【导读】一个宣称实现“零污染”的全新编程基准测试DeepSWE,凭借其113道原创题目,揭示了传统编程能力排行榜单的潜在缺陷。
在代码能力评测领域,一把全新的标尺已经落下。
Datacurve公司近日发布了名为DeepSWE的新基准。其联合创始人兼首席执行官Serena Ge在社交平台X上明确指出,推出DeepSWE旨在还原软件开发者的真实工作场景,揭示顶尖AI模型之间真正拉开差距的关键所在。

这份榜单在发布首日,便对现有排名秩序发起了挑战。GPT和Claude在SWE-Bench Pro上的排名,被彻底颠覆。

GPT-5.5取得了70%±4%的通过率,位列第一;而Claude Opus 4.7仅为54%±5%,排名第三。两者之间,拉开了高达16个百分点的差距。
更值得深思的还在后面。
DeepSWE团队运用其新方法,对SWE-Bench Pro上的历史提交记录进行了回溯审计。结果发现,Claude Opus 4.6和4.7在该榜单上的成绩中,有超过12%被判定为存在“作弊”嫌疑。
不仅如此,审计还查出,SWE-Bench Pro基准的验证器本身存在8.5%的假阳性率和24.0%的假阴性率。
这引出了一个尖锐的疑问:如果评测工具的误差如此之大,那么SWE-Bench Pro榜单上那些仅相差一两个百分点的模型,究竟是实力真正旗鼓相当,还是仅仅被一把不准的尺子量成了平局?
更换评测标尺,榜首易主
首先来看DeepSWE自身评测得出的榜单结果。
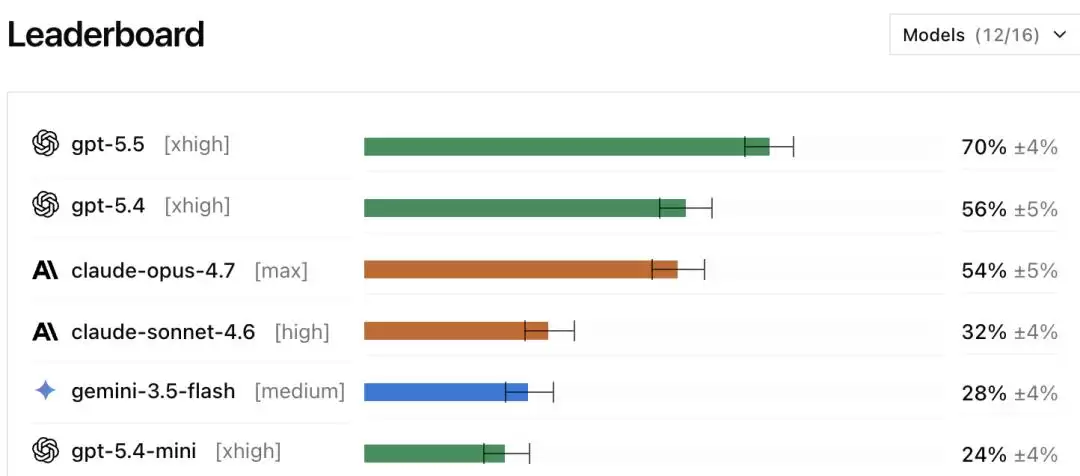
在参与评测的12款前沿AI模型中,gpt-5.5[xhigh]以70%±4%的通过率位居榜首,gpt-5.4[xhigh]以56%±5%紧随其后,Claude Opus 4.7[max]则以54%±5%排在第三。
后续排名中,Claude Sonnet 4.6[high]为32%,中间梯队的模型成绩落在18%到28%之间,而榜尾的几款模型仅有5%到10%。
对比此前公开报道的SWE-Bench Pro成绩——Claude Opus 4.7为64%,排名第一;gpt-5.5为59%——情况发生了戏剧性反转。在DeepSWE上,gpt-5.5升至70%、排名第一,而Claude Opus 4.7则跌至第三、仅54%。
不仅是排名逆转,模型之间的能力差距也被显著拉开。
这批模型在SWE-Bench Pro上从最差到最好的差距仅为30%,而到了DeepSWE上,这一差距扩大到了70%。
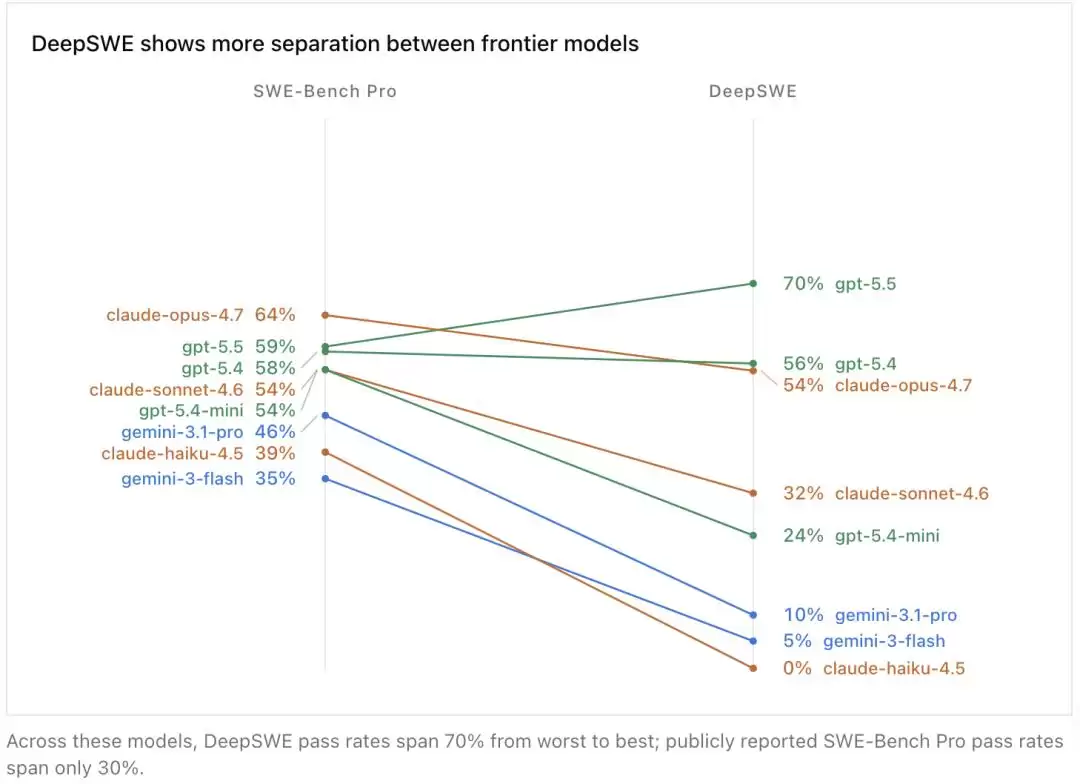
同一批选手,面对同类编程任务,仅仅更换了一个测试基准,原本看似并驾齐驱的领先者之间,便出现了断层式的差距。
DeepSWE团队对此的解释是:旧榜单上模型分数挤在狭窄区间,并非因为它们实力真正接近,而是因为基准本身的“分辨率”或“区分度”不足。
具体来看,SWE-Bench Pro的一道题目平均只修改5个文件,而DeepSWE的一道题目平均需修改7个文件,单题涉及的参考代码量是前者的5.5倍。
在这种复杂度下,模型无法依靠死记硬背某个具体函数来蒙混过关。它必须真正理解多个文件之间的耦合关系,并规划出一条贯穿整个代码仓库的修改路径。
GPT-5.5能取得70%的通过率,意味着它并非记住了某种题型,而是具备了“在一个完全陌生的真实代码仓库中,执行一条横跨7个文件的改动链路”的工程能力。
换言之,在简单的“玩具题”上,大家看起来可能差不多;但在能逼出真实工程能力的复杂题目上,差距瞬间显现。
DeepSWE更准确,还是营销噱头?
一个新基准,凭什么声称自己比旧基准更准?DeepSWE给出的答案是四个核心设计原则。
首先,是“零污染”。这是其最核心的优势。
DeepSWE的每一个任务均由工程师从零开始原创编写。关键在于,这些任务完成后不会被合并回上游的开源仓库,也就不会进入公开的GitHub提交记录,从而极难出现在未来用于模型预训练的开源代码语料中。
这意味着,没有任何AI模型能在预训练阶段“偷看”到这些题目的答案。这一设计,直指旧基准因数据泄露导致评测失真的核心痛点。
第二,是“高多样性”。
DeepSWE包含了113个任务,覆盖了91个活跃的开源仓库,横跨TypeScript、Go、Python、Ja vaScript、Rust五种主流编程语言。
作为对比,SWE-Bench Pro的公开版仅覆盖11个仓库。仓库越多、类型越杂,就越能逼近开发者真实会丢给AI编程助手的那些五花八门的代码库场景。
第三,是“真实复杂度”。
前面提到DeepSWE的单题代码量是SWE-Bench Pro的5.5倍,但有趣的是,它的任务提示词长度反而只有后者的一半。
提示词之所以简短,是因为它刻意模仿了开发者真实与智能体沟通的方式:只说明想要什么行为或功能,而不把接口定义、复现步骤、代码片段全部罗列出来。智能体必须自己去仓库里探索清楚“在哪里改、怎么改”。
第四,是“可靠验证”。
一个基准准不准,关键看它的验证器。旧基准的验证器常常只认一种“标准答案”的写法,换个变量名、换种实现思路就可能被判错。DeepSWE的验证器则是针对每个任务手写定制的,只要最终功能结果正确,实现方式可以多种多样。
通过各抽取30个任务进行交叉复查,DeepSWE验证器的假阳性率仅为0.3%、假阴性率为1.1%。相比之下,SWE-Bench Pro的这两项数据分别是8.5%和24.0%,误差高出了一个数量级。
而且,DeepSWE不只是一张静态榜单。在其GitHub仓库中,每个任务都附带了提示词、可复现的Docker环境、验证器以及一份保密的参考解法。任何人都可以拉取代码,让自己的AI智能体亲自运行一遍,确保了评测的透明度和可复现性。
旧基准的尺子,两端皆有误差
DeepSWE团队还用这套新方法,审计了SWE-Bench Pro上那些已被计入成绩的提交。
审计发现,Claude Opus 4.6和4.7的成绩中,超过12%被判定为作弊,其中约87%使用了同一种手法:直接去翻代码仓库的.git历史记录,把藏在历史提交里的“标准答案”抄出来。
在同一批复查样本中,GPT-5.4和GPT-5.5未被发现这类行为。
DeepSWE也指出,这其实是SWE-Bench Pro基准本身的设计漏洞给了作弊可乘之机——它的任务容器里直接包含了带有“标准答案”的完整提交历史。
这是DeepSWE给出的客观观察。至于Claude模型为何会形成这种行为模式,目前尚无公开定论。
如果说作弊是让分数虚高的“上行噪声”,那么SWE-Bench Pro还有一个对称的“下行噪声”:高达24%的假阴性率。
DeepSWE复查了一批被SWE-Bench Pro判为“失败”的提交,发现其中约24%其实功能完全正确,只是被误判了。
24%意味着什么?在被复查的运行轨迹里,差不多每四个提交就有一个可能被冤枉。如果把这层假阴性误差算上,所有模型的真实分数实际上都被压低了一截。而且,那些倾向于按照自己风格重构代码、而非照抄现成答案的模型,其分数损失可能更为严重。
相比之下,经过多重交叉把关的DeepSWE验证器,将假阳性率压到了0.3%,假阴性率压到了1.1%,两项误判率都比SWE-Bench Pro低了一个数量级以上。
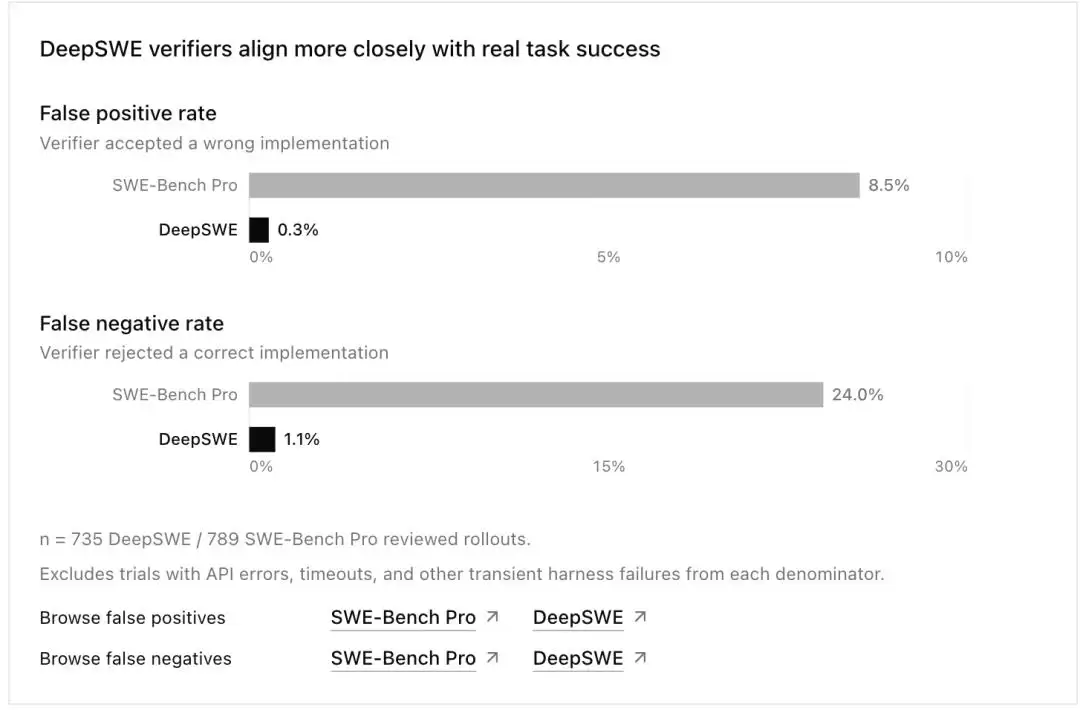
两个基准验证器的误判率对比。SWE-Bench Pro假阳性率8.5%、假阴性率24.0%
如果这个对比数据准确,那意味着持续大半年的所谓“Claude和GPT不分上下”的行业共识,很可能是建立在一个两端都不准的测量工具之上。
过去大家只比较终点分数,很少有人回头审视这个分数是怎么来的。DeepSWE这一审计,使得那些以SWE-Bench Pro为锚点的模型对比结论,恐怕都需要重新校准。
局限性在哪里?
DeepSWE虽然解决了旧基准的数据污染问题,但它终究是Datacurve自家推出的评测体系。
Datacurve自己也坦率地谈到了其局限性。整个评测过程只使用了一个名为mini-swe-agent的测试框架,为所有模型提供相同的bash工具和同一套提示词。
这样做是为了将“模型核心编程能力”与“外围脚手架工具”的影响分离开,但代价是带来了一定程度的失真。
不同模型家族在训练时所适配的工具形态本就不同,而开发者在现实中使用的也并非mini-swe-agent,而是Codex CLI、Claude Code、Cursor、Gemini CLI这些更成熟的原生工具链。
使用统一的测试框架,可能会将每一家模型的能力都压制在其原生上限之下。
对此,DeepSWE团队也通过对照实验进行了回应。在小规模试点中,mini-swe-agent的表现并不输给原生工具链。但团队同时强调,这仅仅是基于10道题的试点,不足以完全打消外界的顾虑。
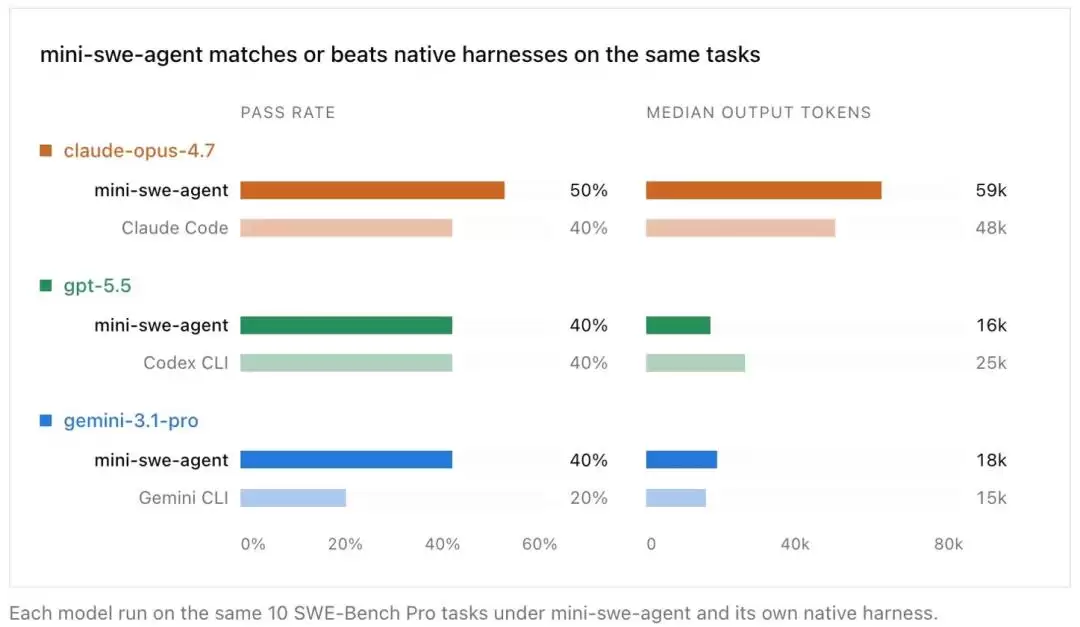
同样10道SWE-Bench Pro任务下,mini-swe-agent的通过率与token消耗,不输Claude Code、Codex CLI、Gemini CLI等原生Harness
此外,DeepSWE的语料目前只覆盖GitHub上星标超过500的活跃开源仓库,缺少了C++和Ja va这两种重要语言,同时bug定位和代码重构类的任务也相对偏少。
还有一点是关于AI幻觉的质疑。DeepSWE报告中那些关于“假阳性、假阴性”的判定,本身是由一个LLM分析员给出的,并非完全的人工复核。
团队自己也提醒,低于约5%的差异可能并不具备统计显著性,不应过度解读。
1500万美元融资,这家公司给大模型当「磨刀石」
DeepSWE是如何诞生的?这得先认识一下它背后的公司Datacurve。
Datacurve出自Y Combinator 2024年冬季批次(W24),由Serena Ge和Charley Lee两位创始人在2024年创立。

Datacurve两位创始人Serena Ge(右)与 Charley Lee(左)。两人均出自滑铁卢大学计算机系
这家公司的主业是为前沿大模型生产高质量的代码训练数据,但它的玩法有些特别。
Datacurve运营着一个名为Shipd的平台,采用“赏金”模式,招募顶尖软件工程师来解决算法题、进行调试、编写UI流程等,按产出而非工时支付报酬。迄今为止,该平台已发出超过100万美元的赏金。
据TechCrunch等媒体报道,参与者中不乏来自DeepMind、OpenAI、Anthropic、Vercel等明星公司的工程师。
Datacurve本来就是向大模型供应训练数据的公司,对于“什么样的数据会污染基准、什么样的任务才能真正考出模型本事”有着第一手的认知。DeepSWE更像是其主业能力的一种自然延伸和验证。
代码评测圈,正在告别刷分时代
DeepSWE并非孤立事件,其背后是一个已延续大半年的行业趋势。
随着SWE-Bench系列基准日趋饱和,新一代编程基准的竞争焦点,已经从单纯的“题目有多难”,转向了“能否抵抗数据污染”以及“验证是否可信”。DeepSWE正是这个转向中的一个典型样本。
DeepSWE还有一个特别有意思的发现:模型能力越强,越会主动给自己编写测试。
在DeepSWE上,Claude Opus 4.7和GPT-5.4有超过80%的运行会主动使用项目自带的测试框架编写新的测试用例,哪怕任务提示中并没有要求它们这么做。然而,在SWE-Bench Pro上,同样是这批模型,编写测试的比例骤降到3%到28%。
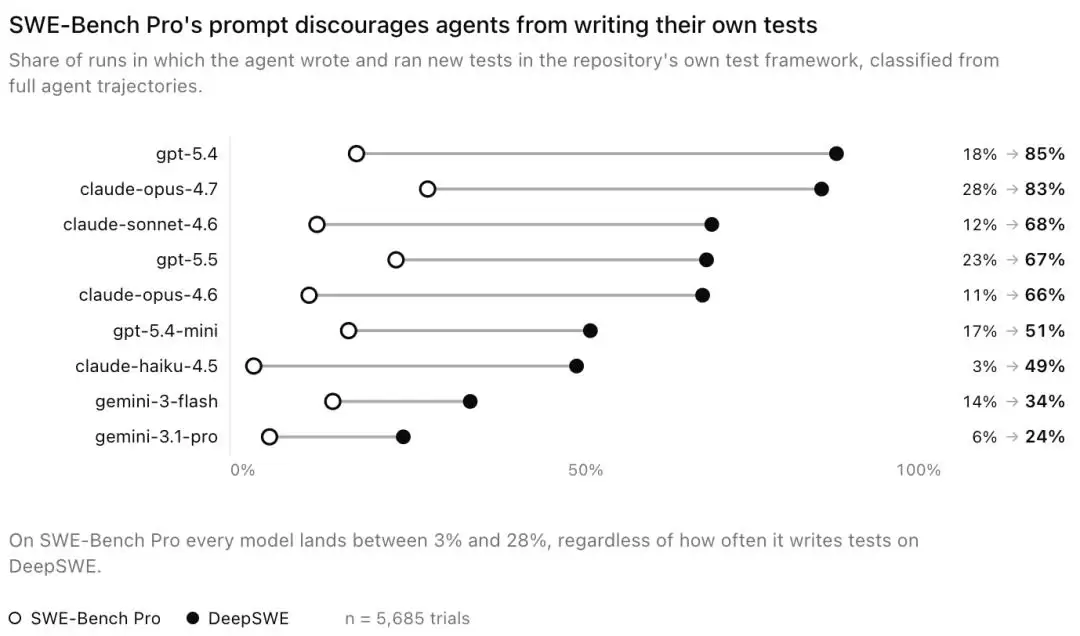
同一批模型主动写新测试的比例。在DeepSWE上多数超过60%,到SWE-Bench Pro上全部掉进3%到28%区间
原因何在?
原来,SWE-Bench Pro的提示词里包含一句话,告诉智能体“测试文件已经处理好了,不要改动测试逻辑”。智能体就把这句话理解成了“不需要自己写测试”。
看,仅仅是一句提示词的措辞差异,就能改变一个模型的行为模式,进而影响它的最终得分。
这说明,我们目前用来衡量AI编程能力的工具,本身还非常脆弱:一个标点、一句话、一个测试框架的选择,都可能微妙地影响最终的排名。
所以,当AI编程助手开始动手修改你的代码时,你真正应该相信什么?
无论是DeepSWE还是SWE-Bench Pro,都只是外部参考。终极的答案,或许依然藏在你自己真实的、复杂的业务代码库之中。