从某种程度上看,对 AI 从业者而言,这无疑是一句极具启发性的箴言。OpenAI 首席科学家在 MIT 的一场演讲中,揭示了 o1 模型训练背后的核心逻辑,更重要的是,为整个 AGI 研究指明了一条更本质的路径:激励模型,而非直接教导。
不要急于将其视为一句口号。这场演讲的主旨并非分享具体的技术细节或实验结果,而是展示一种思考框架。正如演讲者所言:“Don't teach. Incentivize.”——这条逻辑看似简单,却直指当今大语言模型研究的核心命题。


支持这些观点的核心逻辑,可以凝练为以下几张幻灯片所示。
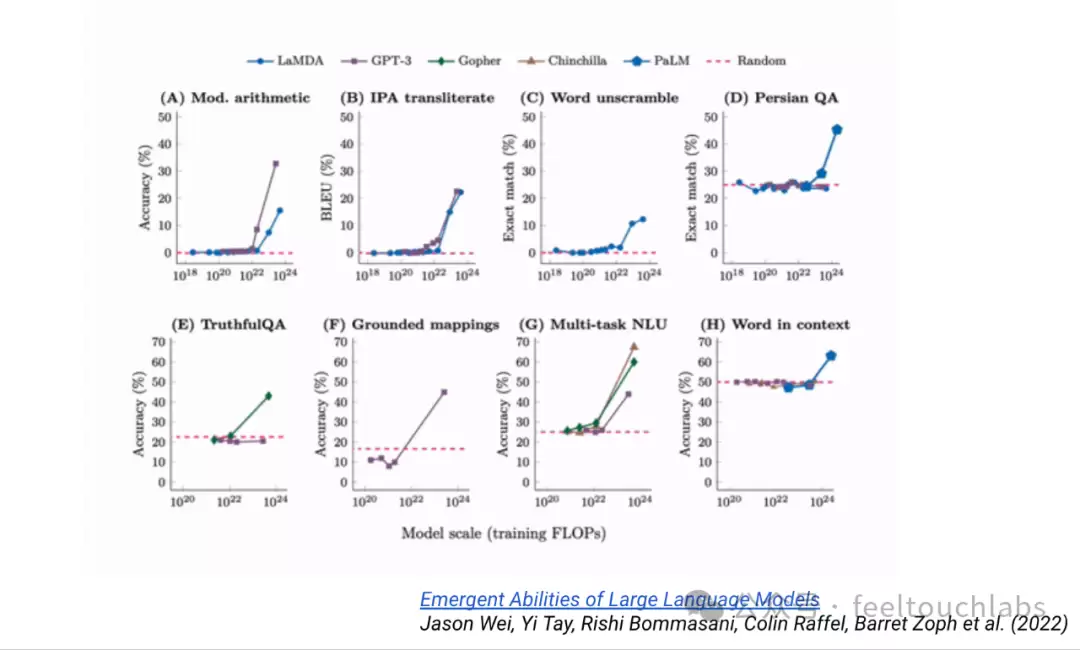

这给我们带来了哪些启示?从长远视角来看,可以归纳出几个关键判断。


核心洞察
第一个判断:计算成本正呈指数级下降。这意味着,AI研究者不应再受算力限制,而应将精力聚焦于设计真正可扩展的方法——这才是更明智的着力点。
第二个层面:当前大语言模型本质上依赖于“下一个标记预测”范式。从激励结构来看,这是一种相对较弱的信号,虽然能驱动模型学习,但在激发推理等通用技能时,效率远不及期望。
更核心的结论是:与其教导模型具体技能,不如设计激励机制。直接教授特定技能是一条狭窄之路,而构建一个能让能力自然涌现的激励框架,才是通往 AGI 通用技能的更优路径。
最后,关于“涌现能力”,一个关键视角是“学会遗忘”。在模型持续增强的过程中,我们往往执着于让模型记住更多,但有时,具备“遗忘”或“重塑”的能力,反而能带来真正的突破。
总结与展望
计算成本下降的红利已近在眼前。如果AI研究者能将设计可扩展方法作为首要任务,并从“教学范式”转向“激励范式”,那么即将出现的可能性,或许会超出我们今天对 AGI 的想象。