
随着大模型处理长上下文的需求日益增长,KV Cache的显存瓶颈正从计算量转向存储与带宽。每次生成新token时,系统都需要反复访问不断增长的历史Key和Value缓存,当上下文长度和批处理规模扩大时,KV Cache会急剧吞噬宝贵的显存资源。近日,Together AI开源了OSCAR(Offline Spectral Covariance-Aware Rotation)方案,这是一套面向实际生产环境的、接近2-bit精度的KV Cache量化解决方案。其核心设计理念在于:目标不仅仅是精确还原K/V向量本身,而是要确保注意力机制在消费这些压缩后的KV时,其计算行为与原始高精度时保持一致。目前,该方案已无缝集成至SGLang推理引擎,可直接用于实际服务部署。在平均约2.28比特每元素(BPE)的配置下,其推理性能已非常接近BF16全精度基线。相较于3-bit的TurboQuant方案,OSCAR在部分评测任务上最高可提升40.1分,解码速度最高提升约3倍,任务级吞吐量最高提升约7倍。
Together AI此次开源了完整的OSCAR项目,包含以下核心资源:
- 完整代码库:提供了端到端的校准、旋转矩阵拟合与性能评估流程,并已与SGLang的服务路径深度集成。
- RotationZoo预计算矩阵库:为多个主流开源模型预计算了即插即用的旋转矩阵(
.pt文件),用户无需自行运行耗时的校准流程,可直接下载使用。
目前支持的模型包括Qwen3-4B-Thinking、Qwen3-8B、Qwen3-32B、GLM-4.7-FP8以及MiniMax-M2.7。
深入解析KV Cache的显存瓶颈
将历史KV稳定压缩至2-bit,理论上可将存储开销降低近8倍。然而,低比特KV Cache量化的真正挑战并非“能否压缩”,而在于压缩后模型推理质量不能显著下降,且方案必须能在真实的推理系统中高效部署,而非仅停留在离线实验阶段。OSCAR的价值,正是同时在这两大难题上给出了切实可行的答案。
2-bit整数仅有4个离散等级,而KV激活值中常存在少量幅值极大的异常通道。若量化尺度被这些极端值主导,绝大多数正常值将被挤压在极窄的有效区间内,导致注意力分布发生严重偏移。传统的哈达玛德旋转虽能打散异常值,却无法精准识别并保护模型在注意力计算中真正敏感的关键方向。
OSCAR的核心设计动机
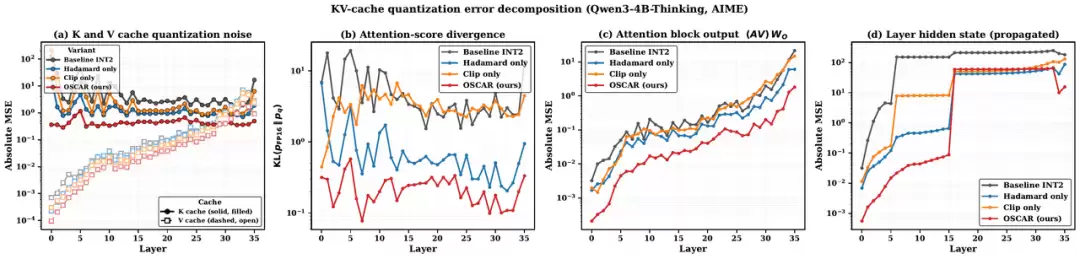
图1:仅关注K/V重建误差容易低估低比特量化对最终生成质量的真实影响
图1对比了朴素INT2量化、仅应用哈达玛德旋转、仅进行裁剪以及OSCAR方案在整个误差传播链路上的表现。它揭示了一个关键点:原始K/V向量的重建误差并不能充分预测模型最终的生成质量。更直接影响模型表现的,是注意力分数分布的KL散度、注意力块输出的均方误差,以及这些误差向后传播至后续隐藏状态所产生的累积效应。OSCAR的优势不仅在于使数值分布更平滑,更在于其能将量化噪声尽可能地引导至注意力机制相对不敏感的方向上。
OSCAR技术方案详解
具体而言,对于Key向量,其量化误差会通过QKᵀ乘积进入注意力对数域,因此OSCAR利用查询向量(Query)的协方差矩阵(即QᵀQ)来决定Key的旋转目标方向。对于Value向量,其误差会先经过注意力权重加权,再影响注意力输出,因此OSCAR采用经过注意力分数加权的Value协方差矩阵(即VᵀSᵀSV)。在离线校准阶段,系统使用少量校准样本来估计这些与注意力感知相关的协方差,并为每一层、每一个注意力头生成固定的旋转矩阵和裁剪阈值。
最终的旋转操作可表示为 R = U · Hadamard · bit-reversal。其中,矩阵U负责对齐与注意力敏感度相关的方向;哈达玛德矩阵负责将异常值的能量均匀摊开;而比特反转置换则确保INT2分组更加均衡,避免某个分组被少数通道主导。这意味着,OSCAR并非简单地“添加一个旋转步骤”,而是将旋转、裁剪和分组全部纳入一个以优化注意力质量为目标的统一框架中。
更重要的是,OSCAR已深度集成到SGLang的服务路径中,实现了生产级部署。在运行时,它维护一个三段式的token内存池:
BF16 sink (64 tokens) | INT2 history | BF16 recent (256 tokens)
位于序列开头的sink token和最近的recent窗口仍以BF16精度保存,用以保护注意力汇聚点与最新上下文的信息完整性;中间占比最大的历史段则保存为旋转后的INT2格式。新生成的token会先写入recent窗口,随着解码过程推进,最老的recent token会通过一个融合的Triton内核完成旋转、裁剪、量化和打包操作,随后降级进入INT2历史段。在存储层面,每4个2-bit数值被打包进1个字节,极大提升了存储密度。
在解码阶段,OSCAR在GPU上并行处理BF16段和INT2段:INT2内核负责解包、尺度/零点反量化及浮点累加;BF16内核处理sink和recent部分;最后通过在线softmax合并两部分结果。由于该方案完全兼容分页KV缓存、基数前缀缓存以及SGLang的融合内核流水线,因此OSCAR面向的是真实的企业级工作负载,而不仅仅是展示论文中的离线误差指标。
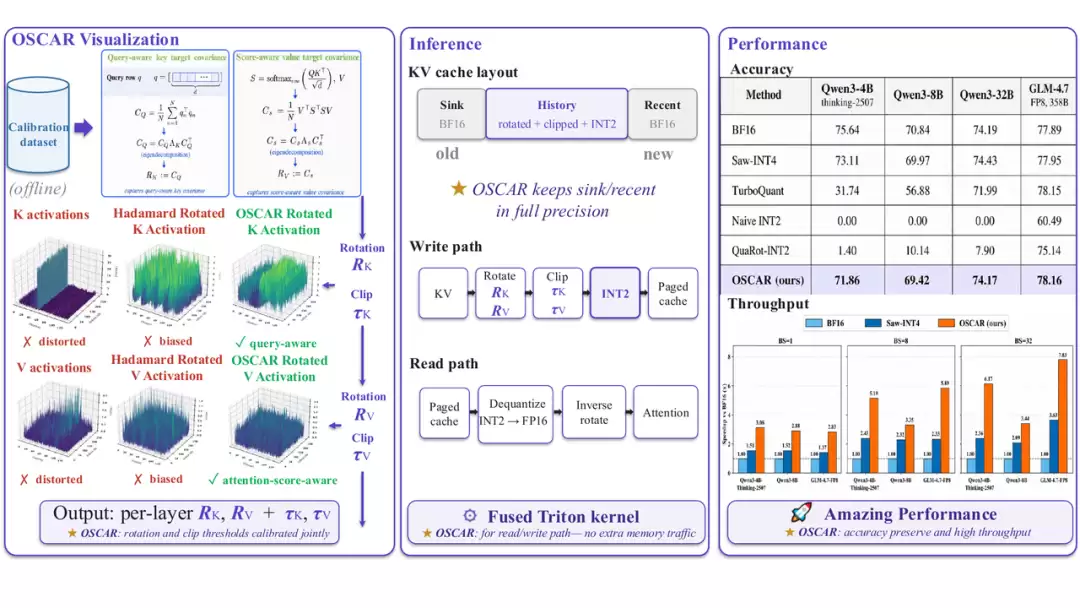
图2:OSCAR从离线校准到在线推理的完整技术链路
图2展示了OSCAR的完整技术流水线。左侧为离线校准阶段:系统从少量样本中估计出注意力感知的旋转矩阵与裁剪阈值,使KV激活值在进入INT2量化前更适合低比特表示。右侧为在线推理阶段:sink和recent部分保留BF16精度,中间最长的历史KV进入旋转后的INT2缓存,并在SGLang的分页KV体系内完成真实的服务请求。简而言之,OSCAR不是一个孤立的量化技巧,而是一整套面向2-bit KV Cache的生产级服务解决方案。
性能与精度评估
研究论文在Qwen3-4B-Thinking、Qwen3-8B、Qwen3-32B和GLM-4.7-FP8等多个模型上进行了全面测试,任务覆盖GPQA、HumanEval、LiveCodeBench v6、AIME25和MATH500,生成长度设置为32K,每个配置运行5次取平均值。结果显示,在2.28 BPE配置下,OSCAR表现卓越:Qwen3-4B-Thinking距离BF16基准仅差3.78分,Qwen3-8B仅差1.42分;在Qwen3-32B和GLM-4.7-FP8上,整体表现已基本与BF16全精度持平。
对比方案的情况则严峻得多:QuaRot-INT2和朴素INT2在推理和代码任务上经常完全失效;TurboQuant在全层3-bit K/V、无混合精度保护的公平设置下,小模型的推理分数也存在明显损失。论文还在128K超长上下文下进行了RULER-NIAH检索测试,OSCAR在Qwen3-8B与GLM-4.7-FP8上都保持了更稳定的检索能力,这表明注意力感知的旋转不仅适用于短基准测试,也能有效缓解超长历史中KV误差逐步累积的根本性问题。
系统层面的收益同样显著。相比BF16历史存储,OSCAR可将KV Cache内存占用压低约8倍;在100k上下文、批大小为1、完全前缀缓存命中的设置下,解码速度最高提升约3倍;在大批次且显存预算固定的情况下,任务级吞吐量最高提升约7倍。前缀缓存命中率越高,更小的KV内存占用就越能转化为更高的并发吞吐量,这对于共享系统提示、多轮智能体对话和工具调用循环等长前缀高复用场景具有重大意义。
量化精度深度对比
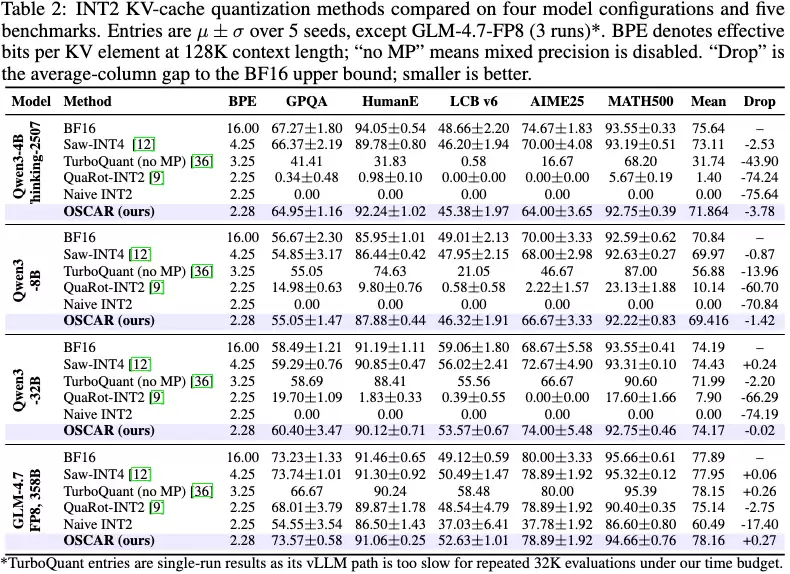
图3:主评测结果表,多种KV量化方法在同一评测设置下的综合对比
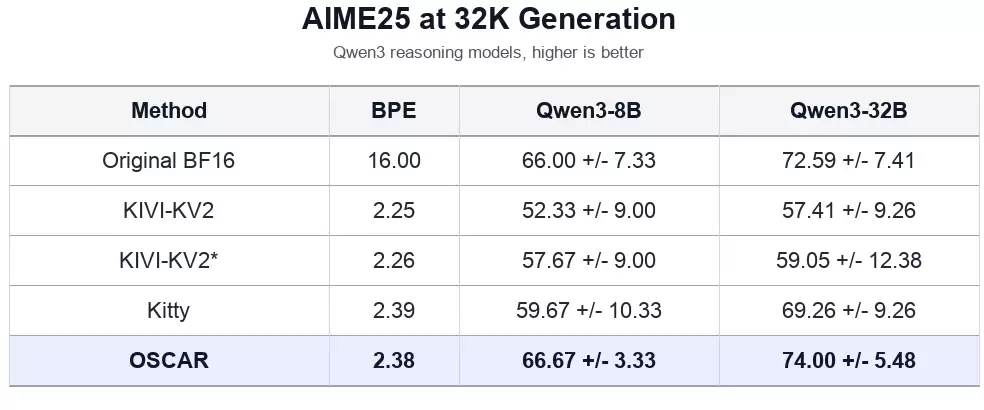
图4:AIME25 32K生成场景下,OSCAR与KIVI / Kitty的专项性能比较
图3是论文的核心结果对比表,将BF16、Saw-INT4、TurboQuant、QuaRot-INT2、Naive INT2和OSCAR放在四个模型、五个任务上进行横向比较。其中,BF16作为精度上界;Saw-INT4是4-bit的强参考基线,BPE为4.25;TurboQuant在此采用无混合精度保护的全层3-bit K/V,BPE为3.25;QuaRot-INT2与Naive INT2则代表接近2-bit的旋转基线和朴素基线,BPE约为2.25;OSCAR的运行预算为2.28 BPE。
此表的关键在于观察低比特方案能否在不同模型上稳定工作。以Qwen3-4B-Thinking为例,TurboQuant平均分为31.74,QuaRot-INT2仅为1.40,Naive INT2为0.00;而OSCAR达到71.86分,距离BF16仅差3.78分,并且比TurboQuant高出40.1分。在Qwen3-8B上,OSCAR平均分为69.42,BF16为70.84,TurboQuant为56.88。到了Qwen3-32B和GLM-4.7-FP8,OSCAR已与BF16基本持平,展现了卓越的模型泛化能力。
图4专门针对高难度的数学推理任务AIME25,加入了与KIVI-KV2、Kitty等方案的对比。由于KIVI和Kitty缺乏可直接用于长上下文运行的框架支持,论文选取了它们唯一在32K长度下汇报的AIME25结果。在Qwen3-8B上,OSCAR以2.38 BPE达到66.67分,几乎追平BF16的66.00分,并显著高于KIVI-KV2与Kitty;在Qwen3-32B上,OSCAR达到74.00分,略高于BF16的72.59分,也超过了Kitty的69.26分。这证明OSCAR的优势不仅体现在与TurboQuant的比较中,在现有的KV缓存量化方法里,它也能以接近2-bit的预算守住困难的数学推理能力。
系统加速效果分析

图5:100k长上下文下的解码加速与批次吞吐量提升
图5展示了在100k上下文长度下的系统性能。在批大小为1且完全前缀缓存命中的纯解码场景中,OSCAR最高带来约3倍的加速;当显存预算固定、批次大小持续增大时,INT2历史段使得KV内存占用显著下降,从而将任务级吞吐量推高至最多约7倍。其含义非常明确:OSCAR不仅在精度曲线上表现出色,也切实减轻了显存和带宽压力,带来了实质性的系统加速。
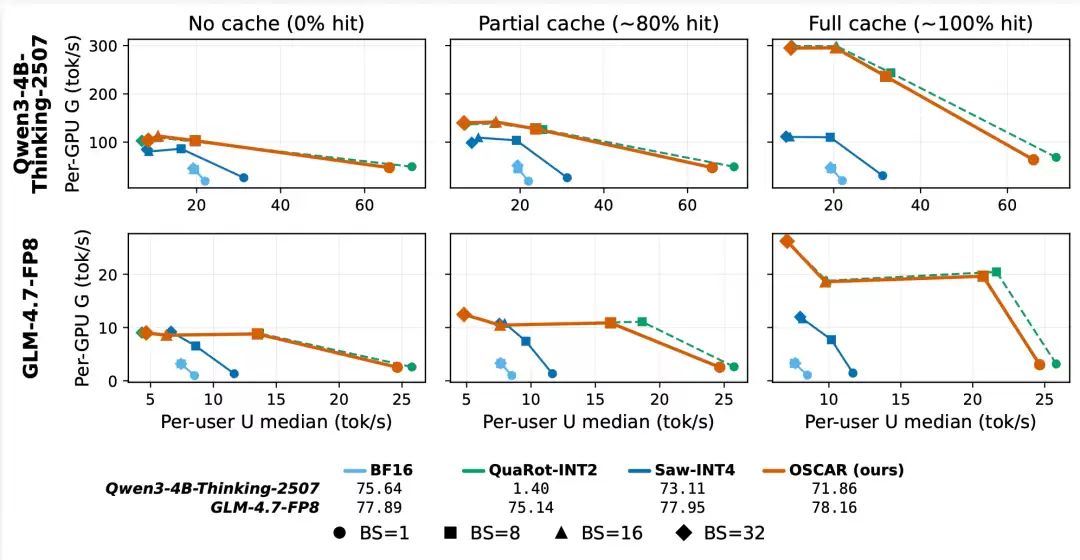
图6:前缀缓存命中率提升对端到端服务吞吐量的影响
图6展示了前缀缓存命中率对端到端服务吞吐量的关键影响。横轴为单用户吞吐量,纵轴为单GPU吞吐量;从关闭缓存,到启用普通缓存,再到接近100%的预热回放,系统的吞吐前沿会逐步向外扩张。由于OSCAR保留了标准的分页KV/前缀缓存抽象,因此共享系统提示、多轮智能体对话、工具调用链路这类长前缀高复用场景可以直接从中获得显著的吞吐量收益。
另一点值得强调的是:OSCAR并未通过“在少数敏感层保留高精度”这种常见技巧来换取分数。许多低比特方法在部署时会将第一层、最后一层或若干敏感层保留在更高比特,这会抬高平均比特数,并使内核和缓存布局变得复杂。OSCAR的设置更贴近真实服务需求:历史KV主体统一使用INT2,仅在sink和recent两个很小的窗口保留BF16。这使得它更容易无缝接入现有的分页缓存、前缀缓存和批量调度系统。
快速上手实践指南
如何使用OSCAR在SGLang上部署2-bit KV Cache推理服务
1. 下载预计算旋转矩阵
pip install modelscope
modelscope download --model zzz879978/OSCAR-RotationZoo --include "Qwen3-8B/**" --local_dir ./oscar_rotations2. 启动SGLang推理服务
克隆OSCAR仓库并配置好环境后,使用预计算的旋转矩阵启动服务:
SGLANG_ENABLE_MIXED_KV_WINDOWS=1
SGLANG_OSCAR_ROTATION_MODE=oscar
SGLANG_OSCAR_K_ROTATION_PATH=./oscar_rotations/Qwen3-8B/seq20000_prompt83_group128/k_rotation_qqt_r_h_pbr.pt
SGLANG_OSCAR_V_ROTATION_PATH=./oscar_rotations/Qwen3-8B/seq20000_prompt83_group128/v_rotation_sst_r_h_pbr.pt
SGLANG_OSCAR_K_CLIP_RATIO=0.96
SGLANG_OSCAR_V_CLIP_RATIO=0.92
SGLANG_OSCAR_ABSORB_V_ROTATION=1
SGLANG_MIXED_KV_PREFIX_TOKENS=64
SGLANG_MIXED_KV_RECENT_TOKENS=256
HADAMARD_ORDER=128
SGLANG_USE_MODELSCOPE=true python -m sglang.launch_server --model-path Qwen/Qwen3-8B --tensor-parallel-size 1 --kv-cache-dtype int2 --kv-cache-quant-group-size 128 --trust-remote-code运行时,KV Cache将自动维护三段式token池:BF16 sink(64 tokens)+ INT2 history + BF16 recent(256 tokens),历史段统一使用INT2,并兼容paged KV和prefix cache机制。
3. 从头复现旋转矩阵(可选)
如需在自定义校准数据集上拟合旋转矩阵,可执行以下步骤:
git clone https://github.com/FutureMLS-Lab/OSCAR.git
cd OSCAR
bash rotation/qwen3-8B/sa ve_qkv_8b.sh # 阶段1:转储模型的Q/K/V激活值
bash rotation/qwen3-8B/compute_rotation.sh # 阶段2:拟合注意力感知旋转矩阵目前RotationZoo已覆盖Qwen3-4B/8B/32B、GLM-4.7-FP8和MiniMax-M2.7等模型,更多模型的预计算旋转矩阵将持续更新。
总结与展望
OSCAR的意义远不止于在小模型或短上下文上取得高分。该研究同时覆盖了从4B、8B到32B乃至GLM-4.7-FP8等不同规模的模型;既评估了数学、代码、知识问答等32K推理生成任务,也测试了128K RULER-NIAH长上下文检索能力。在短任务中,它能无限逼近BF16精度;在长上下文中,它也能让注意力分布随历史增长保持稳定。这证明注意力感知的旋转设计并非针对某个特定基准测试调参,而是在从根本上解决KV误差随上下文长度累积这一核心挑战。
从实际应用角度看,这对于长上下文智能体至关重要。真实的智能体应用往往包含冗长的系统提示、工具说明、历史对话和检索内容,且不同请求间存在大量共享前缀。如果KV Cache全部使用BF16,显存很快会成为性能天花板;如果直接使用朴素的INT2量化,推理链条又可能严重失真。OSCAR在二者之间提供了一种系统化的折中方案:长历史部分用INT2大幅降低容量和带宽需求,关键的sink和recent部分用BF16保证稳定性,再通过前缀缓存高效复用共享前缀。
TurboQuant仍然是强大的通用在线向量量化方法;而OSCAR则更专注于注意力感知的2-bit KV服务化部署。两者并非互斥选择,目前OSCAR的注意力感知旋转机制已在实现上与Lloyd-Max码本相结合,将压缩率推向新的极限。OSCAR带来的关键启示是:若要让2-bit KV Cache真正投入生产,旋转设计不能只追求“存在”,而必须精准对准注意力机制的计算特性;同时,整个方案必须作为真实服务系统的一部分进行协同设计。