上就是无状态的。但 Agent 需要完成的是 task completion:记住目标,规划步骤,执行,验证,直到完成。这是地地道道的有状态工作。
Anthropic 用了一个很形象的比喻来描述这个挑战:这就好比一个软件项目由工程师们轮班完成,每个新工程师到岗时,都对上一班发生了什么一无所知。
Harness 的定位,就是在无状态的 LLM 和有状态的任务之间搭建一座桥梁。它的角色,有点像操作系统让无状态的 CPU 能够运行有状态的程序。
Context 的动态性挑战
Agent 现在已经成为主流应用形态,业界也开始意识到:它的主要挑战已经从“能否运行”过渡到了“能否持续可靠地运行”。
LangChain 的 Harrison Chase 在最近的一次 Sequoia Training Data 访谈中,给出了一个非常直白的洞察:
理解这句话,可以设想这样一个场景:当 Agent 需要执行第 14 步操作时,它的 context 取决于前 13 步的任意组合。你根本无法预测它会看到什么,也无法保证它还记得什么。
这与传统软件有本质区别。
传统软件的状态是确定性的:给定相同的输入和初始状态,总能得到相同的输出。但 Agent 的 context 是动态构建的:
- 第 1 步可能调用了工具 A,返回了 100 行数据
- 第 7 步可能基于这些数据做了决策,但只保留了摘要
- 第 14 步的 context 中,可能只剩下“工具 A 返回了客户列表”这样一句描述
Agent 在第 14 步“看到”的世界,是前 13 步任意组合动态构建出来的。这正是 context engineering 成为 Agent 系统核心挑战的根本原因。
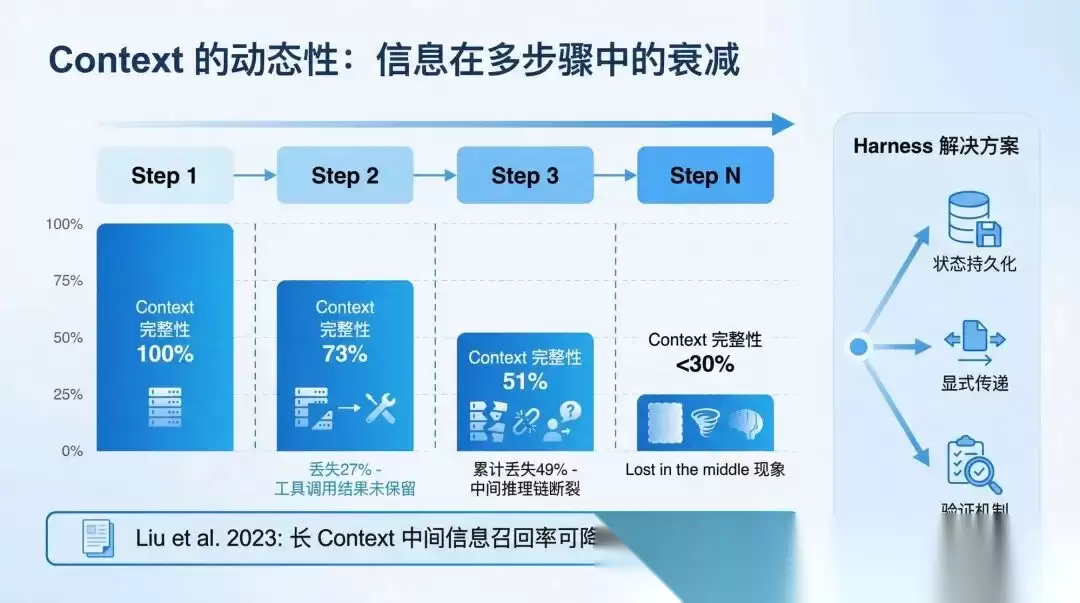
这个挑战在生产环境中,具体体现为三个瓶颈:
瓶颈 1:从“单步智能”到“长时程可靠性”的机制 Gap
各种 Benchmark 刷榜的成绩,很容易制造一个幻觉:模型在单轮任务上的准确率已经很高(>85%),但这完全无法预测它在第 50 步、第 100 步之后的表现。
Durability(持久可靠性)是一个完全独立于 Capability(单步能力)的维度。一个在 MMLU 上能拿 90 分的模型,在执行 100 步的工作流时,完全可能彻底跑偏。
Anthropic 在构建 Claude Code 时,就发现了两种典型的失败模式:
- “All-or-nothing” 模式:Agent 试图一次性完成所有功能,结果导致 context 耗尽。下一个 session 接手时,发现代码写了一半,没有文档,无法继续。
- “过早胜利” 模式:Agent 看到一点进展就宣布任务完成,实际上核心功能还没实现。
这两种失败模式的共同点在于:Agent 缺乏“我在做什么”的持续认知。它在每一个瞬间都很聪明,但时间一长就开始迷失方向,不知道自己该做什么了。
Feature List、Progress Notes、Git Commits 这类机制,就是给 Agent 提供“记忆的外部化存储”,让长时程任务(Long-horizon Tasks)成为可能。
瓶颈 2:Context 爆炸与 Attention 机制的限制
现在的 Agent 应用,动辄需要处理 10 万+ token 的 context。但百万级别的 context window 扩大,并没有从根本上解决问题。Transformer 架构 attention 机制带来的“Lost in the middle”现象,是一个数学上注定的特性。
这就导致了一个很常见的困扰:把 100 页文档全部塞进 context,效果还不如给 Agent 一张 100 行的“地图”,让它按需检索。
OpenAI 的 Codex 团队在构建那个 100 万行代码的 Agent 维护系统时,核心策略就是“渐进式披露”:
- 不是把整个 codebase 塞进 context
- 而是给 Agent 一个
AGENTS.md(仅 100 行),作为稳定的入口点 - Agent 从这张地图出发,再通过工具调用按需检索详细内容
为什么这样更有效?因为每次检索的内容,都落在 attention 的有效范围内,而不是被埋在中间 60% 的 attention sink 里。
文件系统、compaction、动态子 Agent 等机制,把“信息检索”从 Agent 的负担转化成了系统的能力,让 Agent 只看到它需要的信息。
瓶颈 3:从“能跑”到“可维护”的工程化 Gap
OpenAI 的 Codex 团队花了 5 个月,构建了一个 100 万行代码的应用,完全由 AI 生成和维护。但他们遇到的最大挑战,并不是“让 AI 写代码”,而是“让 AI 写的代码可维护”。
他们的核心发现很有启发性:
生产系统对可靠性的要求,远远超出了 benchmark 的评估标准。
Terminal Bench 2.0 的数据也提供了佐证:
- GPT-5.2-Codex 在不同 harness 配置下的分数,从 52.8% 到 66.5%,实现了 26% 的相对提升
- 而模型从 GPT-5.2-Codex 升级到 GPT-5.3-Codex,在 SWE-Bench Pro 上只提升了 0.7%(56.4% → 56.8%)
这说明:当模型能力达到一定水平后,系统设计就成为了效果的主要瓶颈。
LangChain 的实验也证实了这一点。他们的 deepagents-cli 在 Terminal Bench 2.0 上从 52.8% 提升到 66.5%,足足 13.7 个百分点。关键在于:只改了 harness,模型固定使用的是 GPT-5.2-Codex。
使用更大的模型,已经不是性能优化的主要路径了。Harness 的设计,才是决定 Agent 能否在生产环境中可靠工作的最核心因素。
可验证性:Harness 的核心价值
业界主流的 Harness Engineering 实践,都指向了同一个技术原则:
如果你无法验证 Agent 在第 50 步做了什么、为什么做、做得对不对,那么你也无法优化它。
- Anthropic 通过 feature list(200+ 个明确的 pass/fail 标准)+ git commits,让每一步的进展都可验证
- LangChain 通过 middleware 强制验证循环,让 Agent 无法跳过测试就宣布完成
- OpenAI 通过 custom linters + structural tests,把架构约束变成了可以自动检查的规则

Harness Engineering 把“模糊的多步骤工作流”,变成了“可记录、可评分、可结构化的数据”。这让 Agent 系统从一个“黑盒”,进化成了“可观测、可调试、可优化”的工程系统。
三、如何做 Harness Engineering?
Harness Engineering 没有“标准答案”。每个团队都在从零开始构建,根据自己遇到的瓶颈来设计方案。
不过,从现有的业界实践中,还是可以提炼出一些有代表性的方法。
- OpenAI: 信息量超出 context window → 如何让 Agent 按需检索?
- Anthropic: 任务跨多个会话 → 如何让 Agent 记住“我在做什么”?
- LangChain: Agent 不会自我验证 → 如何强制验证循环?
- Hightouch: 任务太复杂 → 如何分解和隔离子任务?
这四种实践,覆盖了大部分生产场景的核心瓶颈。在实际项目中,你的瓶颈可能有多个,需要组合多种方法。理性的做法是:先诊断瓶颈,再选择方案。
案例 1:OpenAI 的渐进式披露 - 解决信息量超出 context window
主要挑战
OpenAI 的 Codex 团队在完成那个 100 万行、无人工参与的代码项目时遇到的问题很典型:Agent 需要理解 100 万行代码,但 context window 只能装下大约 20 万 tokens。
传统的方案是“压缩”(比如 summarization、RAG),但压缩会丢失结构,导致 Agent 搞不清楚信息之间的关系。
解决思路
OpenAI 的核心洞察是:不要压缩信息,而要构建“地图”。
过去常见的做法,是把 100 万行代码压缩成 10 万行摘要。而更好的方案,是给 Agent 一个 100 行的 AGENTS.md(地图),让它按需检索。关键是把“信息检索”从 Agent 的负担,变成系统的能力。Manus、Claude Code 等在上下文管理方面,也有很多非常有效的实战经验。
具体方法
OpenAI 的“渐进式披露”包含四个关键实践:
- 知识库作为目录:
AGENTS.md(100 行)作为稳定入口点,指向编目的设计文档和架构地图,Agent 按需检索。 - 为 Agent 优化代码库:所有关键信息都必须在代码库内可检索,偏好“无聊”的技术,因为更容易建模。
- 强制约束条件而非具体实现:要求 Codex 在边界解析数据,但不规定如何实现。约束的目的是防止架构漂移,而非限制实现方式。
- 自动偏差修复:后台任务定期扫描偏差,自动打开重构 PR。人类的品味被捕捉一次,然后持续执行。
为什么有效?
给 Agent 一张 100 行的地图,再加上按需检索,保证了每次检索的内容都落在高 attention 区域(前 20% 和后 20%),而不是被埋在“注意力黑洞”里。OpenAI 正是用系统架构的改进,来尝试补偿 Transformer 的 attention 衰减。
案例 2: Anthropic 的 Initializer + Coding Agent - 解决跨会话状态丢失
主要挑战
Anthropic 让 Claude 连续工作数天,构建一个完整的 Web 应用。核心问题在于:Agent 必须在多个会话中工作,而每个新会话开始时,它都会“失忆”。
这就导致了之前提到的“All-or-nothing”和“过早胜利”两种失败模式。根本原因很简单:LLM 是无状态的,但复杂工作是有状态的。
解决思路
既然 Agent 无法“记住”,那就让它每次启动时都能“读取记录”。
不要期望 Agent “记住”上次做了什么,而是让它每次启动时都能读取:功能列表(200+ 个 pass/fail 标准)+ git commits(进展记录)+ progress notes(当前状态)。把“记忆”从 Agent 的内部状态,外化为可读取的文件系统。
具体方法
Anthropic 的“Initializer + Coding Agent”是一个两阶段系统:
阶段 1: Initializer Agent — 构建“记忆基础设施”:init.sh(环境初始化)、功能需求文件(200+ 个功能,全部标记为“失败”)、claude-progress.txt(进度追踪)、初始 git 提交。
阶段 2: Coding Agent — 每个会话遵循严格的流程:读取状态 → 做一件事(一次只处理一个功能)→ 验证(端到端测试)→ 记录状态(git commit + 更新 progress notes)。如果写错了代码,下个会话就用 git 回滚。
为什么有效?
这个方法把有状态任务,成功地分解为一系列无状态操作。每个 Coding Agent 会话,都被转换成了一个纯函数:
f(功能列表 + git history + progress notes) → 完成一个功能 + 更新记录
Agent 不需要“记住”,因为所有信息已经在输入里了。Anthropic 用“外部化状态管理”替代了“内部记忆”,这就像操作系统让无状态的 CPU 运行有状态的程序一样。
案例 3:LangChain 的强制验证循环 - 解决 Agent 不会自我验证
主要挑战
LangChain 在 Terminal Bench 2.0 上用同一个模型(GPT-5.2-Codex),只改了 harness,分数就从 52.8% 提升到 66.5%,实现了 26% 的相对提升。
他们当时遇到的问题很普遍:Agent 不会自然地验证自己的工作。比如,Agent 写了代码,重新阅读一遍,确认“看起来没问题”,然后就停了。但实际上,代码根本跑不通。
这是为什么?不是“模型不够聪明”,而是训练数据的偏差所致:LLM 的训练数据主要是“写代码”(来自 GitHub commits),而不是“写代码-测试-修复”的完整循环。模型学会了“生成看起来正确的代码”,但没学会“验证代码是否真的正确”。
解决思路
不依赖 prompt 让 Agent 自己验证,而是用确定性机制强制验证循环。不要在 prompt 里写“记得测试”,因为 Agent 可能会忽略。要在 Agent 退出前用 middleware 拦截它,强制运行验证。把“验证”从 Agent 的自主决策,变成系统的强制流程。
具体方法
LangChain 的“强制验证循环”包含三个关键机制:
- PreCompletionChecklistMiddleware:Agent 准备退出时拦截它,检查是否运行了测试、测试是否通过,用代码逻辑强制执行。
- LocalContextMiddleware:启动时自动映射工作目录、查找可用工具、注入环境信息。Agent 不会主动“探索环境”,Harness 负责准备和交付 context。
- LoopDetectionMiddleware:跟踪每个文件的编辑次数。编辑 N 次后添加上下文,比如:“你已经编辑这个文件 5 次了,考虑重新想想方法。”
为什么有效?
这个方法把“软约束”(prompt)变成了“硬约束”(代码逻辑)。Prompt 的问题是 Agent 可能忽略,而 Middleware 用确定性逻辑保证验证循环,Agent 无法绕过。LangChain 用“系统设计”补偿了“训练数据偏差”——既然 LLM 的训练数据主要是“写代码”而非“写代码-测试-修复”的完整循环,那就把验证从 Agent 的“学习任务”,变成系统的“强制流程”。
案例 4:Hightouch 的动态子 Agent - 解决单个 Agent 处理不了的复杂任务
主要挑战
Hightouch 构建了一个通用营销 Agent,可以规划活动、分析数据、分析创意和文案。他们遇到的核心问题是:单个 Agent 的 context 装不下复杂任务的所有中间步骤。
一个典型的场景是:分析 1000 个客户的购买行为。Agent 需要查询 1000 次(每次 500 tokens),总共 50 万 tokens,远超 context window。强行压缩会丢失细节,只分析部分客户结论又不可靠。
解决思路
Hightouch 的核心洞察是:不要压缩 context,而要隔离 context。
主 Agent 不去处理那 1000 次查询的详细数据,而是生成 1000 个并行的“子 Agent”,每个处理一个客户,生成一份摘要。主 Agent 只看这 1000 份摘要(每个 50 tokens,共 5 万 tokens)。关键是用“分层处理”替代“线性压缩”。
具体方法
Hightouch 的“动态子 Agent”包含四个关键机制:
- 规划与执行分离(动态更新):通过特殊工具调用(
make_plan、execute_step_in_plan、update_plan),Agent 管理自己的思维过程,计划可根据新信息动态更新。 - 文件缓冲:工具返回大量数据时,Agent 调用
write_file缓冲到磁盘,context 中只保留指针(文件名 + 描述)。这就像学生用“草稿纸”一样。 - 动态子 Agent:主 Agent 识别出复杂的子任务,生成独立的 LLM 线程(子 Agent)去处理。子 Agent 完成后生成摘要,只有摘要会返回主 Agent。
- 扇出模式:对于非结构化数据(比如 1000 个客户评论),主 Agent 生成数百个并行调用到小模型(Haiku),每个处理一条评论,由主 Agent 汇总结果。这种方式比 RAG 更便宜、更可靠。
为什么有效?
传统方法的瓶颈在于:单个 Agent 的 context 是固定的,而压缩又会丢失细节。
Hightouch 的方法是:主 Agent 的 context 只存储“地图”(计划 + 摘要),详细信息放在子 Agent 的独立 context 中。这样一来,系统总的“工作记忆”可以远超单个 context window。这就像分布式系统中的“分而治之”:水平扩展 context,局部处理后全局汇总。用“分层抽象”替代“线性压缩”,因为压缩是有损的,而分层抽象可以做到无损——细节在子层,摘要在主层。
如何选择适合你的方案?
核心问题始终是:如何让 LLM 在有限的 context window 内,完成超出 context window 的复杂任务?
上面几种实践的共同策略是:构建一个“信息检索 + 状态管理 + 验证循环”的系统。区别在于侧重点:
- OpenAI 的渐进式披露:重信息检索(
AGENTS.md地图 + 按需检索) - Anthropic 的 Initializer + Coding Agent:重状态管理(git commits + progress notes)
- LangChain 的强制验证循环:重验证(middleware 强制测试)
- Hightouch 的动态子 Agent:三者都重,但用“隔离”而非“压缩”

具体到借鉴策略:先诊断你的瓶颈在哪里,再选择对应的设计思路:
- 信息量超出 context window → 渐进式披露
- 任务跨多个会话 → 外部化状态管理
- Agent 不会自我验证 → 强制验证循环
- 任务太复杂 → 动态子 Agent
实际项目中的瓶颈可能是多个,需要组合多种设计思路。这并非简单的“产品组合”,而是可以在你自己的 harness engineering 中同时实现的设计原则。
四、未来会怎样?
Harness Engineering 目前正处于“百花齐放”的阶段,OpenAI、Anthropic、LangChain、Hightouch 等都在非常积极地探索不同的方向。这些实践背后,有三个相对清晰的演化方向:
趋势 1: 模型与 Harness 的协同演化
一个常见的假设是:更强的模型,意味着更简单的 Harness。但实际情况可能恰恰相反。
OpenAI 的 Codex 团队在五个月内构建了越来越复杂的 harness。LangChain 的 deepagents 自 2024 年 3 月以来被重新架构了五次。生产系统的要求,远超 benchmark 的范畴。
Harness 把“可靠性”从模型层面转移到了系统层面。未来,我们可能会看到“Harness-optimized”的模型——它们不追求“通用智能”,而是追求“在 Harness 约束下的高效执行”。这有点像 RISC 架构:简化指令集,让编译器来承担更多的优化工作。
趋势 2: 从压缩到架构的转变
早期的 context engineering 关注各种压缩技术(summarization、compaction、RAG)。但 OpenAI 和 Hightouch 的实践显示:问题不是“如何压缩”,而是“如何组织”。
为什么“地图式”比“百科全书式”更有效?因为 Transformer 的 attention 对处于中间的 tokens 会衰减。把 100 页文档全部塞进 context,模型对后 50 页的 attention 会显著降低。给它一张 100 行的地图,再加上按需检索,每次检索的内容就都在高 attention 区域内。
OpenAI 的 AGENTS.md 只有 100 行,但它指向的是一个结构化的知识库。Hightouch 的动态子 Agent 隔离了上下文。这些都是对 Transformer 架构特性深刻理解后的产物。
未来的 harness 不会变得更简单,而会变得更结构化。就像 Kubernetes 的目的不是让容器变简单,而是让容器变得可管理。
趋势 3: Harness 作为持久的竞争优势
即使未来模型变得完美无缺,harness 依然重要。因为 harness 所积累的是领域知识、工作流程模式、安全策略,这些不会因为新模型的发布而过时。
OpenAI 的 Codex App Server 提供的不仅是 agent loop,还有身份认证、模型发现、配置管理。Anthropic 的 harness 包括了审批流程、权限控制。这些都是系统集成的问题。
Harness 不解决“模型不够聪明”的问题,它解决的是“如何让 AI 与人类工作流程、合规要求、安全边界集成”的问题。即使模型完美了,这些问题依然存在。
那些能够构建出优秀 harness 的公司,将拥有持久的护城河。就像 CSP(云服务提供商)的价值不在于“服务器更快”,而在于“让基础设施可管理、可扩展、可靠”。
结语
为什么 OpenAI、Anthropic、LangChain 这些公司都在投入大量资源构建 Harness?
传统软件系统的核心是确定性:给定相同的输入,总能得到相同的输出。工程师们通过测试、类型系统、静态分析,把所有可能的执行路径都控制住。
但执行层从 CPU 变成了 LLM,系统就变成了概率性的。Agent 在第 50 步会做什么,完全取决于前 49 步动态构建出来的 context。这种不确定性,无法通过“写更好的代码”来消除,因为它本身就是 LLM 的本质特征。
Harness Engineering 尝试用工程的方法,来解决 AI 落地时的这个关键问题:如何让概率性系统可靠地运行。它并不追求消除不确定性,而是通过限制边界来管理它:
- OpenAI 用
AGENTS.md+ 渐进式披露,把 Agent 可能看到的 context 限制在结构化的信息空间内 - Anthropic 用 feature list + git commits,把任务分解成 200+ 个可验证的小步骤
- LangChain 用强制验证循环,让 Agent 无法跳过测试就宣布完成
- Hightouch 用动态子 Agent,把执行路径隔离在独立的上下文中
这些设计的共同点在于:通过结构化、可验证性、隔离性,把概率性执行约束在可管理的范围之内。
可以看出,Harness Engineering 的技术本质,其实有点像操作系统:它提供一个抽象层,让不可预测的硬件变成可管理的资源。而 Harness 的作用,就是让不可预测的 LLM 输出,变成可管理的 Agent 行为。
未来,即使更新、更强的模型持续发布,Harness 依然会非常重要。因为在行业场景的 AI 应用中,最关键的问题始终是:如何让概率性系统在生产环境中可靠运行。这是一个独立于大模型自身能力的系统工程问题。




