在刚刚过去的re:Invent 2023上,AWS甩出了一张新牌——Trainium2 AI训练引擎。这玩意儿一出场,关注度相当高。我们不妨试着从AWS实验室的Gadi Hutt那里扒了扒信息,再结合技术文档,试着把几个关键点拼凑起来,看看Trainium2到底是个什么来头,以及它与之前Inferentia系列之间到底藏着怎样的演进逻辑。
故事还得从2017年说起。那一年,AWS推出了Nitro DPU,之后一路迭代,又相继拿出了Gra viton Arm服务器CPU、Inferentia AI推理翻跟斗。这次Trainium2和Gra viton4一起亮相,信号很明显:AWS正在全面铺开自己的计算引擎版图。虽然详细的技术规格还不算特别透明,但借着与Gadi Hutt的交流,我们至少能把那些模糊的边界往前推一推。
从技术角度看,Trainium2的对手是谁?明眼人都知道,它瞄准的是Nvidia那款火到缺货、贵到离谱的Hopper H100。AWS的CEO Adam Selipsky在re:Invent上自己也说了,AWS已经采购了数百万颗Nvidia A100和H100。这投入不小。但与此同时,AWS又在搞自家的Titan模型,跑在自己研发的Inferentia和Trainium上。说白了,就是在两条腿走路:一边用别人的顶级货,一边养自己的亲儿子。从性价比的角度看,Trainium2要是真能跟H100掰手腕,那这一局就有的看了。
当然,定价从来不是简单的算术题。就像Gra viton系列Arm CPU那样,AWS一边卖着Intel和AMD的机器,一边用自己的Arm实例打价格战。省去中间商这一招,在AI芯片上很可能也会重演。Trainium2让AWS在AI计算引擎竞赛中又多了一张底牌——自主研发、持续迭代,这件事本身就意味着某种长期主义的胜利。
那么,Trainium2的架构到底是怎么长的?这得从它的家族谱系说起。
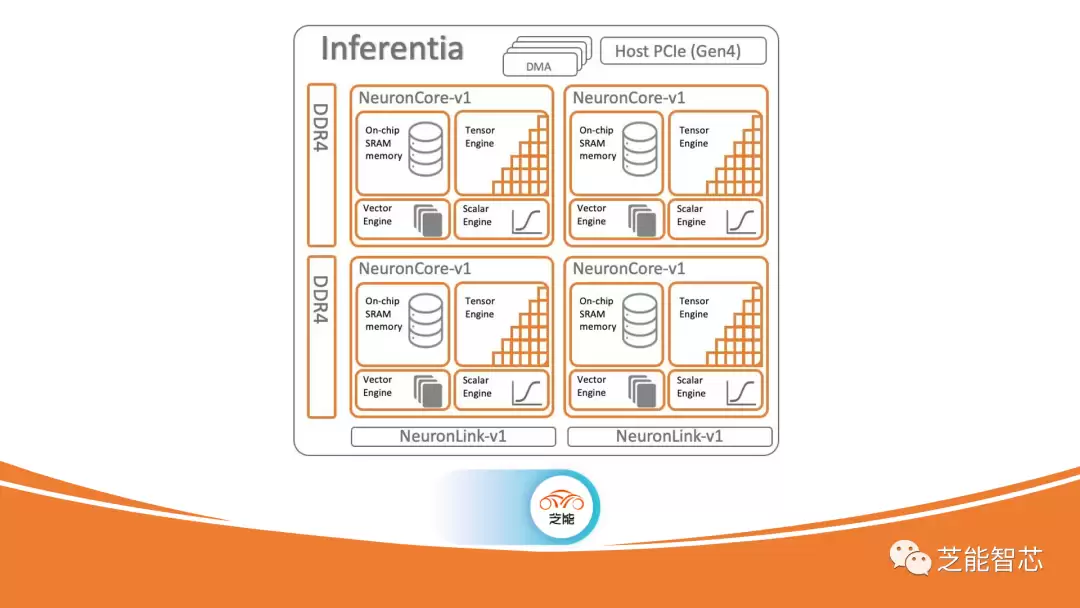
最早是2018年,Annapurna Labs团队拿出了Inferentia1。它里面有四个NeuronCore内核,每个核里都配了ScalarEngine和VectorEngine——你可以把它理解成Nvidia GPU里的CUDA核心。除此之外,还有专门加速矩阵运算的TensorEngine,对标的就是TensorCore。在FP16/BF16精度下,Inferentia1的单核性能是16 teraflops。
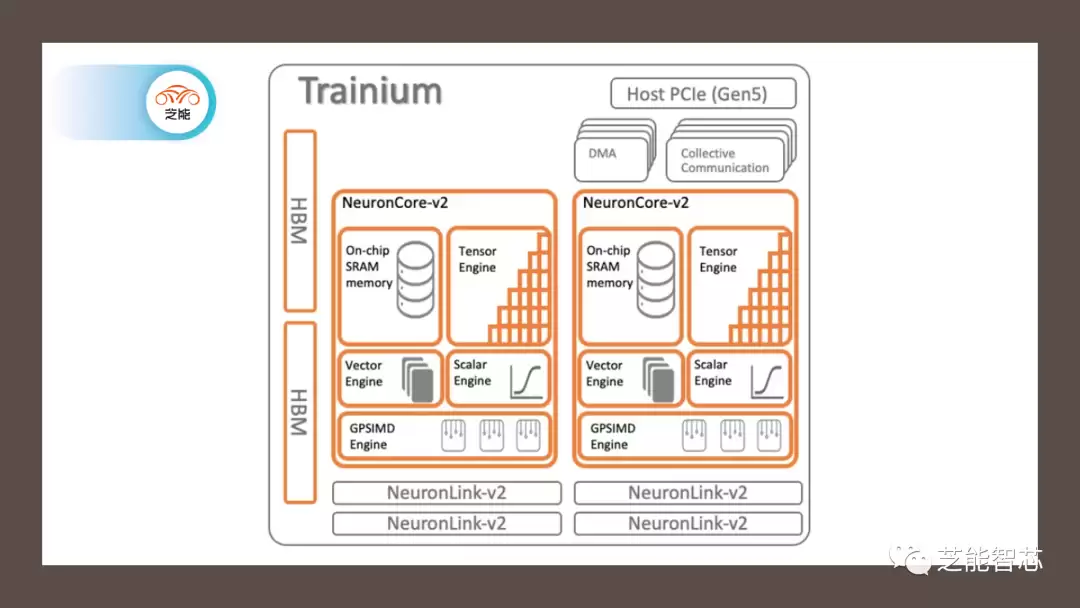
到了2020年,Trainium1登场。它换上了NeuronCore-v2核心,最大的变化是加上了32GB的HBM堆叠高带宽内存。有意思的是,Trainium1的核心数比Inferentia1少了,但每个核内部的标量、矢量、张量引擎数量都翻了倍。更特别的是,它引入了一个叫GPSIMD的通用处理器,可以直接用C和C++来编程——这个能力,放在当时算是一个不小的突破。
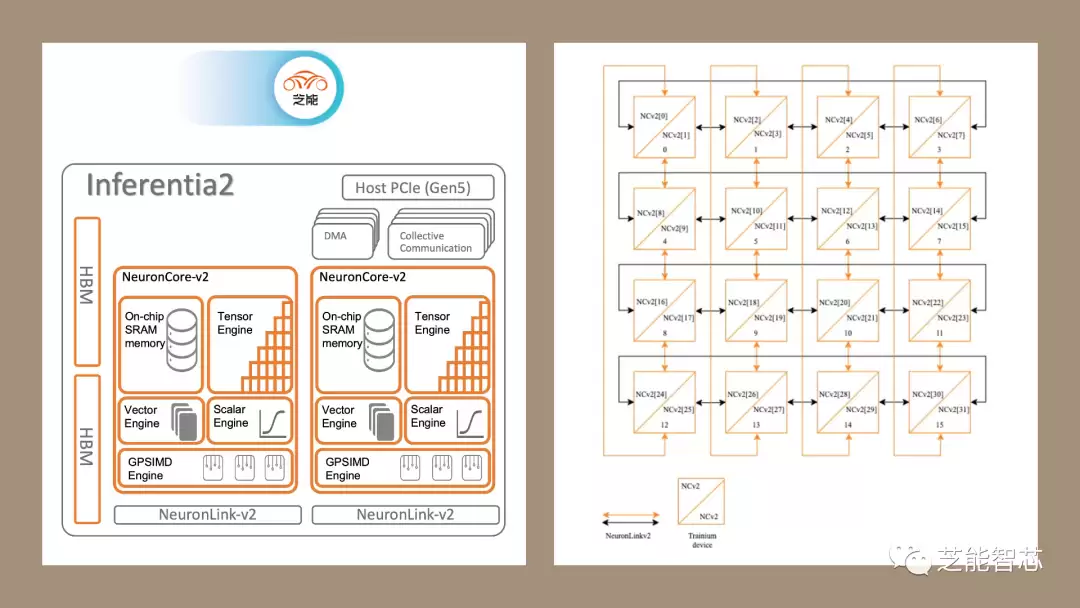
Inferentia2呢?它基本上就是Trainium1的一个变种,主要为了适配推理场景。保留了HBM带宽,但可能关掉了一些计算单元。它的NeuronLink-v2互连端口也比Trainium1少,整体架构跟Trainium1很接近,但做了针对性的“瘦身”。
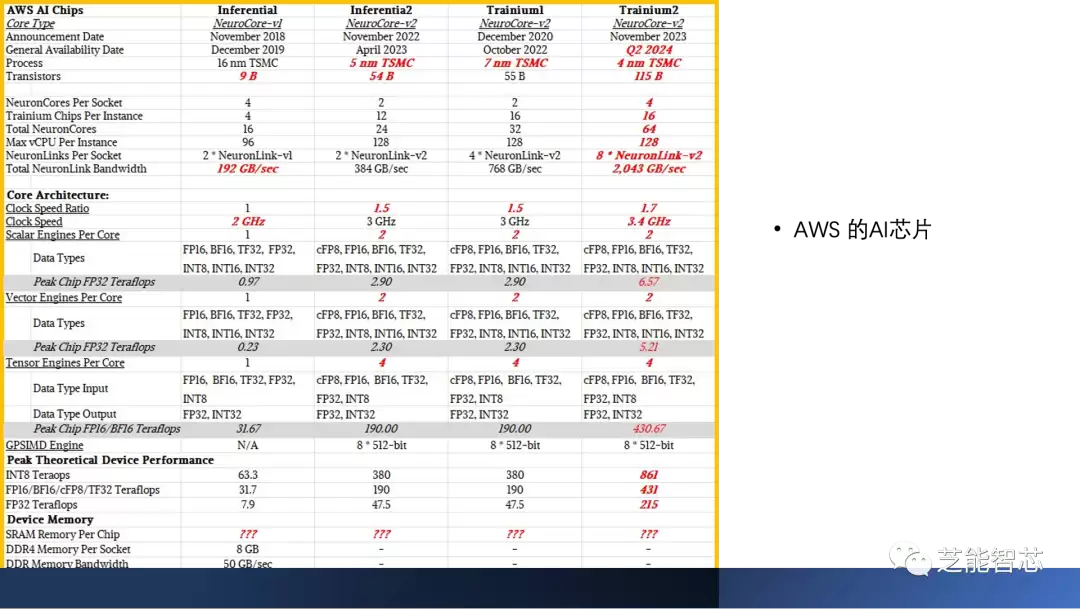
至于Trainium2,从现有信息来看,它很可能是把两个Trainium1芯片通过高速互连拼接在一起的产物——到底是做成单晶片,还是双芯片封装(MCM),现在还没有定论。但在计算、存储、网络这三大块上,它的继承和改进逻辑是非常清晰的:计算单元更强、带宽更高、互连更快。
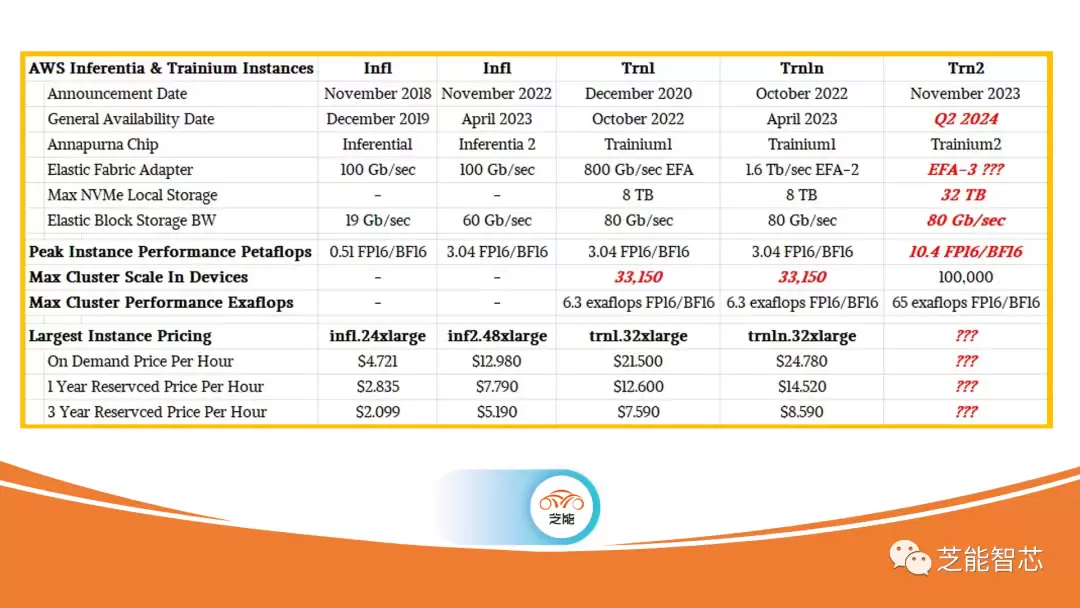
回顾整个系列,AWS在AI计算引擎上的演进路径其实很有章法:每一代产品都在前一代的基础上做加法,要么加内存、要么提带宽、要么增强计算密度。这种节奏,看着不激进,但步步为营。在AI算力市场越来越卷的今天,Trainium2究竟能打出多大的水花?我们等着看市场反馈就知道了。