这是一道极具代表性的 Agent 面试题目。
"在 Agent 系统中,你们如何管理上下文?一旦上下文窗口溢出,又该如何应对?"
这个问题很容易回答得流于表面。
不少候选人上来就说:"我会用滑动窗口,把旧的对话裁掉。"
这句话对不对?
对,但太过简单。
因为 Agent 的上下文管理,绝非"裁掉旧消息"就能解决。裁多了会丢失关键信息,裁少了则成本急剧上升。而且 Agent 的上下文不仅仅包含对话历史——还有工具返回、检索文档、系统指令、中间推理步骤。
Agent 的上下文管理,不是仅仅靠一个滑动窗口就能撑住的。
真正落地的工程解法,需要从窗口分配、记忆分层、压缩策略、上下文编排到溢出兜底,进行全链路设计。
这篇文章,我们就把这个话题彻底讲透。
目录
先理清楚:Agent 里的上下文问题远不止一种整体思路:别指望一个滑动窗口搞定所有
第一层:窗口分配——先清楚上下文里都装了哪些内容
第二层:记忆分层——并非所有信息都值得留在窗口
第三层:压缩策略——信息太多时,如何"挤"进去
第四层:上下文编排——多步推理中如何防止上下文膨胀
窗口溢出了怎么办?
工程上如何长期治理上下文
面试时该如何作答
一、先理清楚:Agent 里的上下文问题远不止一种
面试官问"上下文怎么管理",别一开口就提"滑动窗口"。
先把上下文问题拆明白。
因为不同类型的上下文问题,根因不同,解法也各不相同。
1. 窗口容量不足
这是最直观的问题:上下文窗口就那么大,但需要塞进去的内容实在太多。
比如你给 Agent 接入了三个工具,每个工具返回 2000 token 的结果,加上 1000 token 的系统指令,再加上 2000 token 的对话历史,单次调用就消耗 9000 token。多来几轮,窗口直接爆掉。
这个问题的本质不是"窗口太小",而是"你塞了太多不该塞的东西"。
2. 关键信息被淹没
窗口没爆,但模型"忘了"重要信息。
比如用户在第 2 轮说:"我叫张三,订单号是 ORD-2024-001。"到第 8 轮模型却回答:"请问您的订单号是什么?"
用户心态直接炸了。
这类问题被称为"Lost in the Middle"——模型对窗口中间位置的信息关注度天然低于开头和结尾。
窗口没溢出,但信息已经丢失了。
3. 工具返回撑爆上下文
Agent 调用工具后,工具返回了 5000 token 的结构化数据。
其中 80% 的字段与当前任务无关,却全被塞进了上下文。
下一轮模型调用时,这些噪声数据占据着位置,真正有用的信息反而被挤了出去。
4. 多步推理导致的上下文膨胀
Agent 规划了 5 步,每一步的 Thought → Action → Observation 都留在上下文里。
到第 4 步时,上下文已经膨胀到原来的 3 倍。
更要命的是,前几步的错误推理过程也留在里面,模型看着自己之前的错误继续推理,越跑越偏。
5. 多轮对话的"记忆断裂"
用户跟 Agent 聊了 20 轮,前 5 轮聊产品功能,中间 10 轮聊部署方案,后 5 轮聊价格。
当用户回到产品功能时,Agent 已经完全不记得前面聊过什么了。
这不是窗口不够用的问题,而是缺少跨 session 的持久记忆机制。
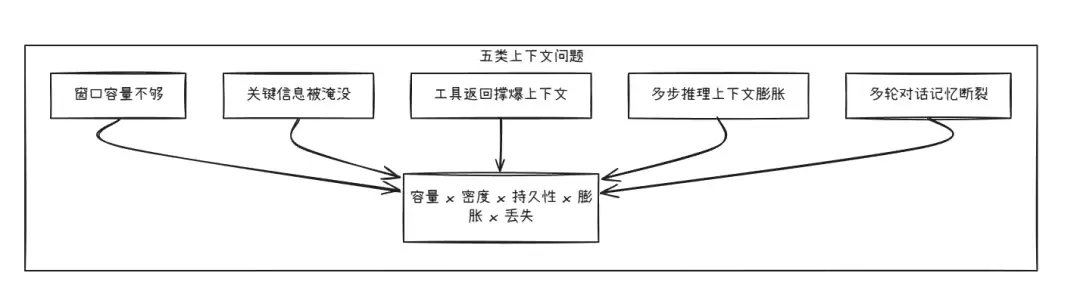
因此,Agent 的上下文管理不能只说"窗口不够"。
更准确的说法是:Agent 的上下文管理是窗口容量、信息密度、记忆持久性、多步膨胀和信息丢失这五类问题的综合工程。
二、整体思路:别指望一个滑动窗口搞定所有
管理 Agent 上下文,不能只靠裁旧消息。
滑动窗口要不要用?
当然要。
但滑动窗口只是最粗浅的一层,并非全部。
真正落地的工程方案至少包含四层:
窗口分配:明确上下文里装了什么,每一部分分配多少配额记忆分层:将信息划分为工作记忆、短期记忆、长期记忆,不同层级采用不同策略
压缩策略:信息过多时,通过摘要、裁剪、结构化等方式提升信息密度
上下文编排:在多步推理中,管控每步塞入上下文的内容,防止膨胀
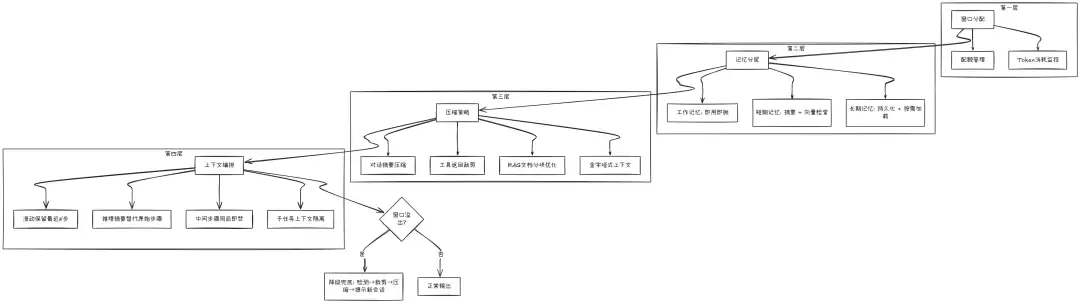
这四层解决的问题各不相同。
窗口分配解决的是"每一部分该占多少位置"。
记忆分层解决的是"什么信息该留在窗口,什么该存到外部"。
压缩策略解决的是"如何在有限空间里装入更多有用信息"。
上下文编排解决的是"多步推理中如何不让上下文越来越臃肿"。
面试时能说出这四层,基本就比只会说"滑动窗口"的候选人高一档。
三、第一层:窗口分配——先清楚上下文里都装了哪些内容
滑动窗口可以裁旧消息,但你得先知道上下文里到底装了些什么。
很多人调 Agent 时只写 Prompt,从来不看每一轮实际消耗了多少 token。
这就是在瞎调。
上下文到底长什么样
一次典型的 Agent 调用,上下文里通常包含这些内容:
[System Prompt] 固定开销,200-1000 token
[对话历史] 逐轮增长,每轮 200-1000 token
[工具定义] 每个工具 100-500 token
[当前轮工具返回] 每次调用 100-5000 token
[RAG 检索文档] 每次检索 500-3000 token
[中间推理步骤] 每步 100-500 token
[用户当前输入] 50-500 token
你看,上下文根本不是"对话历史"这么单一。
一次完整的 Agent 调用,上下文里有六七种不同类型的内容。
先做配额管理
工程上第一步不是裁消息,而是为每一部分设定配额。
比如:
总窗口:128K token
System Prompt:≤ 2K(1.5%)
工具定义: ≤ 5K(3.9%)
对话历史: ≤ 32K(25%)
RAG 检索文档: ≤ 40K(31%)
工具返回: ≤ 32K(25%)
当前输入 + 推理: ≤ 17K(13.6%)
配额不是拍脑袋定的,要根据你的实际场景来:
知识库问答场景:RAG 检索文档配额要大工具调用密集场景:工具返回配额要大
长对话场景:对话历史配额要大
监控实际消耗
光有配额不够,还要做监控:
// 每轮调用后记录各部分的 token 消耗
type ContextUsage struct {
SystemPromptTokens int
ToolDefTokens int
HistoryTokens int
RAGDocTokens int
ToolResultTokens int
InputTokens int
TotalTokens int
WindowLimit int
}
func logContextUsage(usage ContextUsage) {
usagePercent := float64(usage.TotalTokens) / float64(usage.WindowLimit) * 100
log.Info("上下文使用情况",
"total", usage.TotalTokens,
"limit", usage.WindowLimit,
"percent", fmt.Sprintf("%.1f%%", usagePercent),
"history", usage.HistoryTokens,
"rag_docs", usage.RAGDocTokens,
"tool_results", usage.ToolResultTokens,
)
if usagePercent > 80 {
log.Warn("上下文即将溢出,触发压缩策略",
"percent", fmt.Sprintf("%.1f%%", usagePercent))
}
}
有了这个监控,你才能知道问题出在哪一部分——是对话历史太多?还是工具返回太大?还是 RAG 文档太啰嗦?
不看数据就调上下文,跟不看仪表盘开车一样危险。
四、第二层:记忆分层——并非所有信息都值得留在窗口
上下文窗口是稀缺资源。
稀缺资源就不能什么都往里塞。
工程上常见的做法是将记忆分成三层:
工作记忆(Working Memory)
当前任务直接相关的信息,放在窗口里。
比如用户这一轮的输入、当前工具调用的返回、相关度最高的 RAG 文档。
这部分信息"即用即抛",任务完成后就可以清理。
短期记忆(Short-term Memory)
跨轮次但同一 session 内需要记住的信息。
比如用户的名字、当前对话的主题、之前已经确认过的决策。
这部分信息不适合一直占着窗口,但也不能丢掉。做法是:
用摘要(Summarization)把历史对话压缩成结构化摘要摘要放在 system prompt 或窗口开头位置
当需要细节时,用向量检索从完整历史中找回
// 短期记忆:摘要 + 向量检索
type ShortTermMemory struct {
Summary string // 对话摘要,始终在窗口里
RawHistory []Message // 完整历史,存在外部
VectorStore *VectorStore // 向量存储,用于语义检索
}
// 每 N 轮触发摘要更新
func (m *ShortTermMemory) UpdateSummary(ctx context.Context, newMessages []Message) {
m.RawHistory = append(m.RawHistory, newMessages...)
// 用 LLM 生成对话摘要
summaryPrompt := fmt.Sprintf("请用 200 字以内总结以下对话的关键信息(用户身份、核心需求、已确认事项):%s",
formatMessages(m.RawHistory),
)
m.Summary = callLLM(ctx, summaryPrompt)
// 同时把原始消息存入向量库,方便后续检索细节
for _, msg := range newMessages {
m.VectorStore.Insert(ctx, msg.Content, msg.Metadata)
}
}
长期记忆(Long-term Memory)
跨 session 需要持久化的信息。
比如用户的偏好设置、历史订单、常用地址。
这部分信息存在数据库里,需要时检索出来放进上下文。
// 长期记忆:持久化存储 + 按需检索
type LongTermMemory struct {
DB *sql.DB
}
type UserProfile struct {
UserID string
Preferences map[string]string // {"语言": "中文", "风格": "简洁"}
History []string // 最近交互的关键主题
LastUpdated time.Time
}
func (m *LongTermMemory) LoadUserContext(ctx context.Context, userID string) *UserProfile {
profile := m.loadFromDB(ctx, userID)
// 只把当前任务相关的偏好注入上下文
return profile
}
三层记忆的核心逻辑是:窗口里只放当前最需要的信息,其他信息存在外面,需要时再检索回来。
这跟人脑的工作方式一样——你不会把所有记忆都同时放在脑子里,而是需要什么回忆什么。
五、第三层:压缩策略——信息太多时,如何"挤"进去
记忆分层是把信息挪出去。但有时候你就是需要把大量信息塞进窗口。
这时候就得"压缩"——提升信息密度。
策略一:对话摘要压缩
不是把对话历史全裁掉,而是用 LLM 把历史压缩成摘要。
但这里有个坑:摘要会丢失细节。
所以更好的做法是"摘要 + 关键消息保留":
[系统指令] ← 始终保留
[对话摘要] ← 压缩旧消息
[最近 3 轮完整对话] ← 保留最新交互的细节
[用户当前输入]
摘要兜底全局上下文,最近几轮保留细节。这样既有全局视野,又不丢当前交互的精度。
策略二:工具返回裁剪
工具返回 5000 token,里面 80% 是无关字段。
那就别全塞进去。
// 工具返回只保留关键字段
type ToolResultFilter struct {
KeepFields []string // 只保留这些字段
MaxLength int // 最大 token 数
}
func (f *ToolResultFilter) Filter(rawResult string) string {
// 方案一:只提取需要的 JSON 字段
var data map[string]any
json.Unmarshal([]byte(rawResult), &data)
filtered := make(map[string]any)
for _, field := range f.KeepFields {
if v, ok := data[field]; ok {
filtered[field] = v
}
}
result, _ := json.Marshal(filtered)
// 方案二:如果还是太长,让 LLM 做二次提炼
if countTokens(string(result)) > f.MaxLength {
result = []byte(callLLM(context.Background(),
fmt.Sprintf("从以下数据中提取与当前任务最相关的信息,不超过 %d token:%s",
f.MaxLength, string(result))))
}
return string(result)
}
策略三:RAG 文档分块策略
很多人做 RAG 时把 chunk_size 设得很大,觉得"多塞点信息模型能答得更好"。
错了。
chunk 太大,噪声多,有效信息密度低,还占窗口。
更好的做法是:
小 chunk 召回(256-512 token),提升检索精度大 chunk 扩展:检索到小 chunk 后,把它前后的上下文也带上
只把最相关的 Top-3 给模型,不要 Top-10 全塞
// RAG 文档注入策略
func injectRAGDocs(ctx context.Context, query string, retriever *Retriever) string {
// 第一步:小 chunk 召回 Top-10
smallChunks := retriever.Search(ctx, query, 10, 256)
// 第二步:Rerank,只保留 Top-3
reranked := rerank(ctx, query, smallChunks, 3)
// 第三步:扩展为大 chunk
var docs []string
for _, chunk := range reranked {
expanded := retriever.ExpandContext(ctx, chunk.ID, 1024)
docs = append(docs, expanded)
}
return formatDocs(docs)
}
策略四:结构化压缩
如果你需要 Agent 处理超长文档(比如一份 100 页的合同),别把全文塞进去。
做法是:
离线预处理:先把文档拆成章节,每章生成摘要在线检索:用户提问时,先检索相关章节
逐层展开:先给 Agent 章节摘要,需要细节时再展开具体内容
这叫"金字塔式上下文"——先给概览,按需展开。
六、第四层:上下文编排——多步推理中如何防止上下文膨胀
前面三层解决的是"怎么塞"的问题。这一层解决的是"多步推理中上下文越来越胖"的问题。
Agent 在做多步推理时,每一步的 Thought → Action → Observation 都会留在上下文里。
5 步下来,上下文可能膨胀 3-5 倍。
更关键的是:前几步的错误推理也留在里面,影响后续判断。
策略一:滑动窗口只保留最近 N 步
最直接的做法:
保留:
- System Prompt(始终保留)
- 对话摘要(始终保留)
- 最近 3 步推理过程(滑动)
- 当前步骤
丢弃:
- 第 4 步之前的推理细节
但这有个问题:如果第 1 步获取的关键信息第 5 步还需要,丢掉了就出问题。
策略二:推理摘要替代原始步骤
不保留每一步的完整 Thought → Action → Observation,而是每步完成后生成一个推理摘要:
type ReasoningStep struct {
StepNum int
Summary string // "第1步:查询了北京天气,结果为晴天 25°C"
KeyFacts []string // ["北京今天晴天", "温度 25°C", "风力 3 级"]
RawThought string // 仅保留在外部存储,不放入窗口
}
func (s *ReasoningStep) Compress(rawThought, rawAction, rawObservation string) {
// 用 LLM 生成推理摘要,只保留关键事实
s.Summary = callLLM(context.Background(),
fmt.Sprintf("用一句话总结这一步做了什么、得到了什么关键信息:思考:%s 行动:%s 观察:%s",
rawThought, rawAction, rawObservation))
s.KeyFacts = extractKeyFacts(rawObservation)
}
这样,5 步推理过程从 5000 token 压缩到 500 token,关键信息还在。
策略三:中间步骤"阅后即焚"
对于一些不产生持久信息的中间步骤,直接不入上下文。
比如 Agent 调了一个"获取当前时间"的工具,返回 2025-05-28 14:30:00。
这个时间下一轮就用不上了,没必要一直占着窗口。
做法是标记哪些工具返回是"持久信息",哪些是"瞬态信息":
type ToolDef struct {
Name string
Persistent bool // true: 结果保留在上下文;false: 阅后即焚
}
var toolRegistry = []ToolDef{
{Name: "search_knowledge_base", Persistent: true}, // 知识库结果要保留
{Name: "get_current_time", Persistent: false}, // 时间信息阅后即焚
{Name: "query_order", Persistent: true}, // 订单信息要保留
{Name: "calculate", Persistent: false}, // 中间计算阅后即焚
}
策略四:任务分解 + 子上下文
如果一个任务需要 10 步推理,别让一个 Agent 从头做到尾。
拆成 3 个子任务,每个子任务有自己独立的上下文:
主 Agent:拆解任务,分配子任务,汇总结果
├── 子 Agent 1:信息收集(独立上下文,完成后只返回摘要)
├── 子 Agent 2:分析推理(独立上下文,完成后只返回结论)
└── 子 Agent 3:生成回复(独立上下文,只接收前面的摘要)
每个子 Agent 只看到跟自己相关的上下文,不会看到前面所有步骤的冗余信息。
这叫"上下文隔离"——复杂任务拆成多个子任务,每个子任务有独立的上下文空间。
七、窗口溢出了怎么办?
这是面试官最喜欢追问的地方。
因为现实里不管你设计得多好,窗口溢出总会发生。
你不能说:"我设计得很好,不会溢出。"
这句话太假了。
更好的回答是:我承认溢出无法 100% 避免,所以系统要有检测、降级、重试和兜底机制。
1. 先检测
溢出不一定是窗口 100% 用满。
当你发现:
上下文使用率超过 80%工具返回异常大(超过预设阈值)
推理步骤超过预设上限
连续两轮 token 消耗增速异常
这些信号出来的时候,就要触发干预,不要等模型报错。
2. 再降级
检测到溢出风险后,按优先级逐层降级:
第一优先级:裁剪工具返回。把工具返回的非关键字段砍掉,只保留核心信息。
第二优先级:压缩对话历史。把旧消息替换为摘要,只保留最近 3 轮完整对话。
第三优先级:减少 RAG 文档。从 Top-5 降到 Top-2,或减小扩展 chunk 的大小。
第四优先级:简化系统指令。去掉非核心的 Prompt 规则,只保留最关键的限制。
第五优先级:终止当前任务。告诉用户"当前对话较长,建议开启新会话继续"。
// 上下文溢出降级策略
func handleContextOverflow(ctx context.Context, usage ContextUsage) (*Response, error) {
strategies := []OverflowStrategy{
{Name: "裁剪工具返回", Priority: 1, Action: trimToolResults},
{Name: "压缩对话历史", Priority: 2, Action: compressHistory},
{Name: "减少RAG文档", Priority: 3, Action: reduceRAGDocs},
{Name: "简化系统指令", Priority: 4, Action: simplifySystemPrompt},
{Name: "提示新会话", Priority: 5, Action: suggestNewSession},
}
for _, s := range strategies {
newUsage := s.Action(ctx, usage)
if newUsage.TotalTokens <= usage.WindowLimit {
log.Info("溢出降级成功", "strategy", s.Name,
"before", usage.TotalTokens, "after", newUsage.TotalTokens)
return retry(ctx, newUsage)
}
}
// 所有策略都失败,降级为提示用户
return &Response{
Content: "当前对话内容较多,建议您开启新会话继续。我会保留本次对话的关键信息。",
NeedNewSession: true,
}, nil
}
3. 溢出后的恢复
如果最终还是溢出了,不要直接报错让用户看到。
至少要做:
保留对话摘要,新 session 可以继续告诉用户哪些信息被保留了、哪些可能丢失了
给用户一个"重新开始但保留关键上下文"的选项
八、工程上如何长期治理上下文
线上兜底只能止血。
真正要把上下文管理做好,还得做长期治理。
1. 先看数据
不看数据就是盲调。至少监控这些指标:
平均上下文使用率:正常流量下窗口用了多少溢出率:多少比例的请求触发了溢出降级
压缩触发率:多少比例触发了对话压缩
信息丢失率:用户重复提问的比例(说明模型"忘了")
平均推理步数:多步推理平均几步,是否在增长
每步 token 增量:每增加一步,上下文膨胀多少
这些指标不是为了写周报,是为了告诉你问题出在哪。
2. 建立上下文预算
给每类 Agent 任务建立上下文预算:
任务类型 |
上下文预算 |
推理步数上限 |
工具调用上限 |
|---|---|---|---|
简单问答 |
8K |
1 |
0-1 |
知识库检索 |
32K |
1-2 |
0-1 |
工具调用 |
64K |
3-5 |
2-5 |
复杂推理 |
128K |
5-10 |
3-8 |
预算不是限制,是帮你发现异常的基线。
当某个任务的上下文消耗远超预算时,说明要么任务复杂度变了,要么系统哪里出问题了。
3. 把溢出 case 加入回归测试
每次上下文溢出的事故,都要归因:
是工具返回没有裁剪?是 RAG 文档分块太大?
是摘要策略失效?
是推理步骤没有压缩?
归因之后,把这次 case 加入 eval 集。每次改上下文策略,都要跑回归。
4. 分场景差异化策略
不是所有 Agent 都需要重上下文管理:
闲聊客服:轻量策略,滑动窗口 + 简单摘要就够了知识库问答:重点优化 RAG 文档注入策略
数据分析 Agent:重点管理工具返回和中间推理
长文档处理:金字塔式上下文 + 子任务隔离
多轮决策 Agent:三层记忆 + 推理摘要
安全等级要跟风险匹配,上下文策略要跟场景匹配。
九、面试时该如何作答
面试官问"Agent 系统如何管理上下文,如果窗口溢出怎么办",不要只说"我用滑动窗口"。
要体现你知道上下文管理的层次、策略和兜底。
参考回答思路:
"我不会只靠滑动窗口管理上下文。Agent 的上下文管理要分层来做。
第一层是窗口分配。先搞清楚上下文里装了什么——system prompt、对话历史、工具返回、RAG 文档、推理步骤,每一部分设配额,然后监控实际消耗。不看数据就调上下文是盲调。
第二层是记忆分层。把信息分成工作记忆、短期记忆、长期记忆三层。窗口里只放当前最需要的信息,其他存到外部。短期记忆用'摘要 + 向量检索'——摘要放在窗口里兜底全局,需要细节时从向量库检索原始历史。长期记忆持久化到数据库,按需加载。
第三层是压缩策略。对话历史用摘要压缩代替全量保留;工具返回只保留关键字段,非核心信息裁剪;RAG 文档用小 chunk 召回 + Rerank + 大 chunk 扩展,只给模型最相关的 Top-3;超长文档用金字塔式上下文——先给摘要,按需展开。
第四层是上下文编排。多步推理中,每步只保留推理摘要而非原始 Thought → Action → Observation,中间步骤标记'阅后即焚',复杂任务拆成子 Agent 各自独立上下文。
如果这些策略之后窗口还是溢出,不能直接报错。先检测——上下文使用率超过 80% 就预警;再降级——按优先级逐层裁剪:先裁工具返回、再压缩历史、再减少 RAG 文档、最后简化 Prompt;如果还是溢出,降级为提示用户开新会话,同时保留对话摘要。
长期治理要监控上下文使用率、溢出率、信息丢失率,建立上下文预算基线,把溢出 case 加入回归测试,分场景采用不同的上下文策略。"
这个回答的重点不是承诺"Agent 上下文永远够用"。
而是告诉面试官:我知道上下文一定可能不够用,所以我有分层管理、压缩策略和溢出兜底。
这才是生产系统的思路。
上下文管理是做 Agent 的第一道坎。过了这道坎,你的 Agent 才能从 demo 走向生产。




