本系列文章专注于机器学习(ML)模型的完整开发与部署流程。本文将重点讲解如何将ML模型部署到Google云平台(GCP)。在第一部分中,我们详细梳理了ML工作流,并分析了如何借助机器学习和数据科学技术来创造商业价值。接下来,进入实战阶段:训练并保存一个ML模型,再将其部署到生产环境中。
构建端到端的ML系统时,最后一步往往也是最关键的环节——将训练完成的模型推送至生产环境。成功的部署意味着ML模型从研发环境正式上线,像真实的实时应用一样稳定运行。
本文将介绍三种利用GCP将ML模型部署到生产环境的具体方法。当然,可选的平台不止GCP,AWS、Azure、本地服务器等也是可行选择,但本文以GCP为例,演示如何部署一个Web服务。
环境准备与设置
首先,使用你的Google账户注册GCP。注册时需要提供基本信息,包括信用卡信息,不过请放心,注册免费。此外,你还可以在90天内获得价值300美元的免费试用额度。
账号创建完成后,创建一个新项目,命名为GCP-deployment-example。请注意,不要将该项目关联到任何组织。随后,确保当前操作环境已切换至该项目。
在Google App Engine上部署ML模型
在将模型部署到App Engine之前,你需要为代码添加一些额外的模块。本节使用的所有代码都可以在对应的GitHub仓库中找到。
第一步,在predict.py模块中编写推理逻辑:
import joblib
import pandas as pd
model = joblib.load("logistic_regression_v1.pkl")
def make_prediction(inputs):
"""
Make a prediction using the trained model
"""
inputs_df = pd.DataFrame(
inputs,
columns=["sepal_length_cm", "sepal_width_cm", "petal_length_cm", "petal_width_cm"]
)
predictions = model.predict(inputs_df)
return predictions
这个模块主要完成三项工作:
- 将持久化的模型加载到内存中。
- 定义一个以输入为参数的函数。
- 在函数内部,将输入转换为pandas DataFrame并执行预测。
接着,你需要将推理逻辑封装成一个Web服务。这里用Flask来包装模型,具体的实现细节在main.py中:
import numpy as np
from flask import Flask, request
from predict import make_prediction
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
"""Basic HTML response."""
body = ("
Welcome to my Flask API
")return body
@app.route("/predict", methods=["POST"])
def predict():
data_json = request.get_json()
sepal_length_cm = data_json["sepal_length_cm"]
sepal_width_cm = data_json["sepal_width_cm"]
petal_length_cm = data_json["petal_length_cm"]
petal_width_cm = data_json["petal_width_cm"]
data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]])
predictions = make_prediction(data)
return str(predictions)
if __name__ == "__main__":
app.run()
这段代码创建了两个端点:
- index:可视为主页。
- /predict:用于与部署好的模型交互的接口。
你还需要创建最后一个文件——app.yaml,它用来定义应用程序的运行时环境。
runtime: python38
接下来,在Google Cloud控制台中,具体操作如下:
- 在导航菜单中,选择App Engine。如果找不到,可以先点击View all products,然后在Serverless产品分类下寻找。
- 在App Engine页面中,点击Create Application。
- 选择一个你希望部署的区域。
- 将应用程序语言设置为Python,环境选择Standard。
- 在右上角,点击终端图标,打开Cloud Shell。这样你就不必本地安装Cloud SDK了。
在部署之前,你必须先把代码上传上去。所有代码都托管在GitHub上,你可以直接从Cloud Shell中克隆这个仓库。
复制仓库的URL,然后回到GCP的Cloud Shell中,输入以下命令:
git clone https://github.com/kurtispykes/gcp-deployment-example.git
接着,进入代码目录:
cd gcp-deployment-example/app_engine
然后,初始化应用程序。请确保你选中的是你刚刚创建的那个项目。
最后,开始部署。在Cloud Shell中运行以下命令,如果系统提示是否继续,输入Y。
gcloud app deploy
部署完成后,你会获得一个服务部署位置的URL。打开这个URL,验证应用是否正常运行。你应该能看到“欢迎使用我的Flask API”字样。
接下来,我们需要测试一下/predict端点是否真的能工作。
使用Postman测试部署是否成功
你可以用Postman向/predict端点发送POST请求来验证。Postman是一个专为开发者设计的API平台,用于设计、构建、测试和迭代API。
如果还没有账号,先点击免费注册。当然,有完整的教程可以参考,但这里我们直接进入正题。依次选择Workspaces → My Workspace → New → HTTP Request。
然后,将HTTP请求方法从GET改为POST,并在请求URL中粘贴你之前获得的部署服务链接。
接下来,切换到Body标签页,选择raw格式,然后插入一个示例实例的数据,最后点击Send。
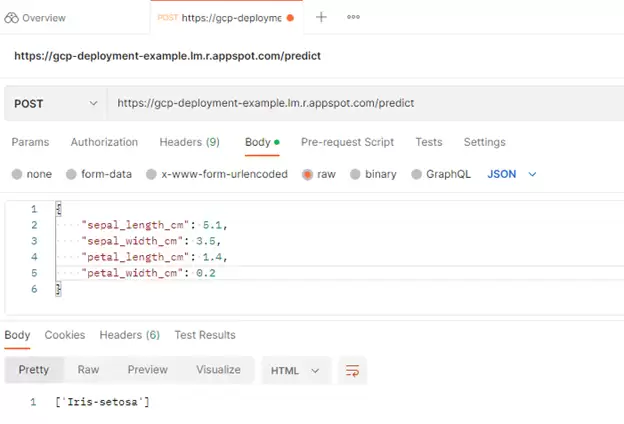 图1. 使用Postman测试预测端点
图1. 使用Postman测试预测端点
你向/predict端点发送了一个包含原始输入数据的POST请求。作为响应,模型返回了[‘Iris-setosa’]——这是一个非常积极的信号,说明模型已经成功部署并正常工作了。
当然,GCP上还提供了其他服务,也可以用它们来部署模型,我们接着看看怎么弄。
在Google Cloud Functions上部署ML模型
Cloud Functions是GCP上另一种无服务器技术。为了让部署过程更顺畅,我对代码做了一些调整。最明显的变化是:不再从本地仓库导入序列化的模型,而是从Google Cloud Storage(GCS)中调用模型。
将模型上传到Google Cloud Storage
在GCP-console示例项目中,先点击导航菜单,找到Cloud Storage,然后选择Buckets → Create Bucket。系统会要求你为存储桶命名并进行其他配置。我把我的存储桶命名为model-data-iris。
存储桶创建完成后,接下来就是上传序列化模型。点击Upload Files,找到你本地模型文件所在的位置并选中它。
现在,你可以通过GCP上的各种服务来访问这个文件了。为了访问Cloud Storage,你需要从google.cloud中导入storage对象。下面的代码展示了如何从GCS中加载模型,完整的例子可以在Cloud Functions的main.py文件中找到。
import joblib
import numpy as np
from flask import request
from google.cloud import storage
storage_client = storage.Client()
bucket = storage_client.get_bucket("model-iris-data")
blob = bucket.blob("logistic_regression_v1.pkl")
blob.download_to_filename("/tmp/logistic_regression_v1.pkl")
model = joblib.load("/tmp/logistic_regression_v1.pkl")
def predict(request):
data_json = request.get_json()
sepal_length_cm = data_json["sepal_length_cm"]
sepal_width_cm = data_json["sepal_width_cm"]
petal_length_cm = data_json["petal_length_cm"]
petal_width_cm = data_json["petal_width_cm"]
data = np.array([[sepal_length_cm, sepal_width_cm, petal_length_cm, petal_width_cm]])
predictions = model.predict(data)
return str(predictions)
在GCP控制台的导航菜单中,找到Cloud Functions。如果找不到,可以点击View all products并展开Serverless分类。接着,点击Create Function。如果你是第一次创建云函数,系统会要求你启用API,点击Enable继续。
配置设置如下:
- 函数名称 = Predict
- 触发器类型 = HTTP
- 允许未认证的调用 = 启用
在运行时、构建、连接和安全设置部分,默认值就足够了,所以可以直接点击Next。
接下来,你需要设置运行时和定义源代码。在Runtime部分,选择你使用的Python版本,我选的是Python 3.8。在源代码来源处,选择Inline Editor。
将下面的代码示例复制粘贴到内联编辑器中,云函数会把这个文件作为main.py的入口点。
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
同时,更新requirements.txt文件:
flask >= 2.2.2, <2.3.0
numpy >= 1.23.3, <1.24.0
scikit-learn >=1.1.2, <1.2.0
google-cloud-storage >=2.5.0, <2.6.0
一定要记得把Entry point的值改为端点的名称,这里就是predict。
完成所有修改后,点击Deploy。部署过程会花几分钟时间,用于安装依赖并启动应用。部署成功后,你会看到函数名旁边出现一个绿色的对勾图标。
现在,你可以在Testing选项卡上测试这个应用是否正常工作。用刚才的示例数据测试一下:
{
"sepal_length_cm" : 5.1,
"sepal_width_cm" : 3.5,
"petal_length_cm" : 1.4,
"petal_width_cm" : 0.2
}
如果你输入和之前相同的参数,会得到同样的响应。至此,你已经学会了如何使用Cloud Functions部署ML模型。使用这种部署方式,你完全不用操心服务器管理。云函数只在收到请求时执行,服务器运维全部交给Google来处理。
在Google AI Cloud上部署ML模型
前面两种部署方式都需要你编写不同程度的代码。而在Google AI Cloud上,你可以直接提供训练好的模型,剩下的管理工作全部由平台代劳。
在Cloud控制台的导航菜单中,找到AI Platform。在Models标签页中,选择Create Model。你可能会看到一条警告信息,提示你改用Vertex AI——这是另一个将AutoML和AI平台统一起来的托管AI服务,不过它在本文的讨论范围之外。
接下来,系统会提示你选择一个区域。选定区域后,点击Create Model。为模型命名,调整区域设置,然后点击Create。
进入刚刚创建模型的那个区域,你应该能看到这个模型。点击模型,然后选择Create a Version。
现在,你需要将模型链接到Cloud Storage中存储的那个模型文件。这里有几个关键点需要特别注意:
- AI Platform上支持的scikit-learn最新模型框架版本是1.0.1,所以你必须用这个版本来构建模型。
- 模型必须保存为model.pkl或model.joblib格式。
- 为了满足GCP AI Platform的要求,我创建了一个新的脚本,用所需的模型版本将模型序列化为model.pkl,并上传到了Cloud Storage。更新后的代码可以在GitHub仓库中找到。
Model name: logistic_regression_model
勾选Use regional endpoint复选框。
Region: 欧洲西部2
在models部分,确保只勾选europe-west2区域。
为要创建的模型版本选择Save。创建模型版本可能需要几分钟时间。完成后,点击模型版本,然后导航到Test & Use标签页进行测试。输入数据,点击Test即可。