自编码器全面指南:原理、结构与实际应用
自编码器本质上是一种神经网络,专门用于“自学”数据的压缩表示——也就是编码,再将其还原回去。初看之下,它就像一台数据复印机,但真正的价值在于能够挖掘数据中的关键特征。
可以这样理解:你有一个会画画的机器人,它观察图像后记住最重要的部分,再凭记忆将其绘制出来。尽管画出的内容可能不完全一致,但核心信息都得到了保留。

自编码器原理详解
结构组成
自编码器的工作是将复杂的数据转换为更简单、更有效的表示形式,即所谓的“潜在空间”。这一思路构成了U-Net等许多经典网络结构的核心基础。简单来说,自编码器就是一个学习数据有效表示特征的神经网络——它试图用尽可能少的特征来描述尽可能大的数据量。
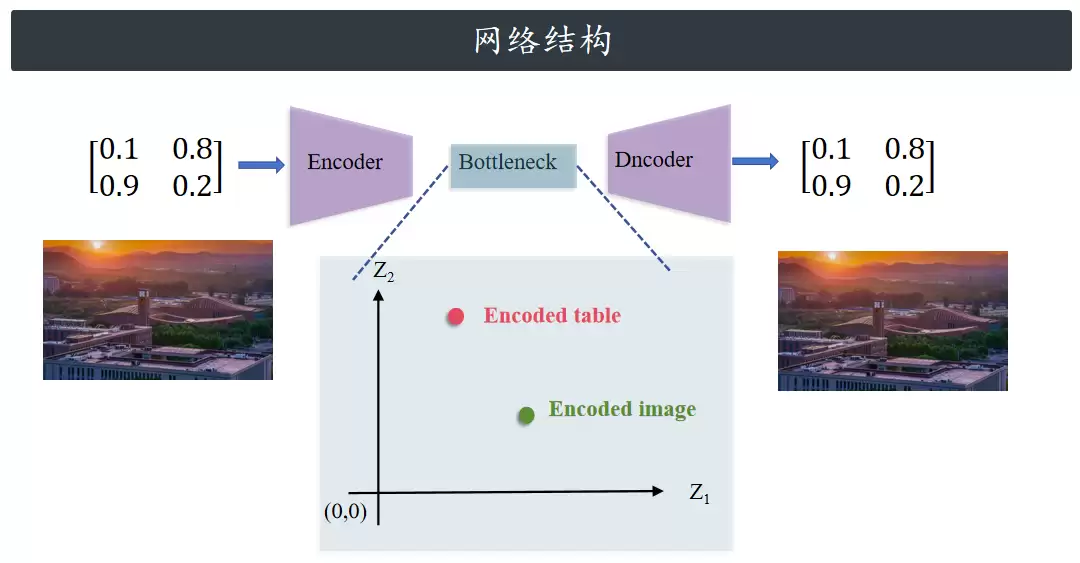
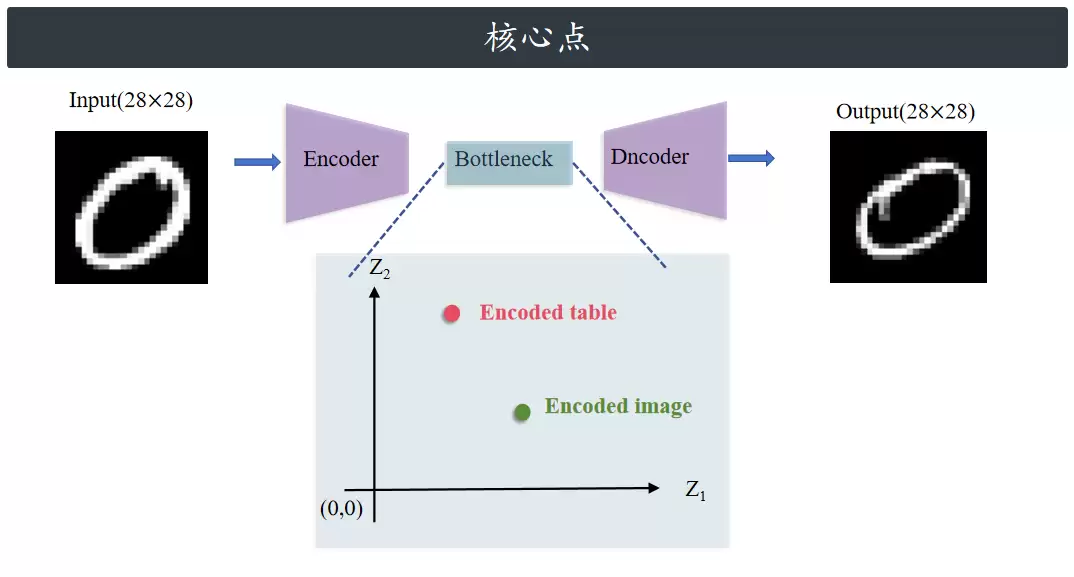
它的架构主要由三部分组成:编码器、潜在空间、解码器。
编码器将数据压缩为潜在空间表示,这个低维空间专门捕捉输入数据的基本特征。瓶颈层负责保存此压缩表示。最后,解码器从压缩表示中重建出原始数据。自编码器不仅能压缩简单数据,对高维数据——例如表格数据、图片——也同样有效。
训练的核心目标是最小化生成数据与原始数据之间的差异。换句话说,是要提高编码器从原始数据中提取特征的能力,保留关键信息,同时提升解码器根据这些关键信息恢复数据的能力。
那么,如何度量两张图片的差异呢?最简单的方法是逐个像素比较——计算对应像素的差值,然后取平均值。这个差异正是MSE损失函数的核心思想。

有人可能会问:为什么要费这么大劲使用这个模型?
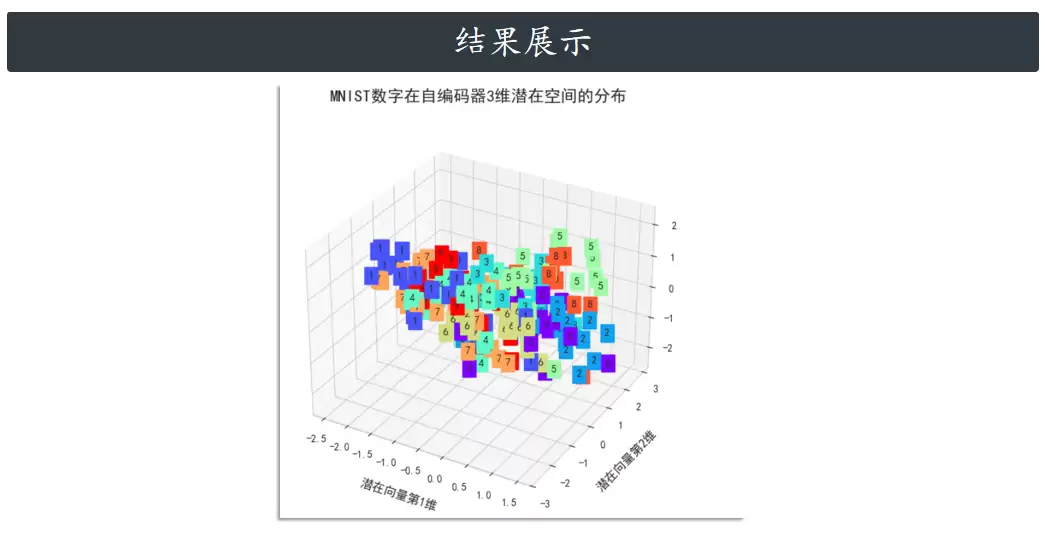
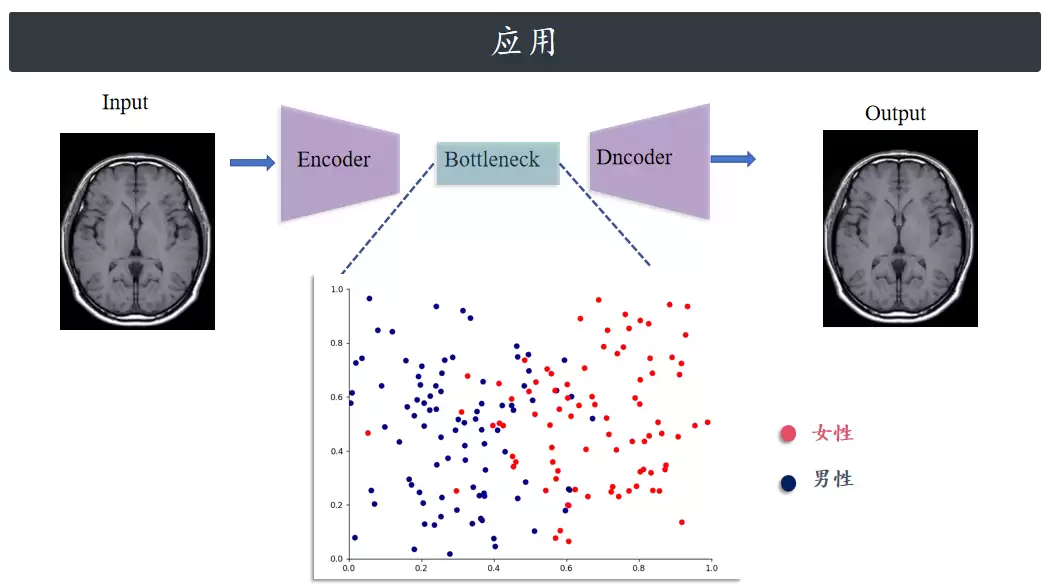
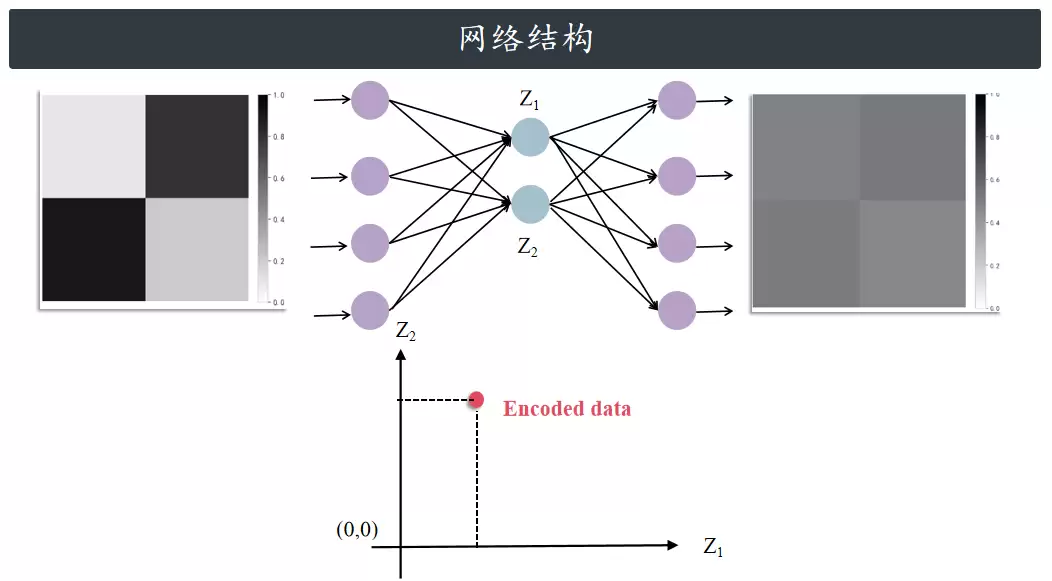
答案在于,自编码器能够高效地完成数据降维。潜在空间的维度由瓶颈层神经元的数量决定——如果瓶颈层只有两个神经元,潜在空间就是二维的。此时,可以将每个神经元的输出视为一个平面的方向,直观地看到每个数据点是如何被编码的。如果编码器训练良好,相同数字的数据点就会聚集到潜在空间的同一区域。训练过程中,每个类别会逐渐占据属于自己的独特位置。
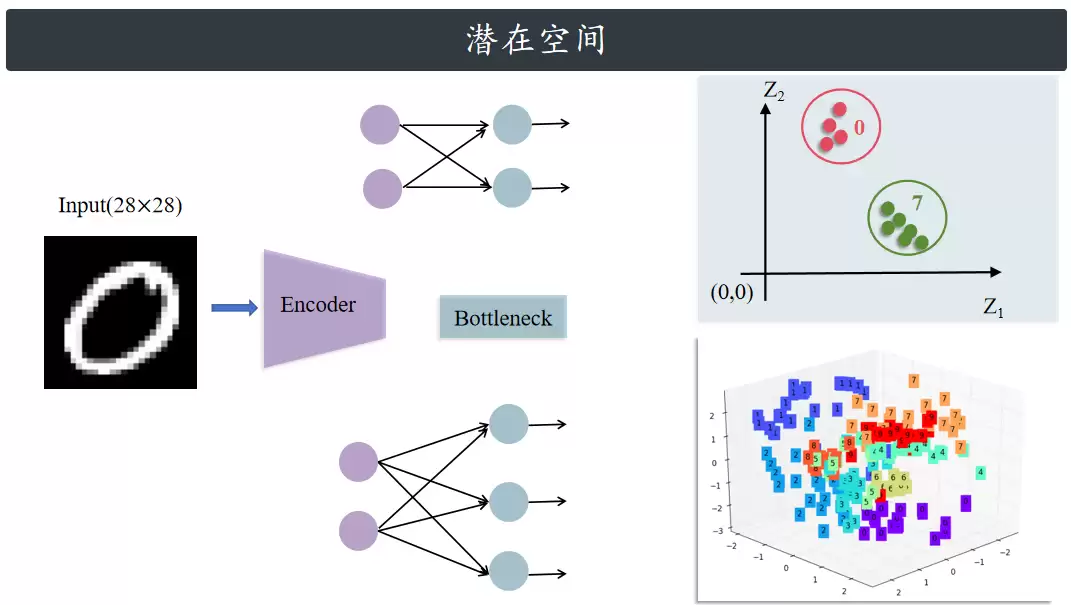
设计自编码器时,一个特别重要的选择就是潜在空间的维度——即瓶颈层神经元的数量,这可以说是整个网络最核心的部分。潜在空间太小,自编码器可能连数据的基本特征都无法识别。
那么,为什么大家如此关注重建质量?很简单——重建质量差,本质上就是潜在空间的质量差。
应用场景举例
举个例子。假设一家繁忙的医院每天要接待成千上万的患者,进行数十万次核磁共振检查,但患者的性别数据却丢失了。此时,可以训练一个自编码器,根据脑部成像来识别患者性别。自编码器会把脑部成像降到更低维度,这样一来,识别性别反而变得更加容易。
手算模拟:自编码器前向传播
现在,我们用一个4维输入数据,手动走一遍前向传播的过程。
先定义一个简单的自编码器网络结构:网络接收4维输入数据,通过编码器中的全连接层,将高维数据压缩到2维潜在空间,同时使用Tanh激活函数将潜在向量的输出范围限制在(-1,1)之间,从而增强特征区分度;接着,这个2维潜在向量被送入解码器,解码器通过全连接层将低维向量恢复成4维数据,并借助Sigmoid激活函数把重建结果限定在[0,1]区间,以匹配原始输入的数值范围。
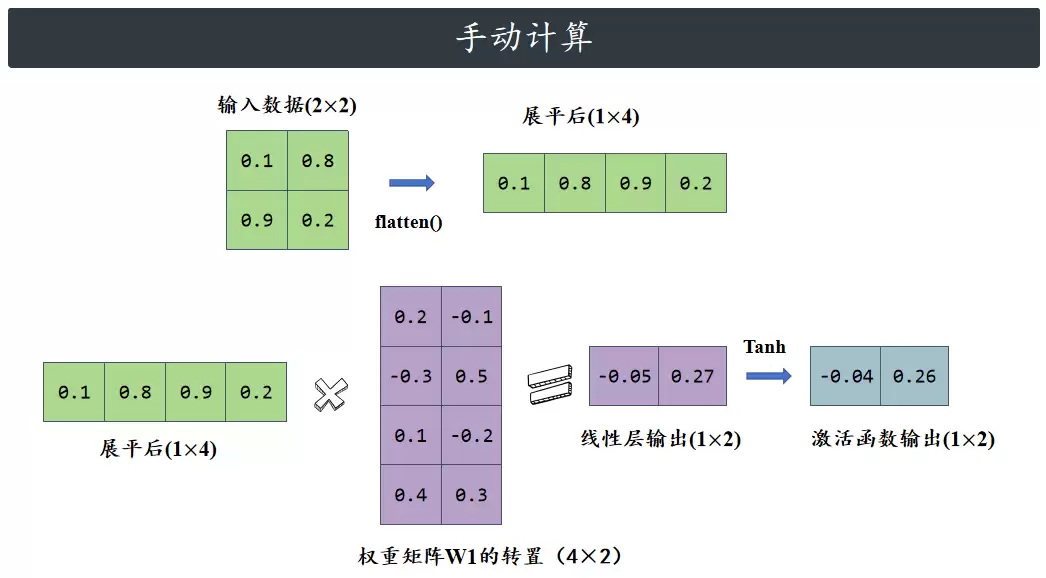
原始2x2输入数据是[[0.1, 0.8],[0.9, 0.2]],先展平成1x4的向量[0.1, 0.8, 0.9, 0.2],作为模型输入。然后进入编码阶段:输入向量与2x4的编码器权重[[0.2,-0.3,0.1,0.4],[-0.1,0.5,-0.2,0.3]]做点积(无偏置),得到线性层输出[-0.05, 0.27],再经过Tanh激活,生成2维潜在向量[-0.049958, 0.263625]——完成从高维到低维的压缩。
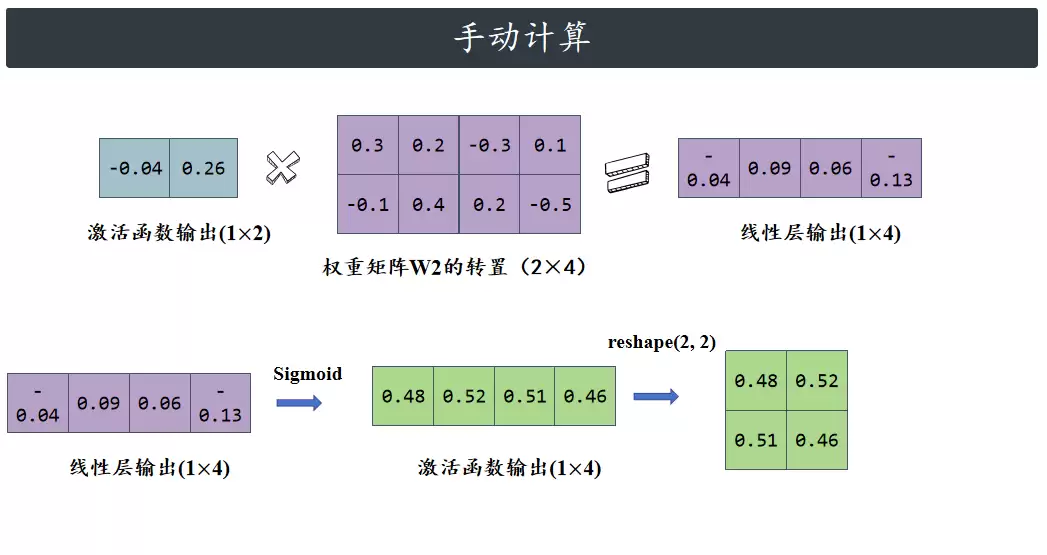
接下来进入解码阶段:2维潜在向量与4x2的解码器权重[[0.3,-0.1],[0.2,0.4],[-0.3,0.2],[0.1,-0.5]]再次做无偏置点积,得到线性层输出[-0.04135, 0.095458, 0.067712, -0.136808],经Sigmoid激活后生成1x4的重建向量[0.489664, 0.523846, 0.516922, 0.465851]。最后将重建向量重塑为2x2矩阵[[0.4897, 0.5238],[0.5169, 0.4659]],完成从低维潜在向量到原始维度数据的重建。
代码实现
数字分类实战
模型训练
可视化潜在空间