在现代短剧、在线课程与产品视频的多语种配音流程中,最容易被忽视的痛点并非“机器能否翻译准确”,而是翻译完成后,观众听到的究竟是否还是原来那个角色在说话。同一句台词从中文转为英语、日语或越南语时,如果只保留文本含义,角色的愤怒、迟疑、笑意、叹息与停顿都会在翻译过程中被彻底抹平。最终呈现的往往不是本地化版本,而是一段被重新朗读的字幕——这与“保留角色感”的目标相去甚远。
从工程实现角度看,跨语种配音中的情感保留通常可拆分为两个层次:第一层是粗粒度情绪分类,例如开心、难过、生气、害怕、惊讶、厌恶、中性、生动;第二层是细粒度副语言还原,比如笑声、轻笑、咳嗽、清嗓子、叹气、换气。前者回答“情绪方向是否正确”,后者回答“角色的人味是否还在”。
仅做文本翻译为何会丢失角色感
传统视频翻译链路通常将任务拆解为ASR、机器翻译、TTS三段。ASR将原视频语音转写成文字,机器翻译将文字转为目标语言,TTS再将目标语言文本合成语音。这条链路能保证信息传递,但会天然丢失大量非文本信号。
举一个最直观的例子:台词“你终于来了”在短剧中可以呈现三种完全不同的演绎——久别重逢时的惊喜、被背叛后的冷笑、濒临崩溃前的松一口气。从文本层面看,这三句几乎没有区别;从语音层面看,它们的音高走势、语速、停顿、气声与尾音却截然不同。跨语种配音要保留情感,本质上不是让TTS“读得更自然”,而是将原始语音中的表达特征提取出来,再作为条件注入到目标语言的合成过程中。
一条更稳定的工程链路通常是这样的:
原视频音轨 → ASR 转写 + 时间轴切分 → 说话人分离与角色聚类 → SER 情绪识别(8 类粗粒度) → 副语言事件检测(笑声、叹气、咳嗽、换气) → 目标语言翻译与长度控制 → 带情绪条件的声音克隆 / TTS 合成 → 时间轴对齐与视频输出。
这条链路的本质判断是:文本翻译只决定“说什么”,而情感迁移决定“怎么说”。
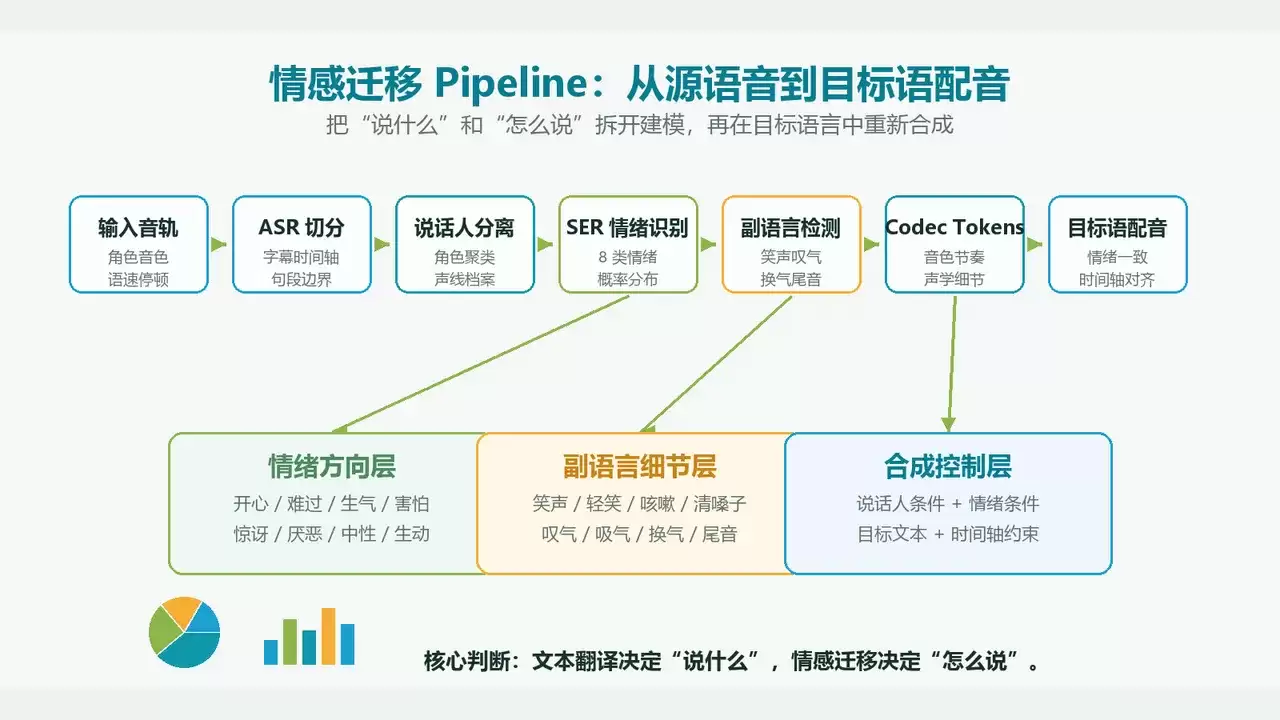
第一层:SER 如何将情绪转化为可用的条件
SER,即语音情感识别(Speech Emotion Recognition),通常将一段语音映射到有限的情绪类别。针对视频翻译配音场景,过细的情绪标签反而容易导致不稳定——工程上更常采用 6 到 8 类粗粒度标签:开心、难过、生气、害怕、惊讶、厌恶、中性、生动。
这些标签并非直接展示给用户,而是作为后续合成模型的输入条件。常见做法是:先按字幕时间轴切出语音片段,再对每个片段提取声学特征,包括 pitch、energy、duration、spectral centroid、MFCC 或 SSL 表征。SER 模型输出情绪概率分布后,不直接取单一标签,而是保留置信度信息。
例如一段台词可能被识别为:
{
"speaker": "role_03",
"text": "你终于来了",
"emotion": {
"sad": 0.58,
"angry": 0.21,
"neutral": 0.13,
"surprised": 0.08
},
"duration_ms": 1840
}
这比简单标注为“sad”更具价值。因为短剧对白中的情感往往是混合的——很多台词并非纯粹的开心或难过,而是难过中带有一丝生气、惊讶中夹杂几分轻松。条件生成阶段可根据概率分布控制语气强度,避免将所有悲伤句都合成为同一种哭腔。
在实际工程中,粗粒度情绪分类最适合承担三个职责:
- 为 TTS 提供情绪方向:开心与生气的音高、能量和节奏策略不同,模型需要明确的条件。
- 为翻译提供语气约束:同一句源语,目标语言可选择更口语化、更克制或更强烈的表达方式。
- 为质检提供异常提示:如果同一角色连续十几句都被识别为中性,通常需要检查音频切分或模型置信度。
但 SER 也有其边界:它能判断情绪大类,却难以完整保留“轻笑着说”“吸了一口气再说”“尾音发虚”等细节。要解决这些问题,就必须进入第二层:副语言还原。
第二层:副语言为何比情绪标签更难保留
副语言指的是语言内容之外的声音事件与表达细节,包括笑声、轻笑、咳嗽、清嗓子、叹气、正常换气、拖长音、吞字、气声、颤音等。这些细节不一定改变文本含义,但会直接影响角色的可信度。
传统的 mel-spectrogram 路线在处理这类细节时容易造成信息损失。mel 表征更像是面向语音可懂度与音色合成的连续频谱压缩,适合生成清晰语音,但对短促、非稳态、非语言的事件不够友好。轻笑、咳嗽、叹气通常持续时间短、频谱形态不规则,在文本到 mel 的转换过程中很容易被模型平滑掉。
codec-based 模型在这方面的优势就凸显出来了。它会先将音频编码成离散或半离散的 acoustic tokens,这些 token 不仅承载音素信息,还会保留音色、节奏、能量变化以及部分副语言细节。对于声音克隆与跨语种配音而言,codec token 更接近“可被模型操作的声音单位”。
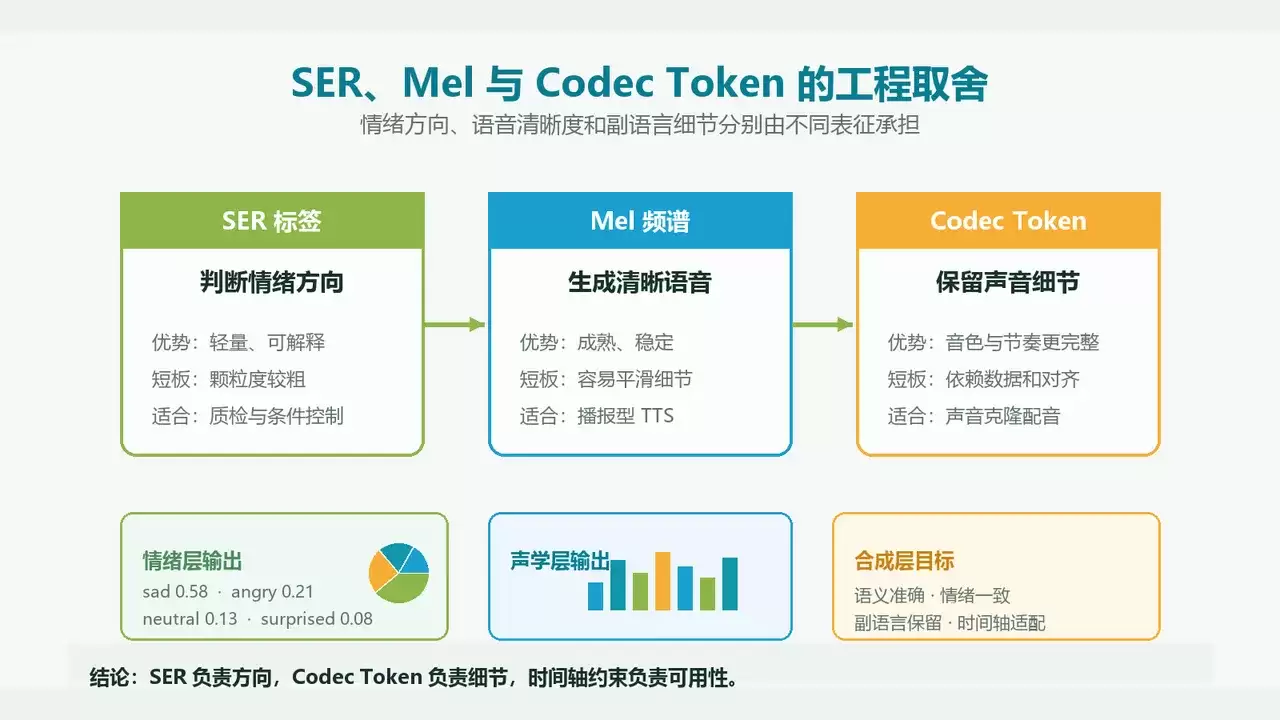
可以将两类路线的差异理解为:
- 传统 mel 路线:文本/音素 → mel 频谱 → vocoder → 语音。优点:成熟、稳定、清晰。短板:容易平滑掉笑声、叹气、换气等细粒度事件。
- codec token 路线:源语音 → codec tokens;目标文本 + 说话人条件 + 情绪条件 → 目标语言 codec tokens → 语音。优点:更容易保留音色、节奏、副语言和非文本表达。短板:对数据、对齐和解码质量要求更高。
这里的关键不是“codec 一定优于 mel”,而是任务目标不同。普通播报型 TTS 只需清晰自然即可;但视频翻译配音需要尽可能保留角色感,这就要求模型记住更多非文本线索。副语言还原并非锦上添花,它决定了配音是否还能像原角色。
情绪条件如何注入到 TTS 或声音克隆中
情绪保留不能仅靠一个 SER 模型完成。SER 只负责识别,真正影响输出的是条件注入方式。常见的方案有三种:
- 标签注入:将情绪类别作为 embedding 输入 TTS 模型,例如 emotion=angry 或 emotion=sad。方案简单直接,适合工程落地,但表达颗粒度较粗,容易将情绪做成固定模板。
- 概率分布注入:模型不只接收单一情绪,而是接收多维情绪权重。这样可以表达“70% 难过 + 20% 生气 + 10% 中性”这类混合状态,更适合剧情对白。
- 参考音频或 codec 条件注入:模型从原始语音中提取 speaker embedding、prosody embedding 或 codec tokens,再结合目标语言文本生成目标语音。这一方案更接近跨语种配音的目标——不仅告诉模型“这句话很生气”,还带去了原句的节奏、停顿、气息和声线线索。
工程上较为稳健的做法是混合使用:SER 输出粗粒度情绪概率,副语言检测模型标注笑声、叹气、换气等事件位置,codec encoder 提取原语音的声学 token,翻译模块控制目标语言句长(避免配音严重超出原时间轴),TTS/声音克隆模型同时接收文本、说话人、情绪和声学条件。
这样做的好处是整体可控:SER 负责方向,codec token 负责细节,时间轴约束负责可用性。单独依赖其中任何一项,都会在长视频或多角色场景中暴露出问题。
在视频翻译 pipeline 中如何落地
如果将这套能力放到真实的视频翻译工程中,最难的并非某个单一模型,而是多模块之间的对齐。
首先是时间轴对齐。情绪识别、副语言检测与字幕切分必须落在同一组时间片上。如果 ASR 将一句台词切错,后面的情绪标签和副语言事件都会错位。短剧场景中角色抢话、背景音乐、环境音和多人同框很常见,因此前处理通常需要加入 VAD、人声分离与说话人分离。
其次是角色一致性。同一个角色在 80 集短剧中不能每集声音都变化。工程上需要维护 speaker profile,将音色、年龄、性别、角色身份和典型语气绑定到同一个角色 ID 上。情绪可以变化,但角色底色必须稳定。
第三是翻译长度控制。中文到英语、日语、越南语的句长变化非常明显。如果目标语言句子过长,即使情绪合成得再好,也无法压入原时间片。此时需要采用 length-constrained translation、语速控制或局部文本改写,而不是等到合成后再硬拉伸音频。
在实际项目中,我们验证过一类更为完整的视频翻译框架:先识别说话人与情绪,再将翻译、配音、字幕生成、字幕压制与硬字幕擦除衔接成一条 pipeline。这类方案的价值不仅在于做一个 TTS 模块,而在于将 AI 视频翻译、AI 配音、多角色识别、声音克隆、字幕生成和硬字幕擦除放到同一个工作流中,适合持续处理内容库与短剧素材。
如果只看单点能力,SER、TTS、codec vocoder 都可以单独讨论;但如果目标是可发布的多语种视频,真正影响交付质量的是这几件事能否连续稳定地跑完。
一个角色建模示例
情感保留最终会落到角色描述与合成控制上。例如同样是青年男性角色,仅写“男声、年轻、中文转英语”是不够的。更可用的角色描述应当像导演给演员讲戏那样:
角色:20 岁左右青年男性,江湖少侠。
性格:开朗跳脱,带点痞气的乐观,重情重义。
声音:清亮通透的少年音,略带磁性,咬字清晰。
语气:轻快灵动,尾音有随性的上扬感,情绪变化明显。
副语言:偶尔轻笑,紧张时有短促吸气,低落时尾音变轻。
这类描述可以与 SER 标签、speaker profile、codec token 共同构成配音条件。模型不是简单地将文本读出来,而是在目标语言中尽可能重建角色状态。
对跨语种配音而言,更合理的评估标准也不应只有“翻译准不准”。至少需要同时考察五个维度:语义是否准确,音色是否稳定,情绪方向是否一致,副语言细节是否保留,时间轴是否适配原视频。
可参考的公开资料包括:EmotiVoice(带情绪控制的多语音提示TTS引擎)、emotion2vec(语音情感表示的自监督预训练)、SpeechTokenizer(语音语言建模的统一分词器)、VALL-E(神经编解码语言模型零样本文本转语音)。
跨语种配音的下一阶段,不是将 TTS 做得更像播音员,而是让模型在另一种语言中保留角色的表达方式。粗粒度情绪分类解决方向,细粒度副语言还原解决质感,codec-based 表征则提供了将这些声音细节带入目标语言的工程抓手。




