Karpathy四条CLAUDE.md规则让准确率从41%升至89%
时间:2026-05-29 16:38
针对AI代码助手常见的四种系统性失败模式,Karpathy提炼出四条规则:编码前思考、简单优先、精确手术式修改、目标驱动执行。ForrestChang据此编写仅70行的CLAUDE md文件,使代码准确率从41%升至89%,获15万星标。少量行为框架式规则远优于冗长的禁令清单。
# AI编程的四种常见陷阱,以及70行配置如何破解
先分享一个极具代表性的场景——
你让Claude Code协助修改一个函数,它顺手重命名了三个变量,删掉了一段“看起来没啥用”的注释,还把你精心维护了两年的配置文件格式彻底改了一遍。你并没有要求它做这些,但它自作主张做了。于是你在CLAUDE.md里加了一条“不要改动无关代码”。没过多久,又出现了其他问题,你又加了一条。两个月后,你的CLAUDE.md已经膨胀到180行,而Claude依然我行我素。
这个场景在三个不同的技术团队里反复上演。工程师们并非不够努力,恰恰相反——他们太努力了,把CLAUDE.md当成了一个防御系统来建设,每次出问题就打一个补丁,最后补丁比代码本身还多。
今年1月26日,Andrej Karpathy在X上发布了一条帖子,提到近两年他的编程工作流经历了20年来最大的变化——从80%手动写代码,变成了80%让AI Agent来执行代码。他还列举了AI写代码时常见的四种系统性失败模式。
第二天,开发者Forrest Chang将这四个观察点翻译成了一个CLAUDE.md配置文件。截至今天,这个仓库的star数已经突破15万。
这篇文章的目的不是让你“赶紧去复制这个文件”——那样做太简单了,也没什么实际价值。真正值得探讨的是:一个只有70行的文件,为什么能胜过几百行的“精心配置”?这背后隐藏着一个关于约束设计的反直觉原则,把这个原则想清楚,你写的每一个CLAUDE.md都会更加高效。
Karpathy发现了什么:四种系统性失败,而非偶然Bug
很多人误以为Claude Code出现问题是随机的——有时候听话,有时候不听话,全凭运气。Karpathy的观察否定了这种判断。他指出,这些失败是系统性的,每次出现,都源于同一批根本原因。
四种失败模式,逐一拆解。
**第一种:静默假设(Silent Assumptions)**
你说“帮我优化这个接口的性能”,Claude默默选择了一种解决方案——可能是加缓存,也可能是改索引策略。它没有告诉你它的假设,没有问你当前的瓶颈在哪里,就直接开始写代码。等代码出来后你才发现,它优化的方向完全不对,你们生产环境的瓶颈根本不在那里。
这不是Claude能力不足,而是它的训练目标之一就是“尽快给出答案”。在对话场景中这算优点,但在写代码这件事上却成了隐患。
**第二种:代码过度生长(Hypertrophy)**
让它写一个简单的文件解析器,它却给你搞出了一套带错误重试机制、支持多种编码格式、可通过配置扩展的“企业级”版本。你没有要求这些,但它默认“加更多功能等于更好”。
生产环境里最难维护的代码,往往不是逻辑复杂的那种,而是超出实际需求的那种——它的复杂度无法通过测试来覆盖,无法通过代码审查来发现,只有等到维护的时候才会暴露出来。
**第三种:附带修改(Collateral Changes)**
这是最让工程师头疼的一种情况。让它修复一个Bug,它在修Bug的同时,顺手把旁边的函数重构了,把一个变量名“改得更规范了”,还把一段死代码删掉了。每一个改动单独看都“有道理”,但组合在一起就是一个很难评审的PR,和你以为的“只改了一行”相差甚远。
**第四种:无验证完成(Unverified Completion)**
“我已经修好了”。但它有没有运行测试?有没有检查边界条件?有没有验证与现有代码的兼容性?很多时候根本没有。它在完成一件你并没有定义“完成标准”的任务。
这四个问题组合在一起,就是工程师们普遍感受到的“AI写的代码需要大量审查才能用”——不是因为代码本身有语法错误,而是因为它做了你没要求的事、没做你真正需要验证的事。

*图:四种失败模式与四条规则的对应关系*
四条规则的原文与深度拆解
Forrest Chang的CLAUDE.md文件里,针对这四种失败,写了四条规则。下面逐条拆解它为什么这样写。
**规则一:Think Before Coding(编码前先思考)**
针对静默假设。核心动作是将“隐藏的前提”显式化——在开始写代码之前,先说出你基于什么前提,如果有多种解读,先列出来,有不确定的地方先问清楚。
这条规则改变的不是Claude的能力,而是它的行为模式——从“默认执行”改为“先对齐再执行”。对于做过大型项目的工程师来说,这和我们开需求评审会的逻辑完全一致:不是说你不懂技术,而是“对齐理解”这件事本身就有价值。
**规则二:Simplicity First(简单优先)**
针对代码过度生长。关键词是“minimum”和“nothing speculative”——不写猜测性的功能,不搭建用不到的抽象层。
这条规则反直觉的地方在于:它不是说写简单的代码,而是说“只写解决当前问题的代码”。用不到的抽象不是准备,而是负债。见过太多“以后可能用到”的interface,最后一次都没被调用过,但维护新人的时候要花半小时理解它为什么存在。
**规则三:Surgical Changes(精确手术式修改)**
针对附带修改。“touch only what you must”这句话很有分量——你碰到的每一行代码都是修改范围,不是你要修改的就不要碰。“clean up only your own mess”更直接:不要去整理别人的代码,即使你觉得它不够优雅。
用一个架构评审会的场景来类比:你来解决一个性能问题,不是来重构整个模块的。即使你顺手发现了三个可以优化的地方,正确做法也是先记下来,另开ticket,而不是塞进一个PR。理由很简单——review起来很困难,出了问题也不知道是哪行改的。
**规则四:Goal-Driven Execution(目标驱动执行)**
针对无验证完成。不说“做这件事”,而是说“做这件事,完成的标准是X,做完之后验证Y”。给出成功标准,给出验证步骤,而不仅仅是给出任务描述。
Karpathy在X上对这条规则的解释最为直白:“LLMs特别擅长循环直到满足条件为止。不要告诉它做什么,给它成功标准,看着它自己搞定。”
这四条规则,每一条都指向一个具体的失败模式,没有一条是泛泛的“写好代码”。这不是风格指南,而是故障修复手册。
为什么15万人star了这个文件
社区对这个文件的反应出乎意料地好。梳理一下原因,有几个层面。
**数据层面**:在30个代码库上的社区测试显示,没有CLAUDE.md时错误率约为41%,用了这四条规则后降到了11%,合规率约78%。这不是一个学术benchmark,而是X上一位叫Mnilax的开发者所做的开放实验,被Dickie Bush等人转发后广泛流传。数字可能有争议,但方向没有争议:少量精准的规则,比零规则有效得多。
**工程直觉层面**:四条规则每一条都能让工程师产生“对,就是这个问题”的共鸣。这不是AI优化技巧,而是Code Review里每周都在念叨的东西——只不过以前是对人说的,现在要对AI说。
**极简层面**:70行,人类可读,几秒钟就能扫一遍。“最好的CLAUDE.md随着时间推移会越来越短——你删掉那些事实上用不着的规则。”这句话本身就是一种设计哲学的体现。
你的CLAUDE.md为什么越写越烂
这才是最值得聊的部分。
“规则越多越好”是一个直觉上正确、逻辑上错误的判断。表面上看,每次Claude出问题你加一条规则,下次不就不出这个问题了?实际上并不是这么工作的。
**上下文窗口的稀释效应**
Claude处理CLAUDE.md的方式,不是“逐条检查是否违规”,而是在生成响应时把规则文件作为上下文权重的一部分。当你的规则文件有200行,每一条规则分配到的注意力权重就会降低一大半。
2025年Jaroslawicz等人的研究给出了一个残酷结论:“指令数量翻倍,合规率减半。”更直接的数据是:即使是最好的模型,在Agent场景里,完美遵守所有指令的任务也不超过30%。你有200条规则,Claude有效遵守其中60条,而且不是固定的那60条。
**防御性写法的副作用**
大多数工程师写CLAUDE.md的模式是这样的:发现Claude做了X → 加一条“不要做X”。这是响应式的、防御性的写法。问题在于,你不可能穷举所有的X,而且“不要做X”“不要做Y”“不要做Z”堆在一起,Claude要在这个“禁令列表”里工作,认知负担很高,反而可能导致它在“有没有违反某条禁令”这件事上花太多注意力,而不是在“把这个任务做好”这件事上。
**与Karpathy四条规则的本质区别**
Karpathy的四条规则不是禁令清单,而是行为框架。它们定义的不是“不准做什么”,而是“决策时的优先次序和工作方式”。
“Think before coding”不是“不准瞎写”,而是“先对齐再执行”。
“Simplicity first”不是“不准写复杂代码”,而是“默认选择最简解法”。
“Surgical changes”不是“不准动其他代码”,而是“你的范围只有这里”。
“Goal-driven execution”不是“必须写测试”,而是“定义验证标准,跑到标准满足为止”。
框架和禁令的区别,在于框架提供的是判断依据,禁令提供的是行为约束。判断依据让Claude在遇到新情况时知道怎么选,禁令只能管你已经见过的情况。
用架构的语言来说:禁令是blacklist,框架是principle。principle的复用性远高于blacklist。
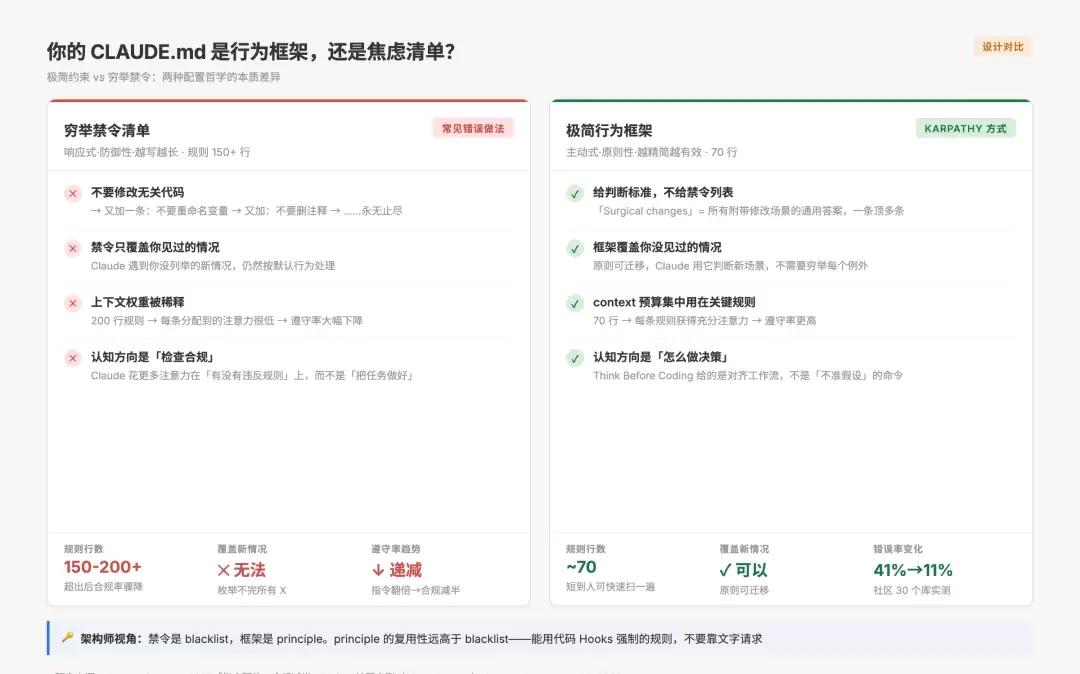
*图:框架式约束与禁令清单的本质区别*
如何审视你自己的CLAUDE.md
如果你现在有一个CLAUDE.md,用下面三个问题扫一遍:
**问题一:规则超过80行了吗?**
如果超过了,先压缩。把所有“不要做X”“禁止Y”的条目找出来,问自己:这条规则对应的是一个Claude的系统性行为问题,还是某一次的偶发事故?偶发事故的规则,没有保留价值。
**问题二:你的规则在说“禁止什么”还是“怎么做决策”?**
比较这两个写法:
写法A:“不要修改和任务无关的代码。不要重命名变量。不要删除注释。不要格式化代码。不要重构函数签名。”
写法B:“Surgical changes:只改任务要求的部分,不动其他任何东西,包括格式、注释和命名。”
写法A有五条规则,写法B只有一条。在实际效果上,写法B覆盖的情况更多,因为它给出的是判断标准,而不是列举清单。
**问题三:有没有可以被强制执行的规则,用了Hooks?**
有一类规则比CLAUDE.md更可靠:Hooks。Claude Code的Hooks是在特定Agent行为发生前后触发的脚本,它不依赖Claude读到规则、理解规则、决定遵守规则这一串概率链——它是代码强制的。
“每次生成代码后必须跑lint”——用Hook。
“提交前必须跑测试”——用Hook。
“修改配置文件前必须备份”——用Hook。
能用代码强制的事情,不要靠文字请求。CLAUDE.md的规则只能管它决定遵守的时候。
实测:用四条规则两周的真实感受
用Karpathy的四条规则工作了两周,说一下真实的体验。
最明显的变化是“啊这里有歧义”的频率提高了。以前发一个模糊的任务,Claude直接就跑了,跑完才发现方向不对。现在它会先说:我理解你的需求是A,基于这个前提我打算这样做,如果你的实际需求是B,我需要调整一下方向。这个“对齐确认”动作,节省的时间远比多发了一条消息要值。
变化二是diff干净了很多。同样是“修这个Bug”,以前的PR经常出现20个文件变更,其中15个是“顺带”的修改。用了Surgical Changes这条规则之后,diff基本就是你要求改的那几行。Code Review轻松了,出了问题也好回滚。
变化三是“任务完成”这件事变得更可信了。以前Claude说“好了”,你还是需要手动跑一遍测试。现在它会说“我跑了unit test,全部通过,也验证了edge case X和Y”。这虽然不是100%可靠,但比以前好多了。
需要老实说的是:这四条规则对于复杂的大型任务效果最明显,对于“帮我看一下这行代码有没有问题”这类小任务,它有时候会过度谨慎——先对齐再执行,结果你觉得它在“问废话”。规则要加,但不是所有场景都同样适用。
常见问题
**Q:这个CLAUDE.md只适合Claude Code吗?用Cursor或者Copilot有用吗?**
A:规则的内容适用于任何有类似context文件机制的工具。Cursor的.cursorrules、Windsurf的.windsurfrules里用同样的逻辑都有效果。但Claude Code在“Goal-Driven Execution”这条规则上受益最明显,因为它的Agent模式本身就支持循环执行直到条件满足。
**Q:Karpathy的四条规则能直接复制使用吗?需要修改吗?**
A:可以直接用,原仓库(github.com/forrestchang/andrej-karpathy-skills)里的CLAUDE.md是经过社区打磨的版本,比Karpathy在X上的原始描述更具体。建议先整体复制用两周,再根据你项目的具体情况微调。不建议一上来就大改——它的精简是有意为之的,你加的每一条规则都要想清楚“这条真的有必要吗,还是我只是想图个安心”。
**Q:规则文件超过80行就一定不好吗?**
A:不是绝对的。如果超过的部分是项目特定的技术约束(比如“这个项目用Spring Boot 3.x,不要用3.x废弃的API”),那是有必要的。但如果超过的部分是大量“不要做X”的禁令,特别是那些描述Claude通用行为倾向的规则,大概率在浪费context预算。一个有用的判断方法:把规则分成“通用行为框架”和“项目特定约束”两部分,通用行为框架保持简短,项目约束按需添加。
**Q:这四条规则会不会让Claude的速度变慢?**
A:Think Before Coding会增加一轮确认往返,在简单任务上确实多一步。但Goal-Driven Execution反过来会减少“以为做完了但其实没做完”的返工。总的来说,复杂任务的净效率是正向的,简单任务可以在prompt里加“直接执行,不需要确认前提”来跳过这步。
总结
说到底,CLAUDE.md是一个思维框架,而不是一个行为合规文件。Karpathy的四条规则胜在它告诉Claude“怎么做决策”,而不是“不准做什么”。
后者你永远列举不完,前者四条就够了。你的CLAUDE.md如果写得越来越长,大概率说明你在用第二种思路做第一种事。
写完这篇,我把团队的CLAUDE.md改了一遍,从160行压到了40行,主要删的都是那些“不要做X”的禁令。
跑了一周,差别比预期还明显。




