收到一个API响应,测试就通过了吗?不,这仅仅是验证之旅的起点。响应本身只是服务器“存活”的信号,真正的测试在于验证这个响应是否正确。这个验证机制,就是断言(Assertion)。断言的质量,直接决定了你的测试套件是能精准捕获Bug的猎手,还是只会“报平安”的摆设。
这篇文章,我们将深入探讨API断言:它的核心定义、值得编写的关键类型、团队常犯的错误,以及如何高效地构建它们,从而提升API测试的可靠性与自动化水平。
什么是 API 断言
简单来说,断言就是关于API响应的一条必须为真的陈述。你发起请求,API返回响应,断言则将响应的某个部分与你的预期值进行比较。匹配,则通过;不匹配,则失败。
没有断言的自动化测试,充其量只能证明端点(Endpoint)是可达的。而有了断言,才能证明端点是正确工作的。这两者之间的鸿沟,恰恰是许多线上事故的根源:API运行正常,返回了200状态码,但响应体(Body)里的数据却是错误的。
一个有效的断言,需要具备两个特质:具体和独立。具体,是为了在失败时能精准定位问题;独立,是为了避免它隐式地依赖另一个断言的成功。通常,一个测试步骤会包含多个断言,从不同维度审视同一个响应。
状态码断言,以及为什么它还不够
最常见的断言莫过于检查HTTP状态码:成功读取预期是200,创建资源是201,输入错误是400,认证缺失是401。这当然是必要的基线检查,正确使用状态码本身就是一门学问。
但问题在于,仅有状态码断言是极其脆弱的。API完全可以返回一个200 OK,但响应体却是空的、包含过期的数据、在应为对象的地方返回了null,甚至伪装成一个成功的错误消息。状态码只告诉你请求已被处理,却无法保证数据的正确性。
所以,请把状态码断言视为测试步骤的第一道防线,但绝不能是唯一的防线。
值得编写的断言类型
那么,除了状态码,我们还应该关注哪些方面呢?
响应体内容断言:检查响应中的实际数值。比如,id字段是否存在且非空;email是否与你发送的一致;total是否等于各项费用的总和。这类断言能捕获那些状态码会放过的逻辑漏洞。
Schema 断言:根据JSON Schema或OpenAPI定义,验证响应的结构(Shape)。检查必填字段是否存在、类型是否正确、是否出现了意外字段。它能有效捕获“契约偏移(Contract drift)”——即后端悄无声息地将一个字段从字符串改为对象,导致所有客户端崩溃的情况。
响应头断言:确认Content-Type是application/json,缓存头按预期设置,CORS头已存在,以及Strict-Transport-Security等安全响应头到位。
响应时间断言:设定一个延迟预算(比如800毫秒),当响应变慢时使测试失败。性能退化对其他所有功能断言来说都是隐形的,因此这是在功能测试套件中捕获性能问题的唯一手段。
错误格式断言:针对负面用例,不仅要断言4xx状态码,更要断言错误响应体的具体格式。例如,error字段等于validation_error,details数组指明了违规字段,且错误消息中没有泄露敏感数据。
安全断言:确认端点拒绝了没有Token的请求、拒绝了过期的Token、正确执行了用户间的权限校验,并且不会将注入载荷(Injection payloads)原样回显。
一个同时断言了状态码、几个关键响应体字段、Schema以及响应时间的测试步骤,才是在做实事。而一个只断言状态码的步骤,更像是走过场。
断言逻辑容易出错的地方
在实践中,编写断言时有几个常见的陷阱:
对易变数据过度断言:断言一个精确的created_at时间戳或生成的UUID,会导致测试每次运行都无故失败。正确的做法是断言该字段存在且类型正确,而非其精确值。
对正常路径断言不足:奇怪的是,团队往往在最常被触发的“正常路径”测试上写得最简略,可能只检查状态码。这恰恰是本应进行最详尽验证的场景。
顺序依赖的断言:如果断言B只有在断言A通过时才有意义,但两者都独立运行,那么A的失败会导致B产生令人困惑的二次失败。应通过测试结构明确这种依赖关系。
一个断言做两件事:“响应是正确的”这不是一个合格的断言。应该拆解它:状态码是200,token存在,expires_in等于3600。三个检查,三条清晰的失败信息。
忽略负面用例:团队往往在成功路径上重兵把守,却在失败路径上几乎不写断言。一个没有响应体断言的负面测试,只能证明API说了“不”,无法证明它“正确地”说了“不”。
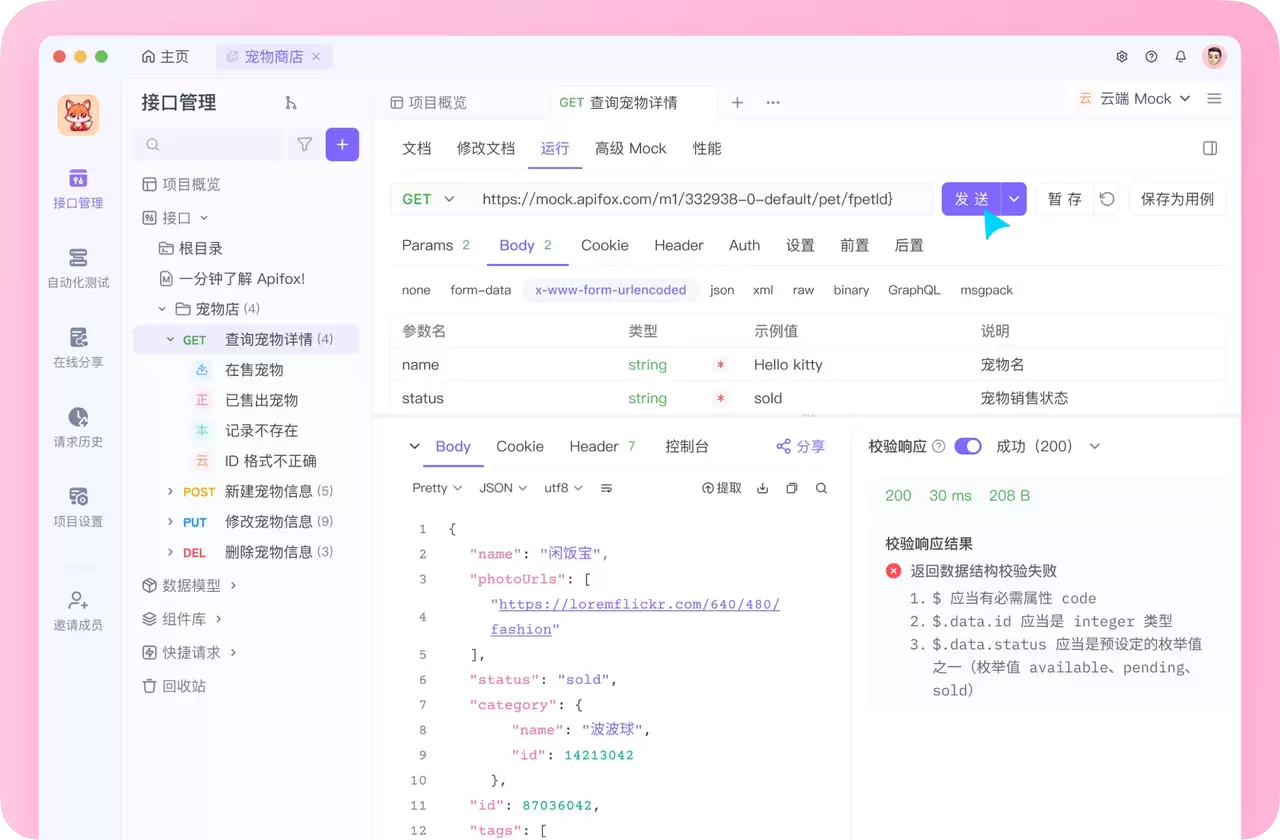
在 Apifox 中构建断言
在Apifox这类工具中,断言通常是可视化测试构建器的一部分,这意味着你可以通过点击而非编写脚本来定义它们。
操作流程大致如下:在测试场景中选择一个请求,打开断言面板并添加检查:
- 状态码断言:选择“响应状态码”并将其设置为等于
200。 - 响应体字段断言:使用JSONPath表达式(如
$.token)断言其存在且为非空字符串;断言$.expires_in等于3600。工具通常会读取响应结构,让你可以直接点选字段。 - Schema 断言:根据端点定义的Schema验证响应。由于API设计和测试在同一平台,断言使用的Schema就是文档发布的同一个,避免了副本不一致的问题。
- 响应时间断言:添加检查以确保响应时间低于设定的预算。
- 自定义脚本:仅在可视化检查无法表达复杂逻辑时使用,例如跨请求比较或条件检查。大多数断言无需走到这一步。
将这些断言组合在一个场景中统一运行。为了实现更广泛的覆盖,可以关联数据文件,让同一组断言针对多组测试数据运行。生成的报告会清晰显示哪个断言在哪个请求上失败了,并对比预期值与实际值。
一个完整的断言示例
以GET /users/{id}返回用户对象为例,一个健壮的正常路径断言集应包含:
- 状态码等于
200 Content-Type响应头包含application/json$.id等于请求的 id$.email存在且符合电子邮件格式$.role是admin、member、viewer中的一个- 响应体符合
UserSchema - 响应时间低于 600 ms
对于使用未知id的GET /users/{id}(负面用例):
- 状态码等于
404 $.error等于not_found- 响应体不包含
email、id或其他用户字段
两个请求,十一个断言,你就同时验证了契约、数据、响应头、性能和错误行为。这就是能守护发布的测试套件与仅仅“Ping”一下服务器的套件之间的本质区别。
CI 流水线中的断言
断言只有自动运行,才能发挥最大价值。每周手动运行一次的套件,捕获的是一周前的Bug。而集成到CI/CD流水线中的同一套件,能在代码提交或合并请求阶段就拦截问题。
在流水线中运行断言时,有两个设计原则至关重要:
失败信息必须明确无歧义。如果CI日志只说“测试失败”,开发者需要手动复现排查;但如果日志显示“预期$.expires_in等于3600,但在POST /auth/login中实际得到7200”,问题就能被立即定位。强有力的具体断言是产生这种可读性信息的关键。
断言需要在不同环境间保持稳定。如果断言硬编码了生产环境的用户ID,它在测试环境中就会因环境差异而非代码问题失败。应将环境特定的值保存在变量中,并对那些依赖环境的数据断言其结构和类型,而非精确值。Schema断言在这方面具有天然优势。
一个可行的实践模式是:将状态码和Schema断言作为每个端点的基准线,在所有环境中运行;然后在此基础上,叠加针对特定环境的数值断言。基准线可以捕获任何环境中的契约偏移,而数值断言则在有稳定数据的地方捕获逻辑Bug。两者结合,在每次提交时运行,测试套件就从一个简单的报告,升级为了一个可靠的质量关卡。
常见问题解答
断言和测试用例有什么区别?
测试用例是整个检查过程,包含一个请求及其预期结果。断言则是构成这个预期结果的单个比较项,决定了测试的通过或失败。
一个请求应该有多少个断言?
足以覆盖状态码、关键响应体字段、Schema和延迟预算即可。对于大多数端点,通常是四到八个。只要每个断言检查的是不同的维度,更多也是可以的。
我应该断言精确的响应体吗?
对稳定的字段进行精确断言,对易变字段(如时间戳、生成ID)则断言其类型或存在性。断言包含易变数据的完整响应体会导致测试脆弱不堪。
我可以在功能测试中断言 API 性能吗?
可以。响应时间断言可以在常规功能运行期间捕获延迟退化,基础的性能预算检查无需依赖单独的压力测试。
负面测试用例也应该有断言吗?
绝对应该,而且它们往往最容易被忽略。一个只检查状态码的负面用例,只能证明API说了“不”,不能证明它“正确地”说了“不”。务必断言具体的错误字段、详情,并检查是否泄露敏感信息。
什么时候应该使用自定义断言脚本?
仅在可视化构建器无法表达复杂逻辑时使用,例如需要进行跨请求比较、计算派生值或执行依赖于先前响应的条件检查。对于状态码、Schema、字段值、耗时等绝大多数检查,可视化方式更简洁且易于评审。