最近被问到最多的问题,就是关于 Agent 开发的转型路径。后台的私信大致能分成这几类:
有 Ja va、Python 的后端同学,觉得传统业务开发越来越卷,想看看 Agent 方向有没有机会;
有已经能调 API、跑得通 Demo 的同学,但感觉自己始终在“拼积木”,找不到进阶的入口;
还有产品、运营背景的朋友,想跨界切入这个领域,却不知道从哪里开始。
聊得多了就会发现,这其实是一个比较普遍的困惑。索性把思路系统地梳理一下,希望能对更多人有些启发。
这篇文章会讲清楚三件事:
第一,传统开发转 Agent 开发,最大的挑战到底是什么?
第二,如何高效完成这场转型——从“会用”到“会做”,具体需要学些什么、怎么学?
第三,基础打牢之后,真正的进阶要突破哪些关键点?
先说一个比较核心的判断:传统开发转 Agent 开发,最大的挑战并不在于技术本身的新奇,而在于思维方式的转变——从“确定性编程”切换到“概率性编程”。而“三刷”官方文档,是经过验证的、能够高效掌握新技术的办法。下面会用 langchaingo 的文档作为一个具体的演示案例。具体来说:
1 刷(1-2 天):从头看到尾,建立整体的认知地图,扫清楚所有概念盲点;
2 刷(3-5 天):动手跑通每一个代码示例,做好注释和阶段性总结,做到“看得懂、跑得通”;
3 刷(2-3 天):只保留自己写的注释,不看文档独立实现一遍,遇到卡点再回头对照原文,最终形成“肌肉记忆”。
推荐的学习路线和免费资源,下文会有详细说明。入门阶段:langchaingo 官方示例 → 吴恩达《Building Systems with the ChatGPT API》免费课程 → 动手做一个 RAG 问答机器人。进阶阶段:向量数据库(ChromaDB / Milvus)→ Prompt Engineering 指南 → Eino / langchaingo 工作流编排。高阶阶段:Multi-Agent 架构设计 → Agent 工程化实践 → Go + Python 混合架构。
至于更远的进阶方向,核心在于深入理解 Multi-Agent 架构和 Agent 工程化。这些内容会通过 Mermaid 架构图来直观展示,让大家先有一个明确的目标方向。
好了,直接进入正文,看看这些经验能不能给你带来一些启发。
传统开发思维 vs Agent 开发思维
无论是后端转 Agent,还是前端转 Agent,在有编程基础的前提下,学习新的技术栈本身并不会构成真正的障碍。
对于有基础的同学来说,学 Agent 开发,本质上也就是这几件事:学会调用 LLM API、理解工具调用的机制、掌握一个框架的基本用法。如果方法得当、投入专注,两周内跑通第一个项目是完全可行的。
那么,真正的挑战到底在哪里?
传统开发思维
传统开发的逻辑是确定性的。来看一个很简单的例子——实现“查询天气并判断是否适合户外运动”:
``` // 传统开发:确定性逻辑 func CheckOutdoorActivity(city string) string { weather := GetWeatherAPI(city) // 一定返回 {Temp, Weather, Wind} switch weather.Weather { case "晴": if weather.Temp >= 15 && weather.Temp <= 35 { return "适合户外运动" } return "温度不适宜" case "阴": return "可以做户外运动,但要注意天气变化" default: return "不适合户外运动" } } // 输入"北京",每次运行结果完全一致 // 出了问题,断点调试一路跟下去就行 ```这就是我们熟悉的编程方式:输入 A,输出 B,逻辑可预测,bug 可追踪。每一条分叉都清晰明了。
Agent 开发思维
同样的需求,如果用 Agent 来写,情况就完全不同了:
``` // Agent开发:概率性逻辑 // 使用 Go 版 LangChain: github.com/tmc/langchaingo import ( "github.com/tmc/langchaingo/agents" "github.com/tmc/langchaingo/tools" "github.com/tmc/langchaingo/llms/openai" ) // 定义工具:查询天气 func getWeatherTool() tools.Tool { return tools.GenericTool{ Name: "get_weather", Description: "查询指定城市的天气,返回温度、天气状况、风力", Run: func(ctx context.Context, input string) (string, error) { return weatherAPI(input), nil }, } } llm, _ := openai.New(openai.WithModel("gpt-4o")) toolList := []tools.Tool{getWeatherTool()} systemPrompt := `你是一个户外运动顾问。根据用户提供的城市天气,判断是否适合户外运动。 判断规则: - 晴天、温度15-35度:适合 - 阴天:可以,但需注意 - 雨天/大风/高温/低温:不适合 请给出判断并解释原因。` agent := agents.NewOpenAIFunctionsAgent(llm, toolList) executor := agents.NewExecutor(agent) result, _ := executor.Call(ctx, map[string]any{ "input": "北京天气怎么样?", }) // 同样输入"北京",可能出现: // 第1次:"北京今天晴天,25度,非常适合户外运动!" ✅ // 第2次:"北京今天晴天,25度,非常适合户外运动。推荐去公园跑步。" ✅ 还给了建议 // 第3次:"北京今天天气不错,应该可以户外运动吧?" ⚠️ 不确定的语气 // 第4次:`{"suitable": true}` ❌ 输出格式不符合预期! ```发现问题了吗?代码一模一样,输入一模一样,但输出却天差地别:
有时候 LLM 会自己“加戏”(比如推荐跑步地点),这可能是惊喜,也可能是惊吓;
有时候语气变得不确定,直接影响用户体验;
有时候输出格式完全跑偏,下游解析直接报错。
更关键的是:这并非传统意义上的“代码 bug”,你没办法通过断点调试来定位问题。这本质上是 Prompt 设计的问题、模型温度参数的问题,甚至可能是模型本身的行为特性导致的。
如何应对这种不确定性?
有经验的 Agent 开发者通常会做以下三件事:
1. 结构化输出(Structured Output)
``` // 定义期望的输出结构体 type ActivityAdvice struct { Suitable bool `json:"suitable"` Reason string `json:"reason"` Suggestion string `json:"suggestion"` } // 在Prompt中要求LLM输出JSON格式,然后用 json.Unmarshal 解析 systemPrompt := `你是一个户外运动顾问。请严格按照以下JSON格式输出: {"suitable": true/false, "reason": "判断理由", "suggestion": "具体建议"} 不要输出任何其他内容。` // 调用后解析 var advice ActivityAdvice if err := json.Unmarshal([]byte(llmOutput), &advice); err != nil { // 输出格式不对,触发重试或降级 log.Warn("输出格式解析失败", "output", llmOutput, "error", err) } ```2. 评估而非调试
``` // 跑100次,统计成功率 successCount := 0 for i := 0; i < 100; i++ { output, err := executor.Call(ctx, map[string]any{ "input": "北京天气怎么样?", }) if err != nil { continue } var advice ActivityAdvice if json.Unmarshal([]byte(output), &advice) == nil { successCount++ } } fmt.Printf("成功率: %.2f%%", float64(successCount)/100*100) ```3. 防御性编程
``` var advice ActivityAdvice if err := json.Unmarshal([]byte(agentOutput), &advice); err != nil { // 降级方案:用更简单的方式重新请求,或返回兜底 advice = ActivityAdvice{ Suitable: false, Reason: "解析失败", Suggestion: "请重试", } } ```阶段性总结
传统开发和 Agent 开发的关注点,确实存在比较明显的差异:
| 维度 | 传统开发 | Agent开发 |
|---|---|---|
| 核心逻辑 | if-else / 算法 | Prompt + 模型推理 |
| 问题定位 | 断点调试 | 统计评估 |
| 输出特征 | 确定性 | 概率性 |
| 质量保证 | 单元测试 | 评估数据集 + 回归测试 |
| 失败处理 | try-catch | 降级 + 重试 + 兜底 |
正在转型的同学,需要有意识地调整自己的思考方式。如果用写业务代码的思路去做 Agent 开发,过程中可能会遇到不少挫败感。
"三刷"官方文档实战演示
前面说了方法论,这里用 langchaingo(Go 版 LangChain)这个真实案例,演示一下“三刷”法具体怎么做。
1刷:建立认知地图(1-2天)
目标很简单,不写代码,只做三件事:
浏览 langchaingo 官方示例和文档,一边看一边画出思维导图;
理解每个模块是干什么用的,但不要求马上搞懂具体怎么用;
标记出自己最需要的模块,留给 2 刷时重点突破。
刷完之后,你应该能画出这样一张认知地图:
``` langchaingo(Go Agent框架) ├── llms(模型交互层) │ ├── openai —— 调用OpenAI/GPT │ ├── ollama —— 本地模型推理 │ └── anthropic —— 调用Claude ├── chains(链式调用) │ ├── LLMChain —— 基础链 │ ├── ConversationalRetrievalQA —— 对话检索链 │ └── MapReduce —— 长文本总结 ├── agents(智能体) │ ├── tools —— 工具定义 │ ├── OpenAIFunctionsAgent —— 函数调用Agent │ └── Executor —— 执行循环(ReAct模式) ├── vectorstores(向量数据库) │ ├── chroma —— ChromaDB │ ├── milvus —— Milvus │ └── pgvector —— PostgreSQL向量扩展 └── documentloaders(文档加载) ├── PDF/Text/Markdown加载器 └── 文档切片器 ```2刷:动手跑通每一个示例(3-5天)
目标更加明确:按模块顺序,把官方文档里每一个代码示例都亲手跑通,并在代码中写好注释。
以 Agent 模块为例,2 刷时应该做到这个程度:
``` // ===== 步骤1:定义工具 ===== // 工具是Agent的手,让LLM能执行实际操作 import "github.com/tmc/langchaingo/tools" func searchKnowledgeBaseTool() tools.Tool { return tools.GenericTool{ Name: "search_knowledge_base", Description: "搜索公司内部知识库,查询产品文档、技术规范等信息", Run: func(ctx context.Context, query string) (string, error) { // 实际项目中这里接向量数据库 return fmt.Sprintf("关于'%s'的搜索结果:...", query), nil }, } } func createTicketTool() tools.Tool { return tools.GenericTool{ Name: "create_ticket", Description: "创建工单。输入格式:{\"title\": \"工单标题\", \"priority\": \"高/中/低\"}", Run: func(ctx context.Context, input string) (string, error) { var req struct { Title string `json:"title"` Priority string `json:"priority"` } json.Unmarshal([]byte(input), &req) return fmt.Sprintf("已创建工单:%s,优先级:%s", req.Title, req.Priority), nil }, } } // ===== 步骤2:创建Agent ===== // Executor是Agent的大脑:接收任务 → 思考 → 调工具 → 观察结果 → 继续思考 → 输出答案 toolList := []tools.Tool{searchKnowledgeBaseTool(), createTicketTool()} llm, _ := openai.New( openai.WithModel("gpt-4o"), openai.WithToken("sk-xxx"), ) agent := agents.NewOpenAIFunctionsAgent(llm, toolList) executor := agents.NewExecutor(agent, agents.WithMaxIterations(5), // 防止无限循环 agents.WithCallbacksHandler(callbacks.LogHandler{}), // 打印思考过程,调试必备 ) // ===== 步骤3:运行并观察 ===== result, _ := executor.Call(ctx, map[string]any{ "input": "客户反馈登录页面打不开,帮我查一下有没有相关文档,有的话创建工单", }) // callbacks.LogHandler 会输出: // > Thought: 用户想查登录问题的文档,我需要先搜索知识库 // > Action: search_knowledge_base // > Action Input: "登录页面打不开" // > Observation: 找到1篇相关文档:《登录模块故障排查指南》 // > Thought: 有相关文档,现在创建工单 // > Action: create_ticket // > Action Input: {"title": "客户反馈登录页面打不开", "priority": "高"} // > Observation: 已创建工单... // > Final Answer: 已为您查到相关文档并创建了高优先级工单。 ```3刷:脱离文档独立实现(2-3天)
目标在这最后一轮:只保留自己写的注释,不看文档,独立实现一遍。
具体做法:
把 2 刷时写的注释提取出来,当作“需求文档”;
清空代码,对着注释自己重新写一遍;
卡住了不要急着看文档,先想清楚“为什么这里需要这样设计”;
实在写不出来了,再对照文档,用显眼的标记标出自己卡住的环节。
时间投入总计:1 刷 1-2 天 + 2 刷 3-5 天 + 3 刷 2-3 天,差不多 1-2 周,就能从“看过文档”真正过渡到“掌握知识”。
AI应用架构演进史
理解了思维方式的差异,掌握了高效的学习方法,接下来需要看清整个 AI 应用的全景版图。
接下来从架构演进的视角来看,帮助大家理解自己目前处在哪个阶段,以及下一步应该往哪里走。
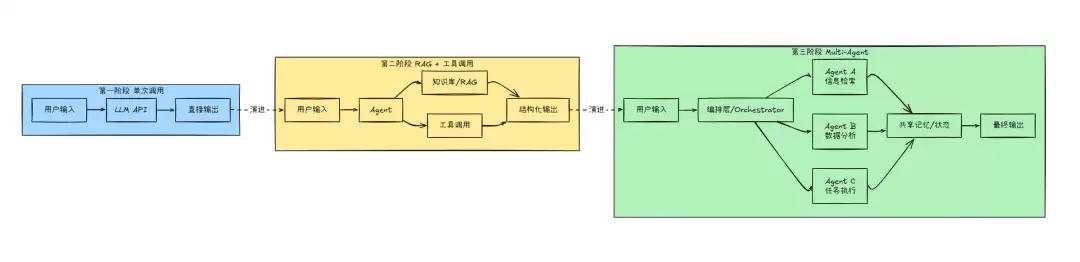
第一阶段:单次调用(2023年初)
这种形态最简单:直接调用 LLM API,输入问题,输出答案。
典型场景比如写一个“AI 客服”,把用户问题和预设的 system prompt 一起丢给 GPT,拿到回复直接展示给用户。
这个阶段的问题很明显:模型不知道你的私有数据(比如客户问“我的订单什么时候到”,GPT 只能凭空编造),无法执行真正意义上的操作(比如查物流信息),而且每次对话相互独立(记不住上一轮说了什么)。
第二阶段:RAG + 工具调用(2023年中-至今)
在这个阶段,给 LLM 接上知识库(RAG)和工具(Tool Use),让它既能查资料,也能执行操作。这是目前企业级 AI 应用的主流形态。
典型场景是智能客服系统:用户问“我的订单到哪了”,Agent 调用物流查询工具获取真实数据,再结合知识库中的退换货政策,给出一个准确、可执行的回复。
免费学习资源推荐:
- 吴恩达《LangChain for LLM Application Development》(免费,约1小时,概念通用)
- 吴恩达《Building Systems with the ChatGPT API》(免费,约1小时,概念通用)
- langchaingo 官方示例(Go生态首选,含完整可运行代码)
- Eino 官方文档(字节跳动开源,Go原生AI框架)
- Prompt Engineering Guide(免费开源,中文版)
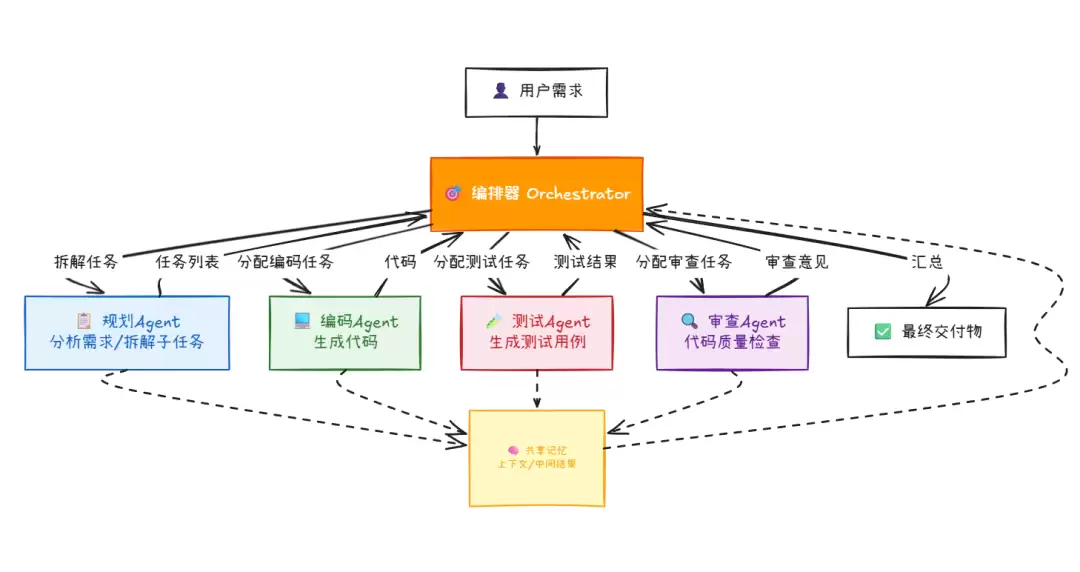
第三阶段:Multi-Agent架构(2024-至今)
多个 Agent 相互协作,每个 Agent 负责一个专门的子任务,通过编排层来协调彼此的工作。
典型场景是软件开发助手:一个 Agent 负责理解需求并拆解任务,另一个负责写代码,第三个负责写测试,第四个负责代码审查。四个 Agent 通过编排器协同工作,最终输出完整的、经过测试的代码。
免费学习资源推荐:
- 吴恩达《Multi AI Agent Systems with crewAI》(免费,约1小时)
- CrewAI官方文档(免费开源框架)
- Microsoft AutoGen官方文档(微软开源,学术论文级别)
- LangGraph官方教程(免费,适合自定义Agent编排)
Multi-Agent 是当前比较明确的主流趋势,越来越多的企业级 AI 应用正朝着这个方向演进。
那么,从第二阶段进阶到第三阶段,最关键的落脚点是什么?答案就是:深入理解 Agent 工程化。
什么是Agent工程化?
很多人会调用 API、会用框架,但做出来的东西往往只能在 Demo 阶段打转,一到生产环境就暴露出各种问题。
这其实就是缺乏“工程化”思维的典型表现。
Agent 工程化,本质上就是让 Agent 从“能跑”进化到“能用”,再进一步从“能用”进化到“好用”的整个过程。
先看一张 Agent 工程化的全景图:
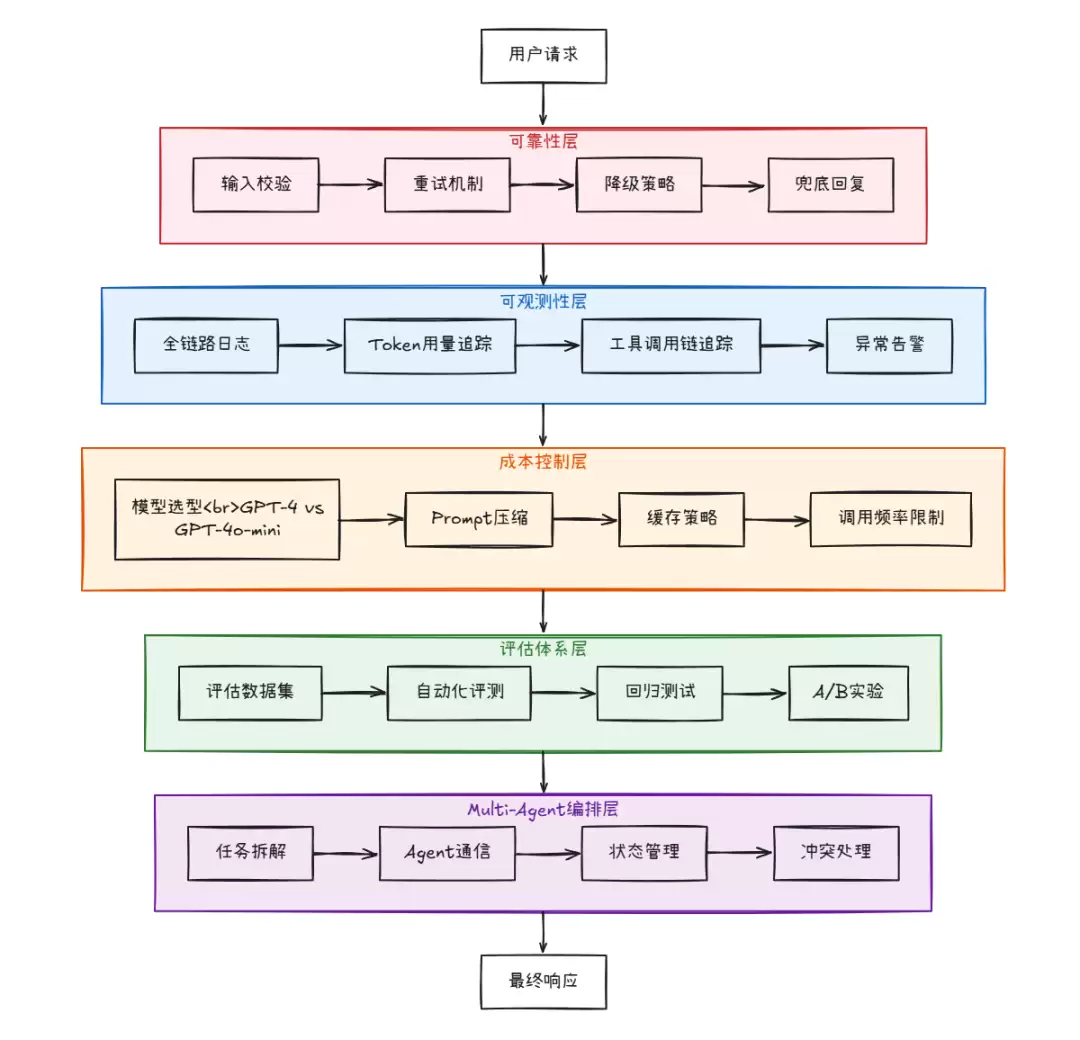
下面逐一拆解每个层面,并给出具体的代码示例。
1. 可靠性设计
Agent 在生产环境中会遇到各种各样的异常情况:模型输出格式不对、工具调用失败、上下文超长……
具体怎么做?来看一个生产级的 Agent 调用封装示例:
``` // 生产级Agent封装——可靠性设计 type ProductionAgent struct { maxRetries int fallbackResp string maxInputTokens int } func NewProductionAgent() *ProductionAgent { return &ProductionAgent{ maxRetries: 3, fallbackResp: "抱歉,系统繁忙,请稍后重试。", maxInputTokens: 100000, } } // InvokeWithRetry 带指数退避重试的调用 func (pa *ProductionAgent) InvokeWithRetry(ctx context.Context, executor *agents.Executor, input map[string]any) (string, error) { var lastErr error for attempt := 0; attempt < pa.maxRetries; attempt++ { // 1. 输入校验 inputStr, ok := input["input"].(string) if !ok || len(inputStr) == 0 { return pa.fallbackResp, fmt.Errorf("输入不合法") } // 2. Token预算检查 if estimatedTokens := estimateTokens(inputStr); estimatedTokens > pa.maxInputTokens { input["input"] = truncateText(inputStr, pa.maxInputTokens) } // 3. 调用Agent result, err := executor.Call(ctx, input) if err != nil { lastErr = err log.Warn("Agent调用失败,准备重试", "attempt", attempt+1, "error", err) // 指数退避:1s → 2s → 4s time.Sleep(time.Duration(1<你需要知道 Agent 正在做什么、为什么这样做、以及哪个环节出了问题。
具体怎么做?可以使用 LangSmith(有免费额度)或自建追踪系统:
``` import time import json from functools import wraps def trace_agent_call(func): """Agent调用追踪装饰器""" @wraps(func) def wrapper(*args, **kwargs): trace_id = f"trace_{int(time.time() * 1000)}" start = time.time() log_entry = { "trace_id": trace_id, "timestamp": start, "input": str(kwargs.get("input", ""))[:200], # 截断存储 } try: result = func(*args, **kwargs) log_entry.update({ "duration_ms": (time.time() - start) * 1000, "status": "success", "output_length": len(str(result)), }) return result except Exception as e: log_entry.update({ "duration_ms": (time.time() - start) * 1000, "status": "error", "error": str(e), }) raise finally: # 写入日志(生产环境用结构化日志如JSON Lines) print(json.dumps(log_entry, ensure_ascii=False)) return wrapper ```- LangSmith:LangChain官方出品,免费额度够个人项目用
- Phoenix (Arize):开源,本地部署,支持LLM调用追踪和评估
- Go 项目可直接用
slog+ 结构化日志 + Grafana/Prometheus 搭建可观测性体系,轻量高效
3. 成本控制
Token 就是钱。一个不注意,单次对话可能花掉几毛钱,日活上千的话,一天就是几百块的成本。
具体策略:
``` // 成本感知的Agent type ModelCost struct { Input float64 // 每百万token美元 Output float64 } var modelCostMap = map[string]ModelCost{ "gpt-4o": {Input: 2.5, Output: 10.0}, "gpt-4o-mini": {Input: 0.15, Output: 0.6}, "claude-3.5-sonnet": {Input: 3.0, Output: 15.0}, } // RouteByComplexity 按任务复杂度选模型——简单任务用小模型,省钱 func RouteByComplexity(task string) string { simpleKeywords := []string{"总结", "分类", "提取"} complexKeywords := []string{"分析", "推理", "代码"} for _, kw := range simpleKeywords { if strings.Contains(task, kw) { return "gpt-4o-mini" // 简单任务,便宜约17倍 } } for _, kw := range complexKeywords { if strings.Contains(task, kw) { return "gpt-4o" // 复杂任务,用大模型 } } return "gpt-4o-mini" // 默认用小模型 } // EstimateCost 估算单次调用成本 func EstimateCost(model string, inputTokens, outputTokens int) float64 { cost, ok := modelCostMap[model] if !ok { return 0 } return float64(inputTokens)/1_000_000*cost.Input + float64(outputTokens)/1_000_000*cost.Output } // 实际效果示例: // 一句话总结任务:gpt-4o ≈ $0.001,gpt-4o-mini ≈ $0.00006 // 日处理10万次总结:gpt-4o ≈ $100/天,gpt-4o-mini ≈ $6/天 // 差距是17倍! ```4. 评估体系
Agent 的效果到底怎么衡量?不能只是凭感觉说“好像还行”。
具体做法:建立评估数据集,跑批量化、自动化的评估流程。
``` // 评估数据集示例 type EvalCase struct { Input string ExpectedTools []string // 期望调用的工具 ExpectedKeywords []string // 期望包含的关键词 Difficulty string } var evalDataset = []EvalCase{ { Input: "帮我查一下北京的天气,适合跑步吗?", ExpectedTools: []string{"get_weather"}, ExpectedKeywords: []string{"温度", "适合", "不适合"}, Difficulty: "easy", }, { Input: "客户说登录不了,帮我查文档、创工单、发通知给运维", ExpectedTools: []string{"search_kb", "create_ticket", "send_notification"}, ExpectedKeywords: []string{"工单", "通知", "文档"}, Difficulty: "hard", }, // ... 至少准备50-100条 } type EvalResult struct { Total int ToolAccuracy float64 KeywordRecall float64 } func EvaluateAgent(executor *agents.Executor, dataset []EvalCase) EvalResult { var r EvalResult r.Total = len(dataset) for _, c := range dataset { result, _ := executor.Call(context.Background(), map[string]any{ "input": c.Input, }) // 工具调用准确率 calledTools := extractCalledTools(result) if stringSliceEqual(calledTools, c.ExpectedTools) { r.ToolAccuracy++ } // 关键词召回率 outputLower := strings.ToLower(result) matched := 0 for _, kw := range c.ExpectedKeywords { if strings.Contains(outputLower, kw) { matched++ } } r.KeywordRecall += float64(matched) / float64(len(c.ExpectedKeywords)) } r.ToolAccuracy = r.ToolAccuracy / float64(r.Total) * 100 r.KeywordRecall = r.KeywordRecall / float64(r.Total) * 100 return r } ```5. Multi-Agent编排
当任务复杂到单个 Agent 搞不定的时候,就需要多个 Agent 协作完成。
以 Go 为例,用 goroutine + channel 搭建一个“技术文章写作团队”:
``` // Multi-Agent 编排:技术文章写作团队 type ArticleTask struct { Topic string Research string // 研究资料 Draft string // 初稿 FinalDraft string // 终稿 } // Agent 1:研究员 —— 负责搜集资料 func researcherAgent(ctx context.Context, topic string, resultCh chan<- ArticleTask) { // 调用LLM做研究 research := callLLM(ctx, fmt.Sprintf("请搜集关于'%s'的最新资料、论文和最佳实践", topic)) resultCh <- ArticleTask{Topic: topic, Research: research} } // Agent 2:撰稿人 —— 根据研究资料写初稿 func writerAgent(ctx context.Context, task ArticleTask, resultCh chan<- ArticleTask) { prompt := fmt.Sprintf("根据以下研究资料,撰写关于'%s'的深度技术文章:%s", task.Topic, task.Research) task.Draft = callLLM(ctx, prompt) resultCh <- task } // Agent 3:审校 —— 质量把关 func reviewerAgent(ctx context.Context, task ArticleTask, resultCh chan<- ArticleTask) { prompt := fmt.Sprintf("审查以下文章的技术准确性、逻辑清晰度和可读性,直接输出修改后的版本:%s", task.Draft) task.FinalDraft = callLLM(ctx, prompt) resultCh <- task } // 编排器:串联执行 func orchestrateArticleWriting(ctx context.Context, topic string) *ArticleTask { ch1 := make(chan ArticleTask, 1) ch2 := make(chan ArticleTask, 1) ch3 := make(chan ArticleTask, 1) go researcherAgent(ctx, topic, ch1) task := <-ch1 go writerAgent(ctx, task, ch2) task = <-ch2 go reviewerAgent(ctx, task, ch3) task = <-ch3 return &task } ```- langchaingo:LangChain 的 Go 移植,GitHub 13k Star,最活跃
- Eino(字节跳动开源):Go 语言 AI 应用开发框架,支持 Agent/Chain/Workflow
- 直接调用 OpenAI/Claude API + goroutine 编排,轻量灵活,适合对可控性要求高的场景
如果项目需要复杂的 Multi-Agent 协作,也可以考虑 Go 做业务层,Python 服务化提供 Agent 能力(通过 HTTP/gRPC 调用),这是目前比较务实的混合架构方案。
免费学习资源:
- 吴恩达《Multi AI Agent Systems with crewAI》(免费,Python但概念通用)
- langchaingo Agent 示例(Go生态Agent实践)
- Eino Agent 使用指南(字节跳动开源,Go原生)
- Anthropic《Building effective agents》(必读!Anthropic官方Agent设计指南)
总结
这篇文章的核心要点,整理成一个简表:
| 主题 | 核心观点 |
|---|---|
| 思维转变 | 从“确定性编程”到“概率性编程”,学会用评估代替调试 |
| 学习方法 | “三刷”官方文档:认知地图→动手实践→独立实现 |
| 技术路线 | 单次调用 → RAG + 工具 → Multi-Agent |
| 工程化 | 可靠性 + 可观测性 + 成本控制 + 评估体系 + Multi-Agent编排 |
从入门到进阶,完整学习路径
``` 第1-2周:入门打基础 ├── Go基础(不熟的先补) ├── 吴恩达《Building Systems with the ChatGPT API》(免费,Python但概念通用) ├── langchaingo官方示例(GitHub: tmc/langchaingo,三刷法) ├── Eino(字节跳动开源,Go原生AI框架) └── 实战项目:做一个RAG问答机器人 第3-4周:进阶核心能力 ├── Prompt Engineering Guide(免费开源) ├── 向量数据库(ChromaDB上手最快,Milvus适合生产,Go都有SDK) ├── 工作流编排(Go用goroutine + channel / Eino框架) └── 实战项目:做一个能调工具的智能客服 第5-8周:高阶突破 ├── Multi-Agent架构设计 ├── Agent工程化实践(可靠性/可观测性/成本/评估) ├── Anthropic《Building effective agents》必读 ├── Go + Python混合架构(Go做业务层,Python做Agent推理层) └── 实战项目:做一个Multi-Agent协作系统(如自动化代码审查) ```Go 生态 Agent 开发资源推荐
| 资源 | 说明 | 地址 |
|---|---|---|
| langchaingo | LangChain Go移植,13k Star | github.com/tmc/langchaingo |
| Eino(字节跳动) | Go原生AI应用框架 | github.com/cloudwego/eino |
| OpenAI Go SDK | 官方Go SDK | github.com/openai/openai-go |
| Ollama Go SDK | 本地模型推理 | github.com/ollama/ollama |
免费资源汇总
| 类别 | 资源 | 链接 |
|---|---|---|
| 课程 | 吴恩达 LangChain for LLM App | deeplearning.ai |
| 课程 | 吴恩达 Building Systems with ChatGPT API | deeplearning.ai |
| 课程 | 吴恩达 Multi AI Agent with crewAI | deeplearning.ai |
| Go框架 | langchaingo(Go版LangChain) | github.com/tmc/langchaingo |
| Go框架 | Eino(字节跳动开源AI框架) | github.com/cloudwego/eino |
| Go SDK | OpenAI官方Go SDK | github.com/openai/openai-go |
| 文档 | Prompt Engineering Guide(中文) | promptingguide.ai |
| 必读 | Anthropic Building Effective Agents | anthropic.com |
| 工具 | LangSmith(可观测性) | smith.langchain.com |
| 工具 | Phoenix(开源LLM追踪) | github.com/Arize-AI |
不管你现在处于哪个阶段,最重要的第一件事只有一个:动手做项目。
看再多的文章,都不如自己动手做一个真实的项目来得实在。建议按这个节奏来推进:
第 1 个项目(2周内):RAG 问答机器人——跑通“知识库检索 + LLM回答”的完整流程;
第 2 个项目(2-4周):带工具调用的智能助手——让 Agent 能搜索、能计算、能操作 API;
第 3 个项目(4-8周):Multi-Agent 协作系统——用 CrewAI 或 LangGraph 做一个多 Agent 协作项目。
每个项目都放到 GitHub 上,写好 README。面试的时候,直接打开项目现场演示,比简历上写一句“熟悉 Agent 开发”有说服力得多。




