本文要介绍的开源项目是 Ludwig,一款声明式深度学习框架。
ludwig-ai/ludwig 的核心功能非常直接:只需一份 YAML 配置文件,就能将 AI 模型的训练、微调、预测和部署全流程串联起来。
 Ludwig 在 GitHub 上的项目概览
Ludwig 在 GitHub 上的项目概览
Star 数:11,698 | Fork 数:1,219 | 许可证:Apache-2.0 | 编程语言:Python |
|---|
Ludwig 组件架构示意
1. Ludwig 究竟是什么
Ludwig 是一个声明式深度学习框架,专为简化模型开发而设计。
你无需预先编写大量的 PyTorch 训练代码,而是先通过配置文件清晰定义:输入字段是什么、输出字段是什么、模型类型选哪个、训练器如何配置、后端采用本地还是分布式运行。
随后执行一行命令:
ludwig train --config model.yaml --dataset my_data.csv官方 README 将其定位为适用于 LLM、多模态模型以及表格 AI 的通用框架。它既不是笔记本工具,也不是数据库或前端 UI 库。
 采用声明式配置的优势
采用声明式配置的优势
2. 它解决了哪些痛点
在实际机器学习项目中,大量时间并非消耗在“选择模型名称”上。
真正的麻烦往往集中在这里:数据如何预处理、文本字段如何编码、类别字段如何处理、训练参数如何设置、评估流程如何跑通、模型如何导出、推理服务如何启动。
Ludwig 的思路是将所有这些决策集中收拢到一份配置文件中。
例如,针对影评分类任务,配置里只需声明 genres 为 set 类型、content_rating 为 category 类型、review_content 为 text 类型,最后预测 recommended 这个 binary 输出。官方文档中的入门示例正是这样操作的。
这种方式对团队协作非常实用——配置文件比散落在脚本中的训练逻辑更易于查看、修改和复现。
3. 核心亮点
第一个亮点是 LLM 微调能力。
官方 README 中给出的示例是使用 LoRA/QLoRA 微调 Llama 模型。配置文件中只需指定 model_type: llm、base_model、adapter、quantization、prompt template,然后执行 ludwig train 即可运行。
它覆盖了 SFT、DPO、KTO、ORPO、GRPO 等多种对齐方法,以及多种 PEFT adapter 类型。这表明 Ludwig 并非仅仅封装了一层推理 API,而是真正深入到了训练和对齐的底层。
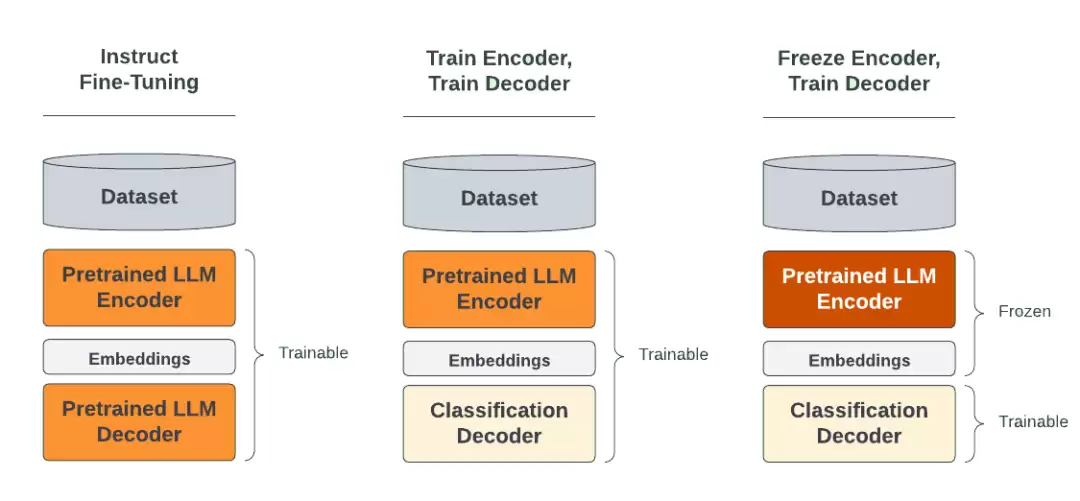 LLM 微调流程示意
LLM 微调流程示意
第二个亮点是对多模态和表格数据的支持。
Ludwig 支持 text、number、category、binary、set、image、audio、timeseries、vector、date 等多种输入类型。你可以将文本、图片、数值字段混合在同一个任务中,通过配置文件描述它们如何输入模型。
第三个亮点:它并没有止步于训练环节。文档中提供了 ludwig predict 命令行,也包含了 ludwig serve —— 该命令会启动一个 FastAPI 服务,通过 /predict 端点接收外部请求。
4. 为什么值得关注
Ludwig 值得关注的原因在于,它比较完整地覆盖了“模型工程”的各个环节。一份配置文件中不仅能指定模型结构,还可以包含 preprocessing、trainer、hyperopt、backend 等配置项。文档中还提到了 Ray、DeepSpeed、FSDP、Docker、Hugging Face Hub、KServe、Ray Serve 等工程化路径。
这类项目最怕只展示一个漂亮的演示,但一碰到训练规模、部署和实验复现就溃散。Ludwig 至少将这些入口整齐地摆在了同一套接口之下。
目前该项目由 Linux Foundation AI & Data 托管。PyPI 上当前版本为 0.16.2,发布于 2026-05-08,要求 Python 3.12。
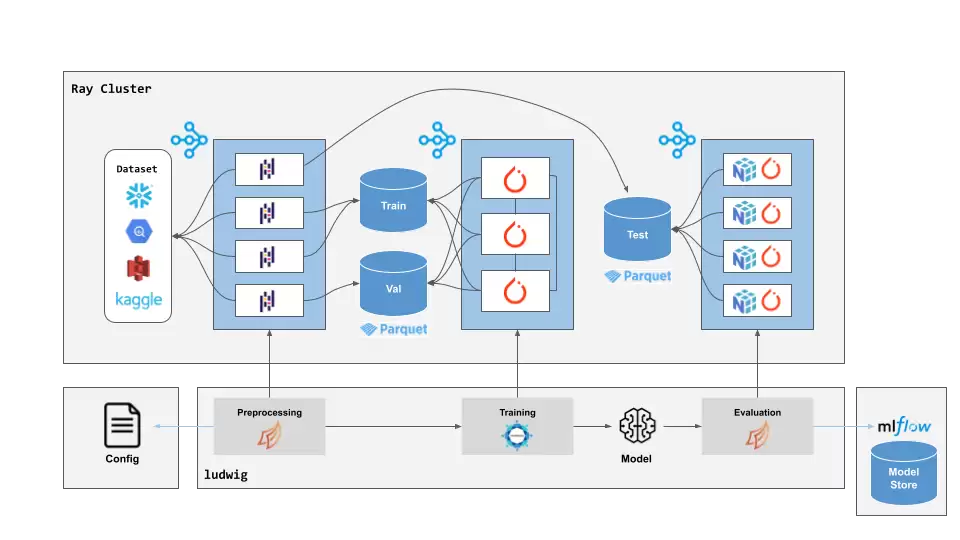 Ludwig 在 Ray 上运行示意
Ludwig 在 Ray 上运行示意
5. 如何上手使用
安装过程非常标准:
pip install ludwig如果希望安装所有可选依赖:
pip install ludwig[full]如果只想体验 LLM 微调,可参考文档中的方式:
pip install ludwig ludwig[llm]最简化的使用路径如下:首先准备一个 CSV 数据集,然后编写 model.yaml 配置文件,在其中声明输入和输出字段。接着开始训练:
ludwig train --config model.yaml --dataset data.csv进行预测:
ludwig predict --model_path results/experiment_run/model --dataset new_data.csv启动服务:
ludwig serve --model_path results/experiment_run/model进行 LLM 微调时,还需要注意 Hugging Face token、模型访问权限以及 GPU 资源。文档中 Llama2 QLoRA 的示例提到,本地 GPU 至少需要 12 GiB VRAM。
 性能对比结果展示
性能对比结果展示
6. 适合哪些用户,以及注意事项
Ludwig 主要适合两类人群。
第一类是数据科学和机器学习团队。他们手中拥有表格、文本、图片、时间序列等多种数据,希望快速搭建一套可复现的训练流程。
第二类是需要进行 LLM 微调的用户——尤其是已经确定要使用哪个基座模型、哪份指令数据,但不想从头编写完整的训练脚手架。
需要提前说明的是:声明式配置并非魔法。字段类型需要正确判断,数据质量需要自行把控,训练资源需要自己计算。LLM 微调过程中还会遇到显存限制、模型授权、量化和 adapter 选择等实际问题。
更推荐的入门方式,是先跑通文档中提供的 Rotten Tomatoes 或 Alpaca 小示例,确认配置和结果都可以解释,再逐步替换为自己的数据。等对流程有了把握,再向更大的训练任务扩展。
今天就先聊到这里,我们下期再见。




