边缘AI的热度,这几年一直居高不下。(我先说几个核心观察)对于在边缘端做推理的开发者来说,最大的压力往往来自两方面:一边是功耗和开发周期必须不断压缩,另一边要处理的算法却越来越重。现场可编程门阵列(FPGA)在很多场景下其实是相当理想的选择——它在速度和能效之间找到了一个很不错的平衡点。但问题也随之而来:很多做AI算法的团队并不熟悉FPGA,传统的那套开发流程实在太复杂了,最后往往只能退而求其次,选一个不太理想但门槛低的方案。
这篇文章要聊的,是Microchip Technology提供的一条简化路径。通过它们的FPGA和相关软件开发套件(SDK),开发者可以直接搭建已经训练好的神经网络(NN),或者用现成的FPGA视频开发套件快速上手智能嵌入式视觉应用——关键在于,全程不需要碰传统的FPGA开发流程。
为什么要在边缘使用AI?
边缘计算的好处已经得到了广泛的认可,特别是在物联网(IoT)应用领域,工业自动化、安全系统、智能家居等等都是它的主战场。拿工厂车间来说,在工业物联网(IIoT)场景下,边缘计算最大的价值就是绕开了数据往返云端的延迟,过程控制环路的响应时间可以大幅缩短。同样地,基于边缘的安全系统或者智能门锁,即使因为网络意外中断或者人为原因与云端断开连接,本地依然能照常工作。更重要的是,在很多场景里,只要用了边缘计算,就能减少甚至摆脱对云资源的依赖,整体运营成本自然就降下来了。随着产品要求越来越高,开发者其实可以靠产品本地的处理能力去维持一个更稳定的运营开支,而不是突然发现云资源费用失控了。
机器学习(ML)推理模型的快速普及,让边缘计算的分量更重了。对开发者来说,本地处理推理模型,既能降低响应延迟,也能省掉云端的推理开销。对用户来说,本地推理意味着即使偶尔断网、或者云服务的产品发生变化,设备依然能正常运行——这种可靠感是很值钱的。再加上安全和隐私方面的顾虑,越来越多的人倾向于把敏感数据限制在本地处理,而不是通过公共互联网传上云端。
开发一个基于视觉的物体检测NN推理模型,一般要分好几步。首先是在TensorFlow这类ML框架上做模型训练,通常会用到公开的或者自制的标注图像。训练这一步因为计算量巨大,往往得靠云端或者高性能计算平台上的图形处理单元(GPU)。训练完成之后,再把模型转换成能在边缘或者雾计算资源上跑的推理模型。最终输出的推理结果,本质上就是一组各类别的概率值(图1)。
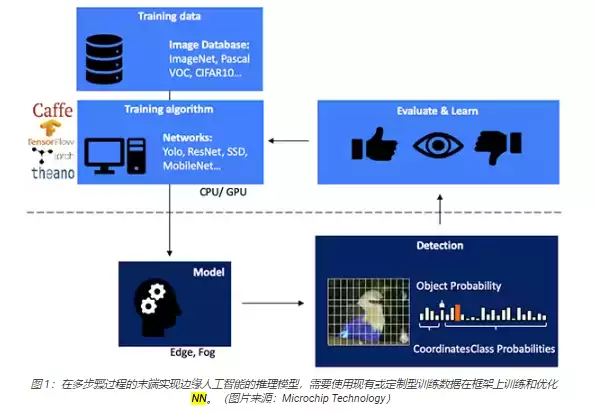
为什么推理模型存在计算方面的挑战
再说句大实话:虽然推理模型在大小和复杂程度上比训练时用的模型要低不少,但它对计算的要求依然不低,对通用处理器来说还是很有挑战的。一个典型的深层NN由很多层神经元组成。在全连接网络中,每一层的每个神经元nij,都得算一遍所有输入和对应权重系数wij的乘积之和(图2)。
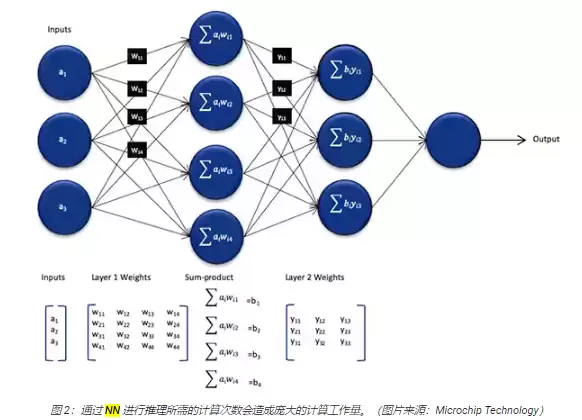
图2里还没把激活函数之类的东西算进去。激活函数会把负值映射成0,大于1的值映射成1,用来修正每个神经元的输出。每个神经元nij经过激活函数处理后的输出,就会作为下一层(i+1层)的输入,层层递进,直到输出层。最后,输出层生成一个向量,表示原始输入对应到监督学习中某一个类别(标签)的概率。
当然,实际工程里用的NN模型要比上面那种通用架构大得多、复杂得多。比如常用于图像对象检测的卷积神经网络(CNN),它会用分段的方式去处理这些原理,逐行扫描输入图像的宽度、高度和颜色深度,生成一系列特征图,最终形成一个输出预测向量(图3)。
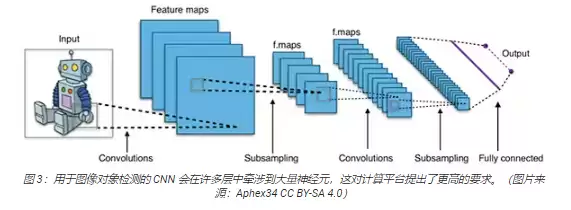
用FPGA加速NN数学
边缘推理的硬件方案其实不少,但能同时把灵活性、性能和能效做到位的,其实并不多。在现有的替代方案里,FPGA属于特别能打的那一类——它用硬件去执行计算密集型任务,性能强,功耗又相对低。
不过FPGA虽然优势明显,传统开发流程的门槛确实把不少开发者拦在了门外。要在FPGA上跑NN框架生成的模型,开发者得懂寄存器传输语言(RTL)、懂设计综合、懂最终审定,还得在具体设计阶段做好优化,一个环节都不能少(图4)。
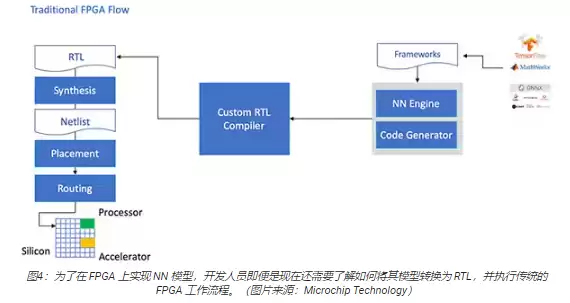
Microchip Technology提供的PolarFire FPGA,配合专门的软件和知识产权(IP)模块,给出了一条让没有FPGA经验的开发者也能轻松上手的路径。
PolarFire FPGA采用了先进的非易失性工艺技术,设计的初衷就是在保证灵活性和高性能的前提下,把功耗压到最低。除了大量用于通信和输入/输出(I/O)的高速接口,它内部还有很深厚的FPGA结构,能够通过软IP内核支持高级功能,比如RISC-V处理器、高级内存控制器和其他标准接口子系统(图5)。
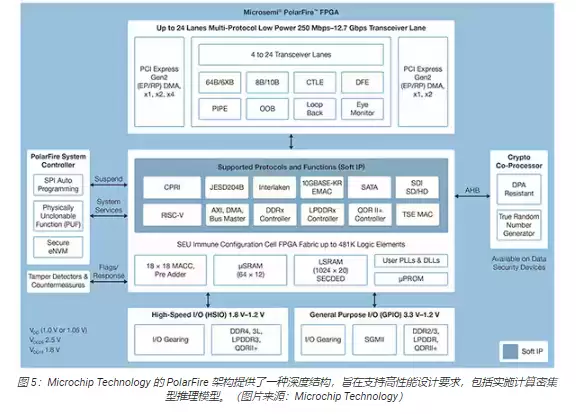
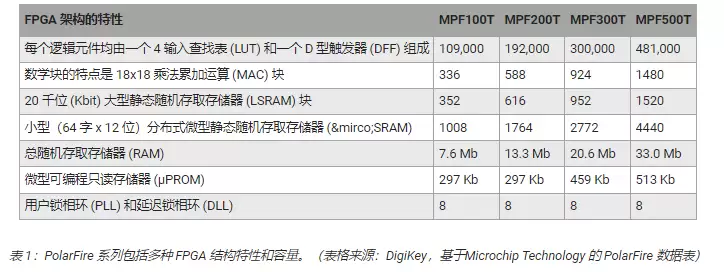
PolarFire FPGA架构里包含了一套完整的逻辑元件和专用功能块,不同型号的器件容量也不同,比如MPF100T、MPF200T、MPF300T和MPF500T系列(表1)。
说到推理加速,PolarFire架构里有一个很关键的专用数学块,它提供了一个带预加法器的18位×18位有符号乘法累加函数(MAC)。更巧妙的是,它还支持内置的点积模式,用一个数学块就能完成两个8位乘法运算。这里的基础知识是:利用模型量化对精度影响不大的特点,可以大大提升处理容量。
除了加快数学运算,PolarFire架构在缓解存储器拥堵方面也有考虑——比如用来暂存NN算法执行过程中产生的中间结果的那些小型分布式存储器。另外,NN模型的权重值和偏置值可以存储在位于数学块附近的只读存储器(ROM)里,深度16、宽度18位。
结合PolarFire FPGA的其他结构特性,这个数学块就构成了Microchip更高层次的CoreVectorBlox IP的基础。CoreVectorBlox是一个灵活的NN引擎,可以执行多种类型的NN。它包含三大部分:
- 微控制器:一个简单的RISC-V软处理器,从外部读取Microchip固件BLOB(二进制大对象)和用户定义的NN BLOB文件,通过执行固件BLOB中的指令来控制整体运算。
- 矩阵处理器(MXP):由8个32位算术逻辑单元(ALU)组成的软处理器,专门处理向量的并行运算,比如加法、减法、异或、移位、乘法、点积等,支持8位、16位和32位混合精度。
- CNN翻跟斗:利用数学块实现的二维MAC函数阵列来加速MXP的运算,精度为8位。
一个完整的NN处理系统,通常包括CoreVectorBlox IP块、存储器、存储器控制器,以及像微软RISC-V(Mi-V)这样的主机处理器(图6)。
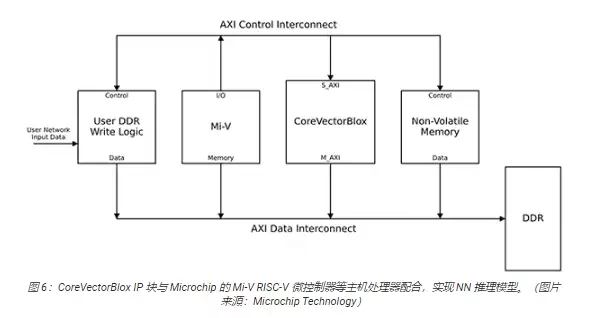
在视频系统里,主机处理器先从系统存储器里加载固件和网络BLOB,把它们复制到双数据速率(DDR)随机存取存储器(RAM)里,供CoreVectorBlox块使用。当视频帧到达时,主机处理器会把它写入DDR RAM,然后通知CoreVectorBlox块开始处理图像。推理模型执行完后,CoreVectorBlox块会把结果(包括图像分类)写回DDR RAM,供目标应用取用。
开发流程简化了NN FPGA实施
Microchip的做法,就是让开发者彻底绕开在PolarFire FPGA上实施NN推理模型的那些弯路。NN模型开发者不需要理会传统FPGA流程的细节,而是像往常一样先用自己的NN框架训练模型,然后把生成的模型丢进Microchip的VectorBlox翻跟斗软件开发套件(SDK)就行。SDK会自动生成一套需要的文件,包括传统FPGA流程里要用的文件,以及前面提到的固件和网络BLOB文件(图7)。
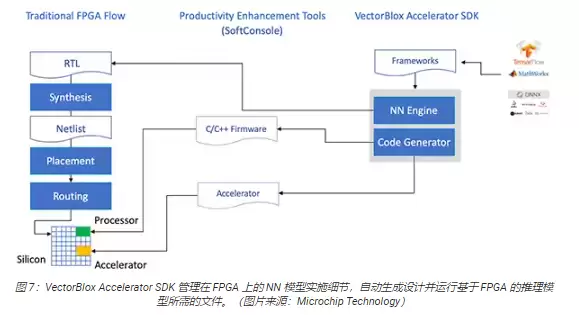
有意思的是,因为VectorBlox翻跟斗SDK把NN设计放在了FPGA中实现的NN引擎之上,所以不同的NN完全可以在同一个FPGA设计上轮番上阵,而不用重复做FPGA设计综合。开发者只需要为生成的系统写C/C++代码,就能在系统内快速切换模型,甚至可以用时间切片的方式同时跑多个模型。
VectorBlox翻跟斗SDK把Microchip的Libero FPGA设计套件和NN推理模型开发的整套功能融合在了一起。除了模型优化、量化和校准服务,SDK还提供了一个NN仿真器,让开发人员在真正在FPGA硬件上跑模型之前,就能用同样的BLOB文件先评估一把(图8)。
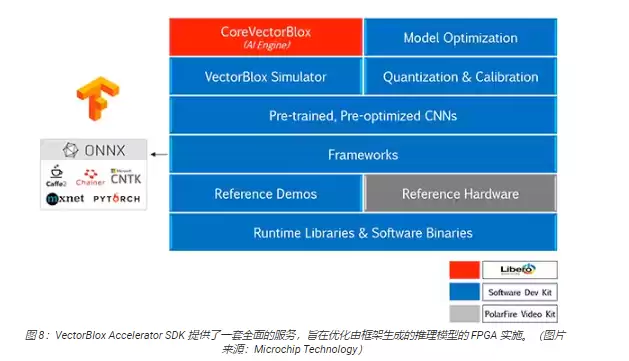
VectorBlox翻跟斗SDK支持开放神经网络交换(ONNX)格式的模型,同时也支持TensorFlow、Caffe、Chainer、PyTorch、MXNET等多种主流框架。在CNN架构方面,支持MNIST、MobileNet系列、ResNet-50、Tiny Yolo V2和Tiny Yolo V3。Microchip还在持续扩展支持范围,计划把OpenVINO工具包开放模型动物园里的大部分预训练模型都纳入进来,比如Yolo V3、Yolo V4、RetinaNet和SSD-MobileNet等。
视频套件演示FPGA推理
为了让开发者能更快地启动智能嵌入式视觉应用的开发,Microchip专门提供了一个完整的样例应用,这款应用是为它们的MPF300-VIDEO-KIT PolarFire FPGA视频和成像套件及参考设计而打造的。
这款套件基于Microchip的MPF300T PolarFire FPGA,板子上集成了双摄像头传感器、双数据速率4(DDR4)RAM、闪存、电源管理电路和各种接口(图9)。

套件附带了完整的Libero设计项目,用于生成固件和网络BLOB文件。把BLOB文件烧写到板载闪存后,开发者只需要在Libero里点一下“运行”按钮,演示就开始了——处理来自摄像头传感器的视频图像,推理结果直接显示在屏幕上(图10)。
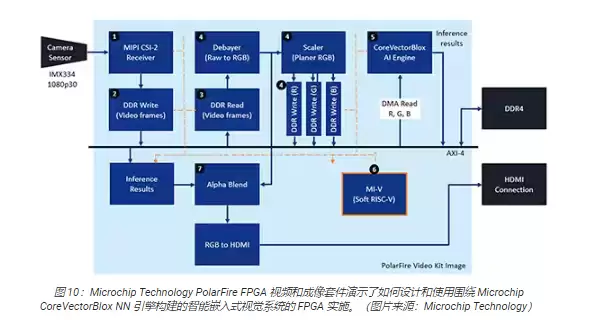
对于每一帧输入的视频,基于FPGA的系统会执行以下步骤(步骤编号与图10对应):
- 从摄像头中加载一帧画面
- 将帧存储到RAM中
- 从RAM中读取该帧
- 把原始图像转换成RGB格式,再平面化处理,最后将结果存回RAM
- Mi-V软RISC-V处理器启动CoreVectorBlox引擎,从RAM中取出图像做推理,再把分类概率结果存储回RAM
- Mi-V利用这些结果生成包含边界框、分类结果和其他元数据的叠加帧,并存入RAM
- 将原始帧与叠加帧混合,输出到HDMI显示屏
这套演示默认支持Tiny Yolo V3和MobileNet V2模型的加速。如果想跑其他SDK支持的模型,开发者只需要改少量代码,把模型名称和元数据加到现有的两个默认模型列表里就行。
结论
归根结底,像NN模型这样的人工智能算法,往往会给计算系统带来巨大的压力,通用处理器确实很难招架。FPGA本身在性能和低功耗上完全能胜任推理模型的执行要求,但传统的开发方法复杂得让人头疼,不少开发者最后只能退而求其次。不过,有了Microchip的专用IP和软件,没有FPGA经验的开发者也能做起基于推理的设计,而且性能、功耗和项目进度全都拿得下。