为什么传统的自编码器没法直接拿来生成新图像?这其实是个很有意思的问题。
传统自编码器拿到一张图像后,会把它压缩成一个低维向量——通常是10到100维的样子,然后拿着这个向量去重建原始图像。这就好比你让一个画家看一眼风景,然后只给他几个关键词去还原。这个低维空间,在学术上叫做“潜在空间”,它比原始图像那上千个像素紧凑得多,也更容易解释。
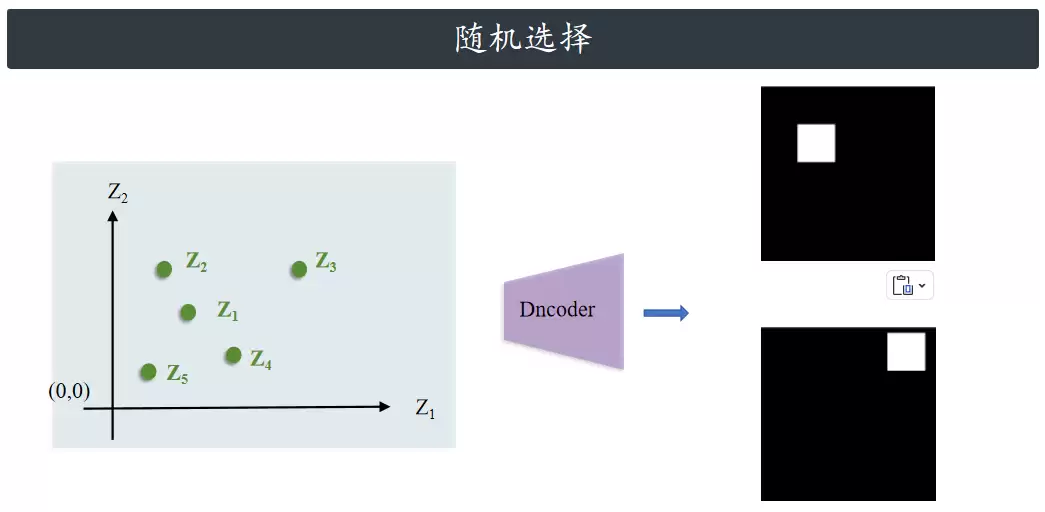
现在我们假设手头已经有个训练好的解码器了,它能根据图像的潜在表示把原图还原出来。那么要生成一张全新的图像,最直接的想法就是:从潜在空间里随便挑一些点,扔给解码器让它生成就行了。但现实往往很骨感——大部分时候这么做的结果是一团糟。
为什么?因为潜在空间本身通常是非常混乱的、没什么规律可循。空间里大部分区域,解码器根本不知道该怎么把它们变成有意义的图像。
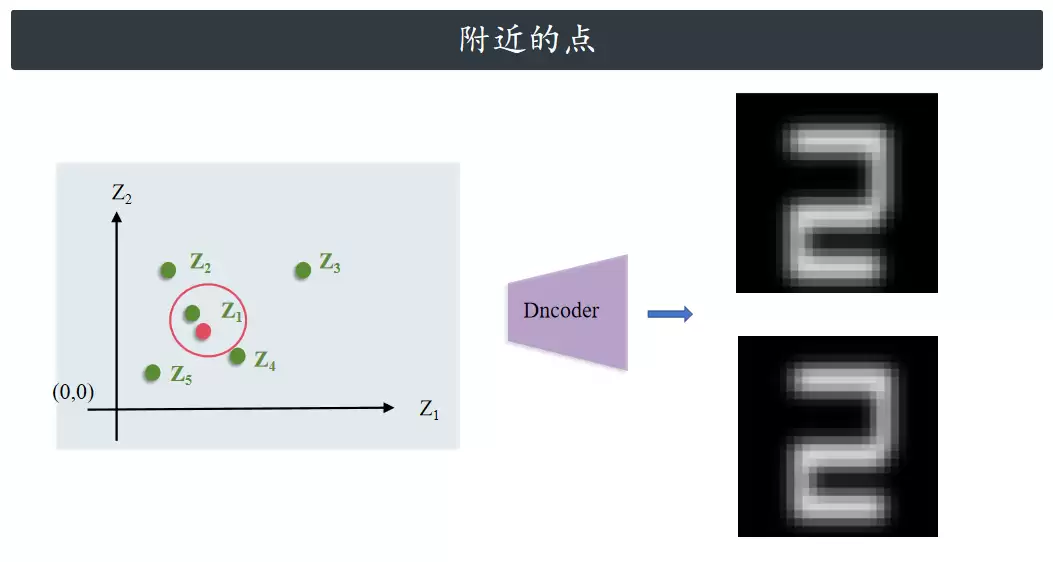
那换个思路行不行?比如取一张编码后的图像,然后采样它潜在表示附近的点。理论上这样应该能生成和原图差不多的新图像。但问题在于,潜在空间的表示实在太糟糕了,附近的点对应不了原始图像附近有意义的变化。如果我们采样靠近原始图像的点,大概率只会得到和原始图像一模一样的重构结果。
原理介绍
那么解决方案到底在哪?理想情况下,我们希望有一个组织良好的潜在空间——在这个空间里随机采样点,就能生成连贯且有意义的新图像。变分自编码器(VAE)正是沿着这个思路设计的。
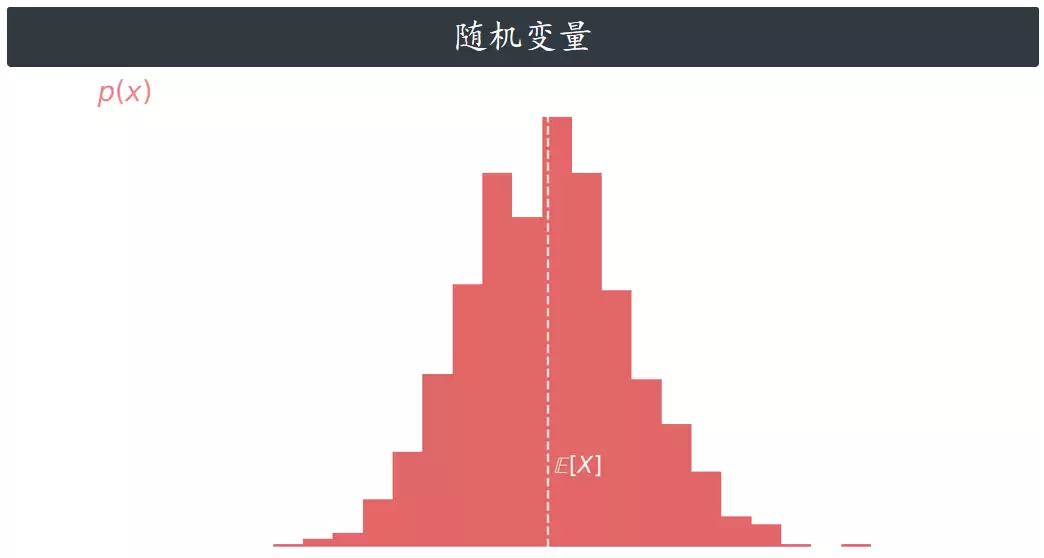
在深入VAE之前,先快速回顾一下贝叶斯的基本符号和概念。假设有一个随机变量 X,它的取值范围是0到10。如果某个事件发生的概率是按照X的分布来的,我们就说“从X里抽样”。还有一个叫“概率密度函数”的东西,用 p(x) 表示,它告诉我们从X里抽到0到10中某个具体值的可能性有多大。另外,E(x) 代表这个分布的“期望值” —— 简单说就是从X里抽很多次,所有结果的平均值大概是多少,这个平均值可以通过概率密度函数的积分算出来。
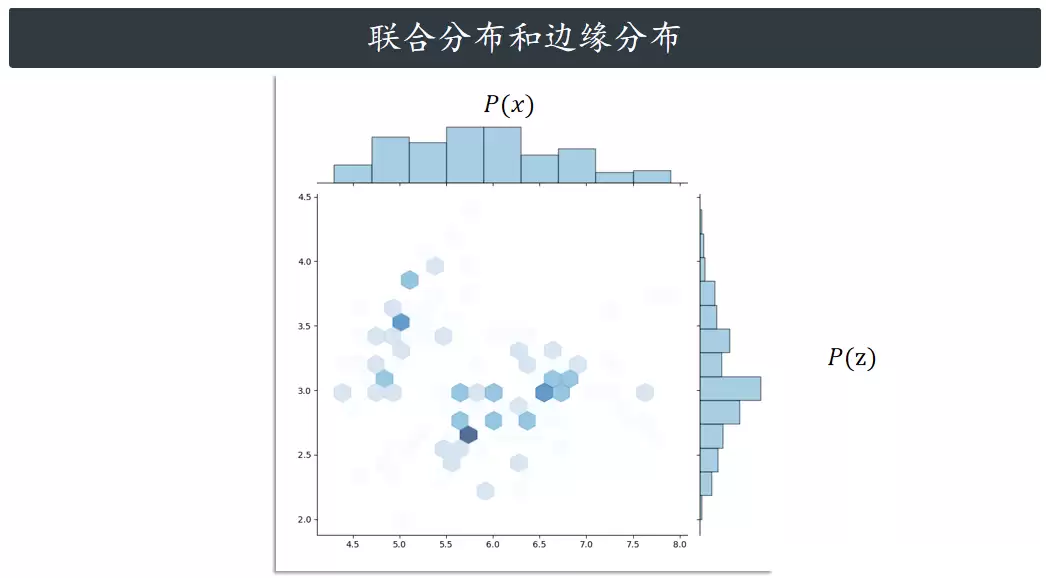
现在考虑两个随机变量 X 和 Z。在三维图里展示的是它们的联合概率分布,也就是每对可能的 X 和 Z 同时发生的概率。当然,X 和 Z 各自也有自己的概率分布,叫作边缘概率分布,分别用 P(X) 和 P(Z) 表示。有意思的是,联合分布可以用来算出这两个边缘分布——这个过程叫边缘化,做法是对另一个变量积分。比如,想知道X取某个值的概率,就把所有可能的Z值代入联合分布做积分;想知道Z取某个值的概率,就把所有可能的X值代入联合分布做积分。
还有一个概念叫条件概率,其实可以理解为从联合分布里“切出一片”,然后拿Z值抽样的概率去做归一化。
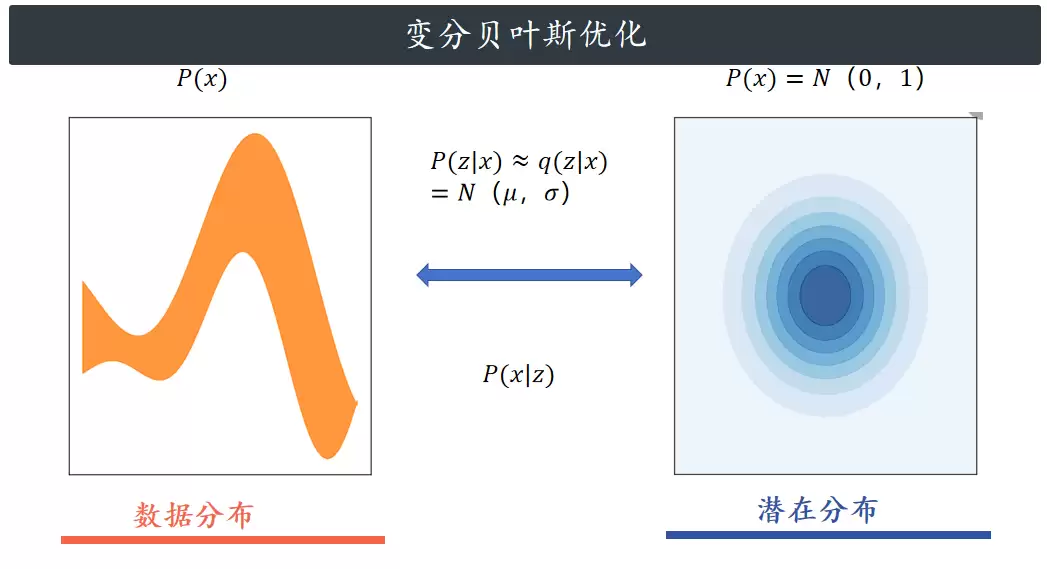
我们的目标,是从数据集的分布 P(x)(比如图像的分布)里生成新数据。但我们并不知道P(x)具体长什么样,能拿到的只是它的样本。因此,我们引入了一个低维空间的潜在分布 P(Z),用Z向量来捕捉数据的核心特征。
为了把 P(x) 和 P(Z) 连接起来,我们需要两个映射:后验分布(给定图像X,生成Z的概率)和似然分布(给定Z,重构出X的概率)。从理论上来说,从后验里抽个Z,再重构成X,就能生成新数据。但问题是,我们也不知道 P(Z) 的具体形式,计算根本没法直接进行。
于是我们做了一个关键的假设:假设 P(Z) 服从正态分布。这样一来,似然 P(X|Z) 就可以计算了,但后验 P(Z|X) 仍然是未知的。变分自编码器的做法,是引入一个带可学习参数的高斯分布 q(z|x) 来近似真实的后验。这个学习的过程,就是变分贝叶斯优化。
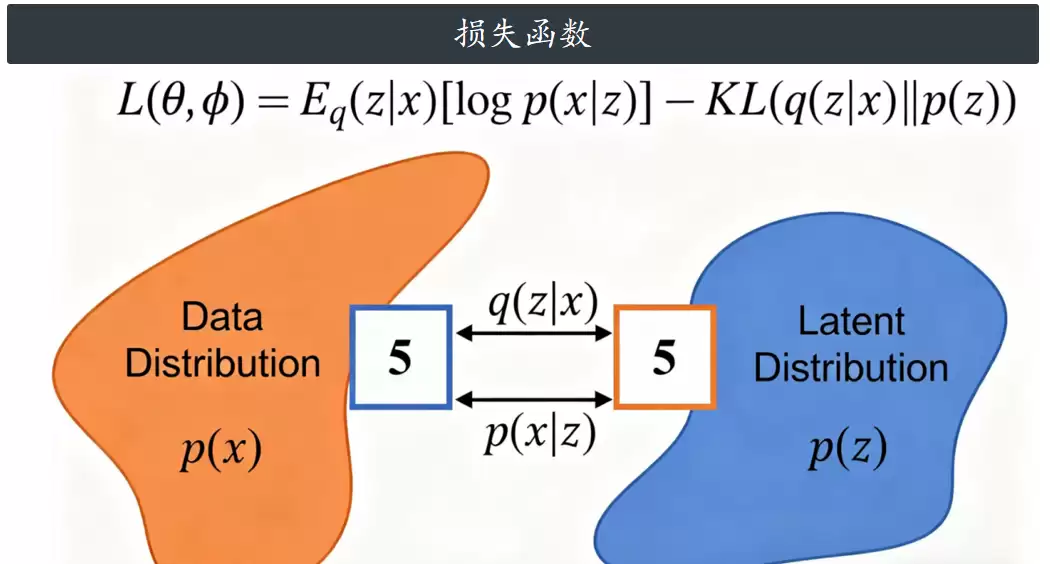
在具体实现上,我们用编码器从图像里估计两个参数,然后让解码器根据抽样出的潜在变量Z去重构图像。要让自编码器既能近似后验又能重构图像,首先需要通过贝叶斯公式推导出训练的目标函数。
这个目标函数由两部分组成:第一部分是“一致性项”,用来衡量用Z重构原图像X的效果。因为做了一些假设,这一项可以简化为L2损失(也就是均方误差)。计算时只需用解码器生成重构图像,然后与原图做L2差距对比。第二部分是KL散度,它衡量的是近似后验和先验分布 P(Z) 之间的距离。我们选择的 P(Z) 是正态分布,所以在优化过程中,能让近似后验也趋近于正态分布。
简而言之,变分自编码器的训练目标L是一个带正则化的重构损失——既靠L2损失保证重构效果,又靠KL散度让潜在空间符合正态分布,最终确保生成的样本和原始数据分布 p(x) 保持一致。
手动计算
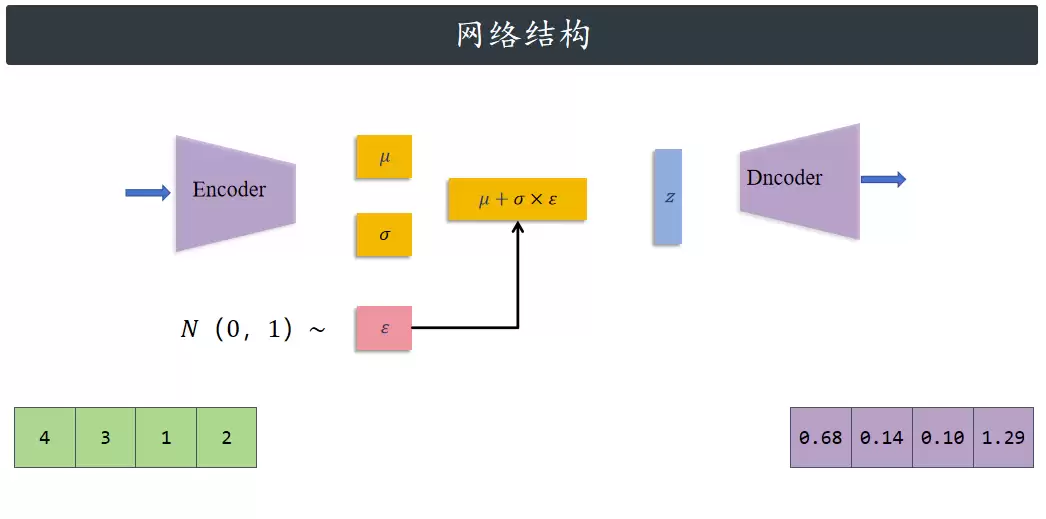
网络结构
现在从理论转向实际操作。自编码器是如何实现上述分布的?普通自编码器把输入压缩成潜在空间的一个点,再解码回输入空间。但变分自编码器不一样——它的编码器会把输入转换成一个高斯分布的两个参数(均值和方差),用这个分布来代表输入,而不是一个具体的点。
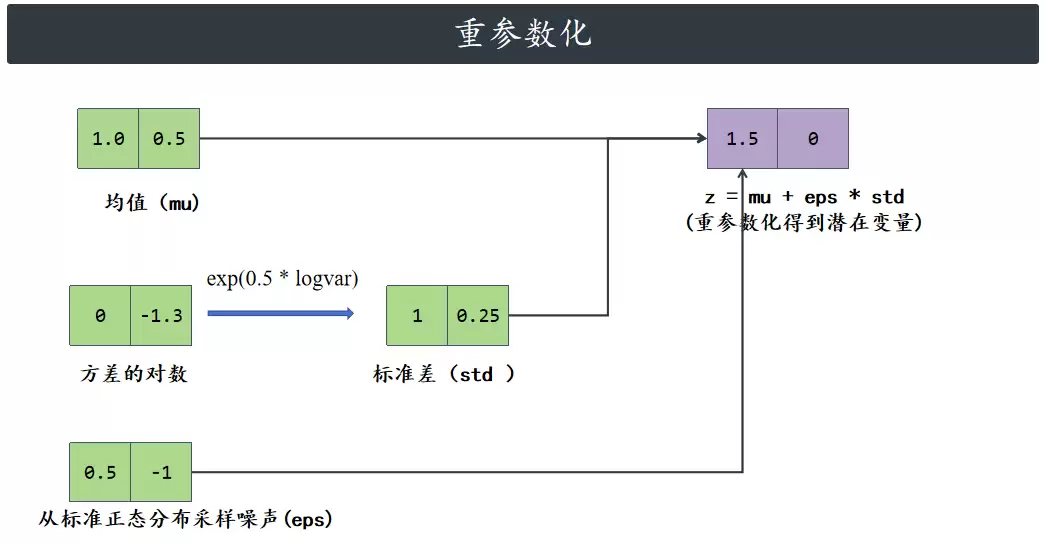
之后,从这个高斯分布里随机抽点,让解码器把这些点转回输入空间,就可以计算L损失的各个部分,然后反向传播进行优化。但问题来了:抽样操作本身是不可微的,没法反向传播。这就需要“重参数化技巧”:先从标准正态分布里抽一个随机噪声点,用编码器输出的方差去缩放它,用均值去平移它。这样做,既相当于从后验分布中抽样,又能让整个过程对参数可微,从而支持反向传播。
典型的VAE流程和普通自编码器类似——先拿图像生成重构图,对比原图计算重构效果。但它还会输出后验分布的参数,再计算这个后验和先验(标准正态分布)之间的KL散度。两个高斯分布的KL散度有现成的封闭计算公式,可以直接使用。
手算模拟
假设有这样一个任务:输入特征 D=4(例如:身高、体重、年龄、收入),潜在空间维度 L=2(例如:抽象的“健康度”和“财富值”)。
首先,把输入展平,经过一个包含8个神经元的线性层,得到一个(1×8)的输出,再经过一个激活函数,同样得到(1×8)的输出。
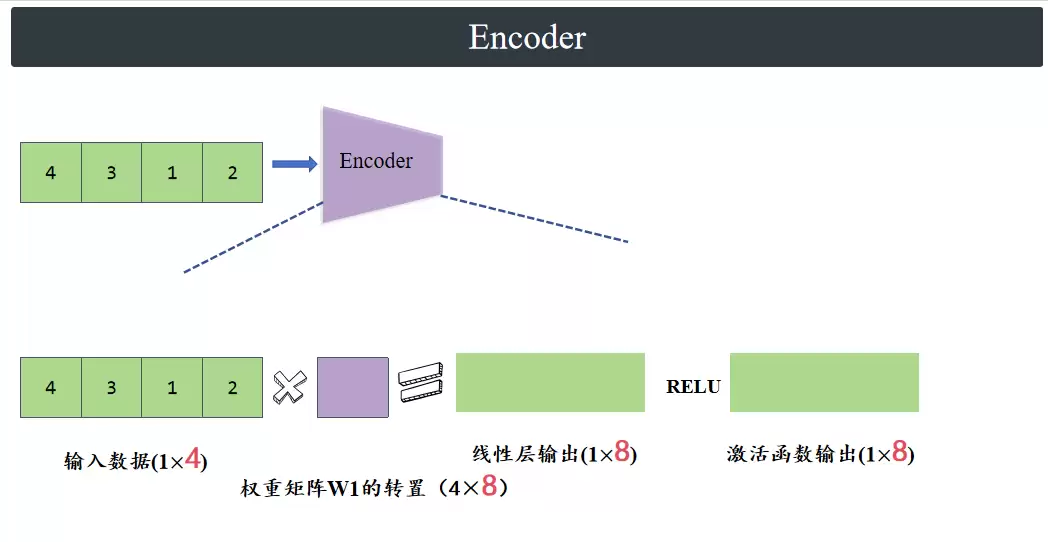
接下来,分别通过两个只有2个神经元的线性层,得到(1×2)的均值参数和方差的对数参数。
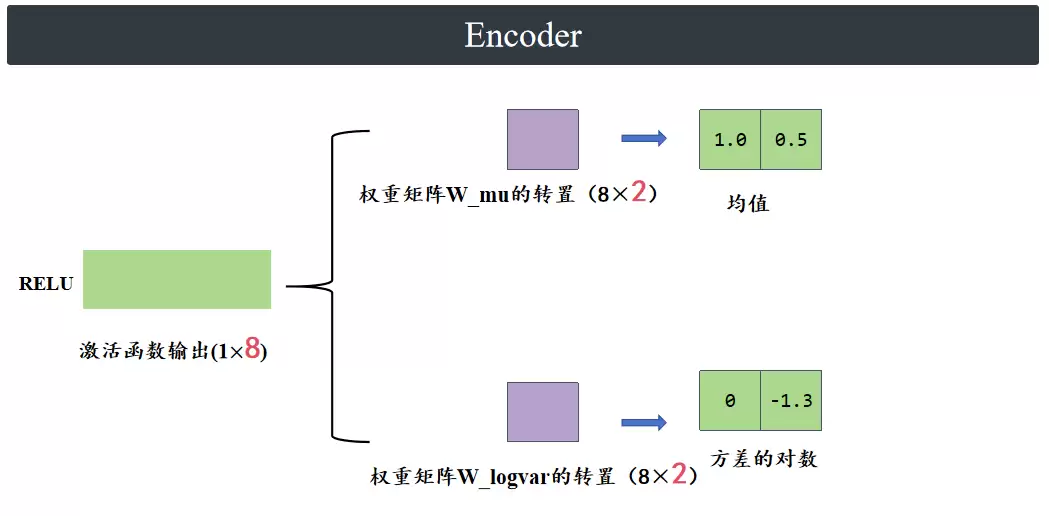
然后,通过重参数化技巧得到潜在变量Z。
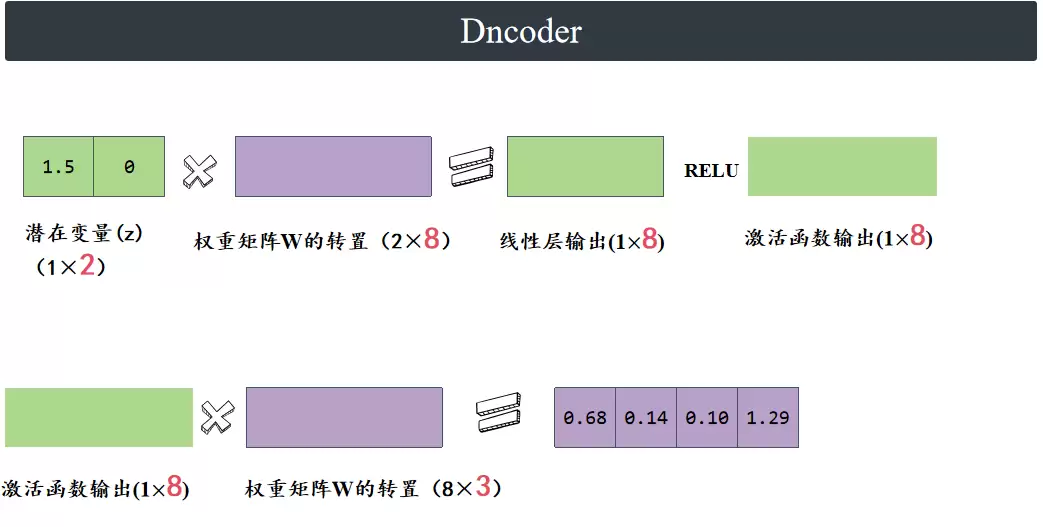
潜在变量Z,再通过一个8个神经元的线性层,经过ReLU激活函数,再经过一个4个神经元的线性层,最终得到一个(1×4)的输出。
损失函数的计算则包含重构损失和KL散度两部分:

代码实现
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
D_INPUT = 4
H_HIDDEN = 8
L_LATENT = 2
X_input = torch.tensor([4.0, 3.0, 1.0, 2.0], dtype=torch.float32).unsqueeze(0)
print("原始输入形状:", X_input.shape) # [1, 4]
class VAE(nn.Module):
def __init__(self, D_in, H, L_lat):
super(VAE, self).__init__()
self.fc1 = nn.Linear(D_in, H)
self.fc_mu = nn.Linear(H, L_lat)
self.fc_logvar = nn.Linear(H, L_lat)
self.fc3 = nn.Linear(L_lat, H)
self.fc4 = nn.Linear(H, D_in)
nn.init.normal_(self.fc1.weight, mean=0.0, std=0.1)
nn.init.constant_(self.fc1.bias, 0.0)
nn.init.normal_(self.fc_mu.weight, mean=0.0, std=0.1)
nn.init.constant_(self.fc_mu.bias, 0.0)
nn.init.normal_(self.fc_logvar.weight, mean=0.0, std=0.1)
nn.init.constant_(self.fc_logvar.bias, 0.0)
nn.init.normal_(self.fc3.weight, mean=0.0, std=0.1)
nn.init.constant_(self.fc3.bias, 0.0)
nn.init.normal_(self.fc4.weight, mean=0.0, std=0.1)
nn.init.constant_(self.fc4.bias, 0.0)
def encode(self, x):
h1 = self.fc1(x)
h1_act = F.relu(h1)
mu = self.fc_mu(h1_act)
logvar = self.fc_logvar(h1_act)
return h1, h1_act, mu, logvar
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
z = mu + eps * std
return std, eps, z
def decode(self, z):
h3 = self.fc3(z)
h3_act = F.relu(h3)
recon_x = self.fc4(h3_act)
return h3, h3_act, recon_x
def forward(self, x):
h1, h1_act, mu, logvar = self.encode(x.view(-1, D_INPUT))
std, eps, z = self.reparameterize(mu, logvar)
h3, h3_act, recon_x = self.decode(z)
return {
'h1': h1, 'h1_act': h1_act,
'mu': mu, 'logvar': logvar, 'std': std, 'eps': eps, 'z': z,
'h3': h3, 'h3_act': h3_act,
'recon_x': recon_x
}
def vae_loss_function(recon_x, x, mu, logvar):
BCE = F.mse_loss(recon_x, x.view(-1, D_INPUT), reduction='mean')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE, KLD, BCE + KLD
if __name__ == "__main__":
model = VAE(D_INPUT, H_HIDDEN, L_LATENT)
with torch.no_grad():
outputs = model(X_input)
h1 = outputs['h1']
h1_act = outputs['h1_act']
mu = outputs['mu']
logvar = outputs['logvar']
std = outputs['std']
eps = outputs['eps']
z = outputs['z']
h3 = outputs['h3']
h3_act = outputs['h3_act']
recon_x = outputs['recon_x']
L_rec, L_kld, Total_Loss = vae_loss_function(recon_x, X_input, mu, logvar)
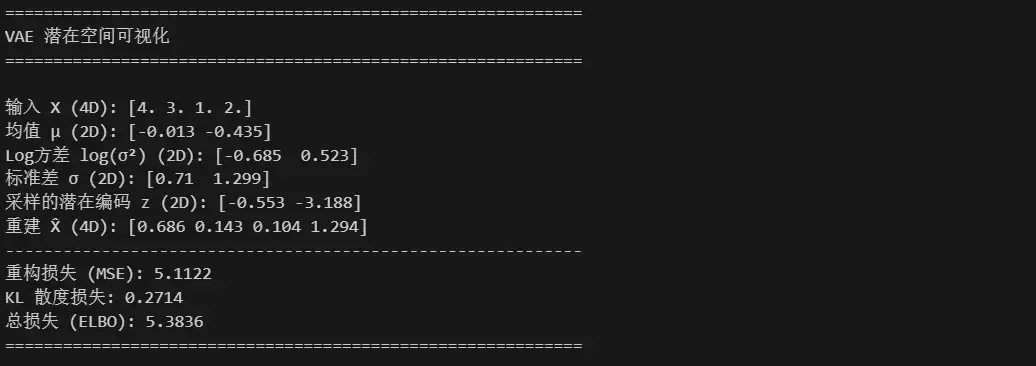
print("\n【1. 输入层】")
print(f"输入数据 X: {X_input.squeeze().numpy().round(4)}")
print("\n【2. 编码器】")
print(f"fc1线性变换: {h1.squeeze().numpy().round(4)}")
print(f"ReLU激活后: {h1_act.squeeze().numpy().round(4)}")
print(f"均值 μ: {mu.squeeze().numpy().round(4)}")
print(f"对数方差 log(σ²): {logvar.squeeze().numpy().round(4)}")
print("\n【3. 重参数化】")
print(f"标准差 σ: {std.squeeze().numpy().round(4)}")
print(f"随机噪声 ε: {eps.squeeze().numpy().round(4)}")
print(f"潜在变量 z: {z.squeeze().numpy().round(4)}")
print("\n【4. 解码器】")
print(f"z→fc3线性变换: {h3.squeeze().numpy().round(4)}")
print(f"ReLU激活后: {h3_act.squeeze().numpy().round(4)}")
print(f"重构结果 X̂: {recon_x.squeeze().numpy().round(4)}")
print("\n【5. 损失计算】")
print(f"重构损失 (MSE): {L_rec.item():.6f}")
print(f"KL散度损失: {L_kld.item():.6f}")
print(f"总损失 (ELBO): {Total_Loss.item():.6f}")

可视化
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Ellipse
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
D_INPUT = 4
H_HIDDEN = 8
L_LATENT = 2
X_input = torch.tensor([4.0, 3.0, 1.0, 2.0], dtype=torch.float32).unsqueeze(0)
class VAE(nn.Module):
def __init__(self, D_in, H, L_lat):
super(VAE, self).__init__()
self.fc1 = nn.Linear(D_in, H)
self.fc_mu = nn.Linear(H, L_lat)
self.fc_logvar = nn.Linear(H, L_lat)
self.fc3 = nn.Linear(L_lat, H)
self.fc4 = nn.Linear(H, D_in)
def encode(self, x):
h1 = F.relu(self.fc1(x))
return self.fc_mu(h1), self.fc_logvar(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h3 = F.relu(self.fc3(z))
return self.fc4(h3)
def forward(self, x):
mu, logvar = self.encode(x.view(-1, D_INPUT))
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar, z
def vae_loss_function(recon_x, x, mu, logvar):
BCE = F.mse_loss(recon_x, x.view(-1, D_INPUT), reduction='mean')
KLD = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
return BCE, KLD, BCE + KLD
def visualize_latent_space(mu, logvar, z_latent, num_samples=200):
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
std = torch.exp(0.5 * logvar).squeeze().numpy()
mu_np = mu.squeeze().numpy()
z_np = z_latent.squeeze().numpy()
samples = []
for _ in range(num_samples):
eps = np.random.randn(L_LATENT)
z_sample = mu_np + std * eps
samples.append(z_sample)
samples = np.array(samples)
axes[0].scatter(samples[:, 0], samples[:, 1], alpha=0.4, s=40,
c='lightblue', edgecolors='blue', linewidth=0.5, label='采样点')
axes[0].scatter(mu_np[0], mu_np[1], c='red', s=300, marker='*',
edgecolors='darkred', linewidths=2, label='均值 μ', zorder=10)
axes[0].scatter(z_np[0], z_np[1], c='purple', s=200, marker='D',
edgecolors='darkviolet', linewidths=2, label='当前采样 z', zorder=10)
ellipse_1sigma = Ellipse((mu_np[0], mu_np[1]), width=2*std[0], height=2*std[1],
fill=False, edgecolor='red', linewidth=2, linestyle='--',
label='1σ 范围', alpha=0.8)
ellipse_2sigma = Ellipse((mu_np[0], mu_np[1]), width=4*std[0], height=4*std[1],
fill=False, edgecolor='orange', linewidth=1.5, linestyle=':',
label='2σ 范围', alpha=0.6)
axes[0].add_patch(ellipse_1sigma)
axes[0].add_patch(ellipse_2sigma)
axes[0].set_xlabel('z₁ (第一潜在维度)', fontsize=13, fontweight='bold')
axes[0].set_ylabel('z₂ (第二潜在维度)', fontsize=13, fontweight='bold')
axes[0].set_title('VAE 潜在空间分布', fontsize=15, fontweight='bold', pad=15)
axes[0].legend(loc='upper right', fontsize=11, framealpha=0.9)
axes[0].grid(True, alpha=0.3, linestyle='--')
axes[0].axhline(y=0, color='k', linewidth=0.8, alpha=0.3)
axes[0].axvline(x=0, color='k', linewidth=0.8, alpha=0.3)
info_text = f'μ = [{mu_np[0]:.3f}, {mu_np[1]:.3f}]\nσ = [{std[0]:.3f}, {std[1]:.3f}]'
axes[0].text(0.02, 0.98, info_text, transform=axes[0].transAxes,
fontsize=10, verticalalignment='top',
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
standard_samples = np.random.randn(num_samples, L_LATENT)
axes[1].scatter(standard_samples[:, 0], standard_samples[:, 1], alpha=0.3, s=30,
c='lightgreen', edgecolors='green', linewidth=0.5, label='标准正态 N(0,I)')
axes[1].scatter(samples[:, 0], samples[:, 1], alpha=0.4, s=40,
c='lightblue', edgecolors='blue', linewidth=0.5, label='VAE 潜在分布')
axes[1].scatter(mu_np[0], mu_np[1], c='red', s=300, marker='*',
edgecolors='darkred', linewidths=2, label='VAE 均值 μ', zorder=10)
axes[1].scatter(0, 0, c='green', s=300, marker='*',
edgecolors='darkgreen', linewidths=2, label='标准正态均值', zorder=10)
axes[1].set_xlabel('z₁ (第一潜在维度)', fontsize=13, fontweight='bold')
axes[1].set_ylabel('z₂ (第二潜在维度)', fontsize=13, fontweight='bold')
axes[1].set_title('潜在分布 vs 标准正态分布', fontsize=15, fontweight='bold', pad=15)
axes[1].legend(loc='upper right', fontsize=11, framealpha=0.9)
axes[1].grid(True, alpha=0.3, linestyle='--')
axes[1].axhline(y=0, color='k', linewidth=0.8, alpha=0.3)
axes[1].axvline(x=0, color='k', linewidth=0.8, alpha=0.3)
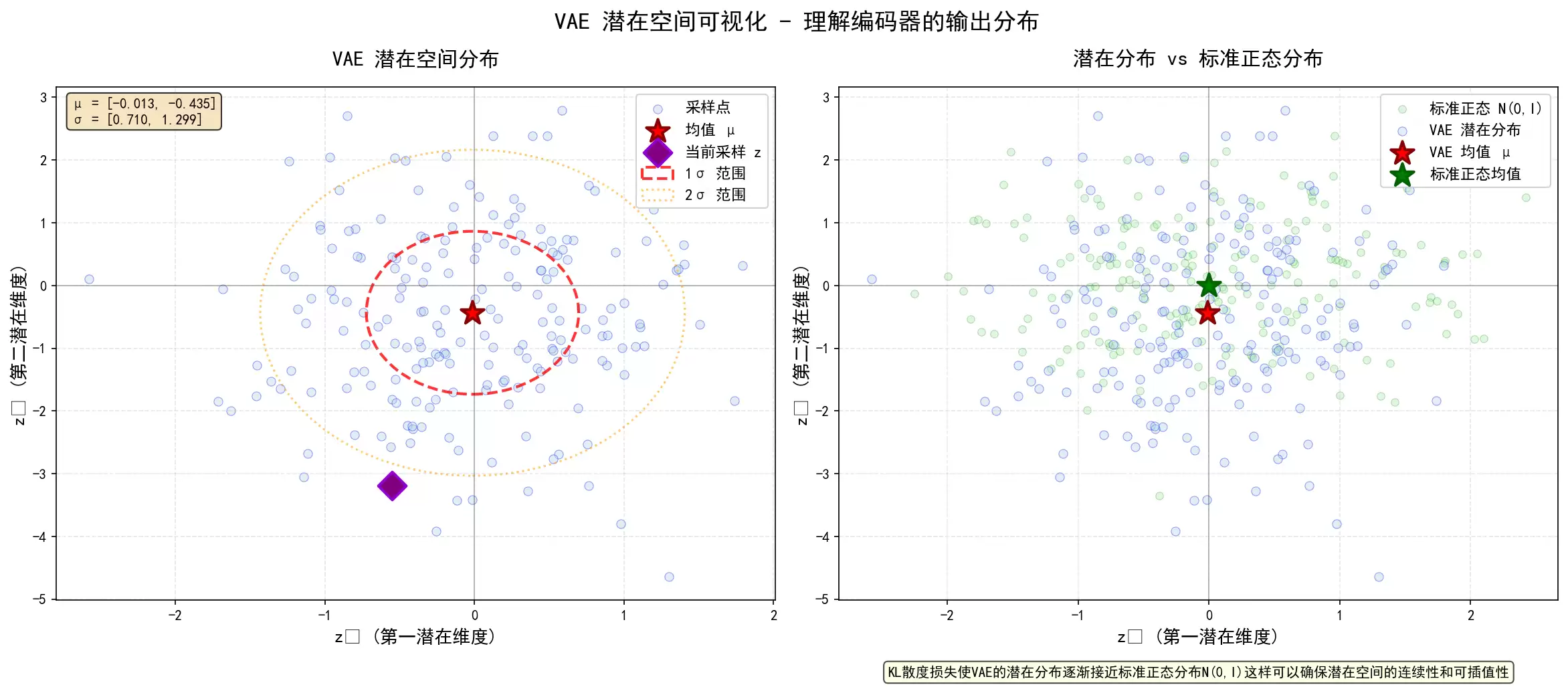
explanation = 'KL散度损失使VAE的潜在分布逐渐接近标准正态分布N(0,I),这样可以确保潜在空间的连续性和可插值性'
axes[1].text(0.5, -0.15, explanation, transform=axes[1].transAxes,
fontsize=10, ha='center', style='italic',
bbox=dict(boxstyle='round', facecolor='lightyellow', alpha=0.7))
plt.suptitle('VAE 潜在空间可视化 - 理解编码器的输出分布',
fontsize=17, fontweight='bold', y=0.98)
plt.tight_layout()
return fig
if __name__ == "__main__":
model = VAE(D_INPUT, H_HIDDEN, L_LATENT)
with torch.no_grad():
recon_batch, mu, logvar, z_latent = model(X_input)
L_rec, L_kld, Total_Loss = vae_loss_function(recon_batch, X_input, mu, logvar)
print(f"输入 X: {X_input.squeeze().numpy().round(3)}")
print(f"均值 μ: {mu.squeeze().numpy().round(3)}")
print(f"Log方差: {logvar.squeeze().numpy().round(3)}")
print(f"标准差 σ: {torch.exp(0.5 * logvar).squeeze().numpy().round(3)}")
print(f"采样的潜在编码 z: {z_latent.squeeze().numpy().round(3)}")
print(f"重建 X̂: {recon_batch.squeeze().numpy().round(3)}")
print(f"重构损失: {L_rec.item():.4f}")
print(f"KL散度损失: {L_kld.item():.4f}")
print(f"总损失: {Total_Loss.item():.4f}")
fig = visualize_latent_space(mu, logvar, z_latent, num_samples=200)
plt.sa vefig('vae_latent_space.png', dpi=150, bbox_inches='tight')
plt.show()