2025年5月29日,人工智能公司Anthropic正式推出其旗舰级新模型——Claude Opus 4.8。本次升级的核心方向聚焦于智能体编程、跨领域推理以及知识型工作,旨在提升模型在实际任务中的可靠性与实用性。
相较于一个月前发布的Opus 4.7,本次迭代幅度虽不算剧烈,且定价策略维持不变。然而,核心优化精准瞄准了用户最关注的场景:编码能力、智能体任务执行、逻辑推理以及知识密集型工作。简单来说,这些都是能让用户直观感受到模型“变得更为智能”的关键领域。
根据多家早期测试机构的反馈,Claude Opus 4.8给用户留下了“可靠性提升、判断力更为敏锐”的深刻印象。在处理复杂多步骤任务时,其判断更加稳健——不仅能够主动提出疑问,还能自行识别并纠正错误,甚至在计划不合理时提出质疑。这种自主纠偏的能力,在之前的模型版本中较为罕见。
一个非常直观的数据对比:与Opus 4.7相比,Opus 4.8在其生成的代码中遗留缺陷且未加说明的概率,大约下降了4倍。该模型更倾向于主动标注不确定性,缺乏依据的结论也显著减少。这意味着什么?模型已不再处于“埋头写代码、有错也不报告”的状态,而是开始学习以更透明的方式呈现其输出。
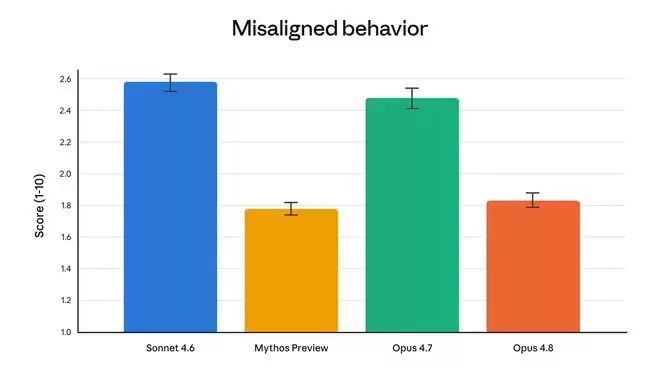
在对齐性能方面,Opus 4.8同样表现亮眼。它在支持用户自主性、按照用户最佳利益行动等亲社会指标上创下了新高。同时,欺骗等不匹配行为的发生率低于Opus 4.7,与Claude Mythos Preview版本的水平相近。可以说,该模型在“更顺从”与“更诚实”之间找到了一个良好的平衡点。
配套功能方面也有升级。claude.ai平台新增了effort(努力程度)控制选项,用户可以在更高质量输出与更快响应速度之间自由权衡。默认档位设置为high(高),在编码任务中,token消耗量与Opus 4.7的默认档接近,但生成效果更优。如果用户选择extra(额外)或max(最高,在Claude Code中对应xhigh)档位,模型将消耗更多token以换取更理想的结果——这相当于为用户提供了一个“性能拉满”的选项。
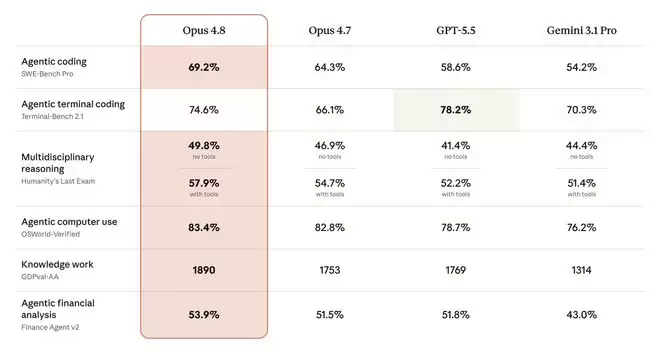
在基准测试方面,Anthropic公布的成绩相当出色:Opus 4.8在SWE-Bench Pro上取得了69.2%的分数,并在该测试以及其他多项基准中超越了GPT‑5.5和Gemini 3.1 Pro。不过,需要留意的是:在终端编程基准上,GPT‑5.5目前仍然保持领先。因此,“全面超越”的说法尚不成立,但至少在某些关键维度上,Anthropic确实迈出了追赶的一步。
性能与价格方面也进行了调整。Claude Opus 4.8的快速模式运行速度提升至原来的2.5倍,而成本则降低为此前模型的三分之一。具体定价方案如下:常规模式下,每100万输入令牌收费5美元、每100万输出令牌收费25美元;快速模式下,每100万输入令牌收费10美元、每100万输出令牌收费50美元。速度更快、成本更低,这显然是为了鼓励用户“多用、用得尽兴”。




