在之前的文章中,我们分享了《Agent写的高性能Host-to-Device传输库》,有读者在评论区指出,CUDA 12.8版本中新增了一个名为cudaMemcpyBatchAsync的API。本文将对这个新API进行深度性能评测与解析,相关测试代码已同步更新至项目仓库。
核心结论
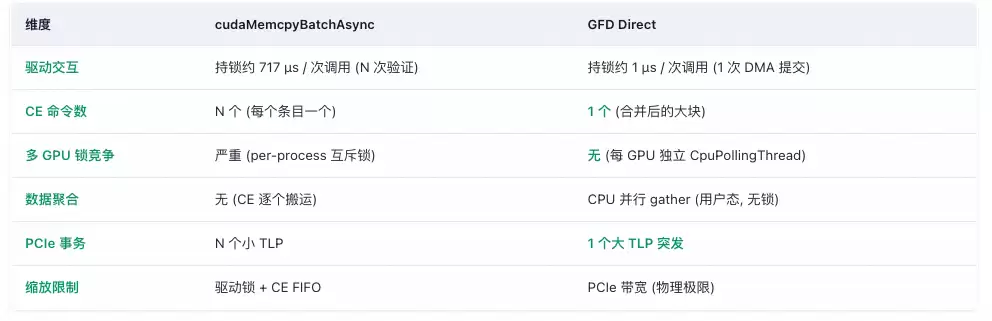
简而言之,cudaMemcpyBatchAsync这一新API确实能够将多次内存拷贝调用合并为单次提交,显著降低了API调用的开销。然而,在处理海量、离散的小规模数据块拷贝时,其底层实现机制决定了性能存在上限,与经过专门优化的方案相比仍有差距。特别是在多GPU并行计算场景下,其驱动锁的竞争问题会暴露得更为明显。
1. cudaMemcpyBatchAsync API 详解
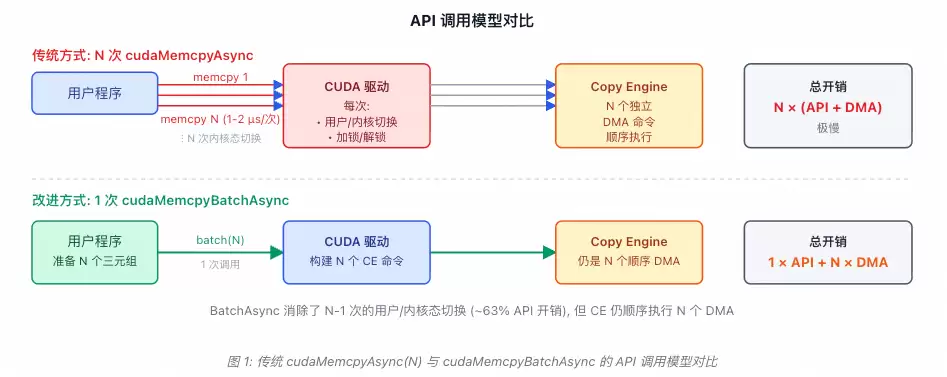
这是CUDA 12.8引入的一项用于批量异步内存拷贝的新功能。其设计目标非常明确:当您需要将N个独立的CPU内存块传输到GPU时,传统方法是调用N次cudaMemcpyAsync,每次调用都会产生约1-2微秒的API开销。如果N非常大,例如在大语言模型(LLM)推理中需要处理成千上万个KV缓存块,这部分开销将成为主要的性能瓶颈。
cudaMemcpyBatchAsync的核心价值在于,它将N个拷贝请求打包,通过一次API调用提交给GPU驱动统一处理,从而避免了N-1次用户态与内核态之间的上下文切换开销。
// API 函数签名
cudaError_t cudaMemcpyBatchAsync(
void* const* dstArray, // 目标地址数组(N个元素)
const void* const* srcArray, // 源地址数组(N个元素)
size_t* sizeArray, // 拷贝大小数组(N个元素)
size_t count, // 拷贝条目总数 N
cudaMemcpyAttributes* attrArray, // 内存拷贝属性数组
size_t* attrIdxArray, // 每个条目对应的属性索引数组
size_t numAttrs, // 属性种类数量
cudaStream_t stream // 执行拷贝的CUDA流
);
// cudaMemcpyAttributes 结构体定义
struct cudaMemcpyAttributes {
cudaMemcpySrcAccessOrder srcAccessOrder; // 源内存访问顺序
unsigned int flags; // 保留标志位(目前设为0)
};关键参数解析如下:

那么它的内部工作原理是怎样的呢?
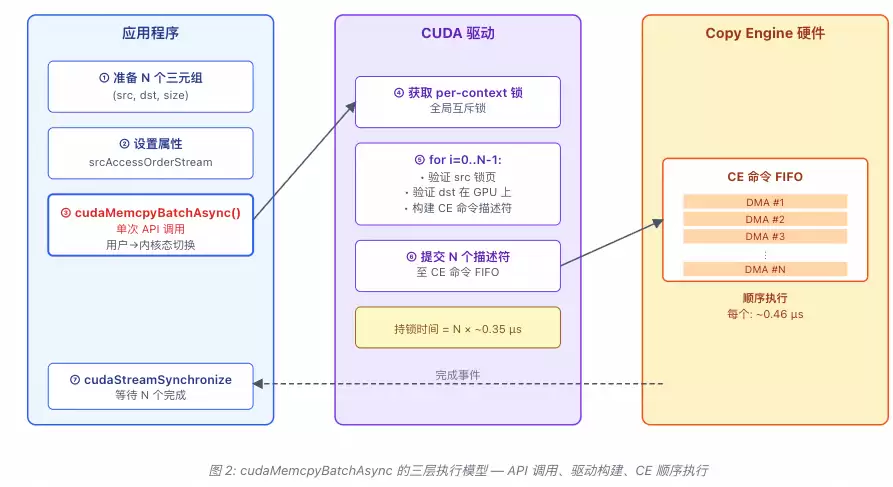
- 主要优势: 将N次独立的API调用合并为1次,消除了绝大部分的调用开销,提升了提交效率。
- 固有局限: 在驱动内部,它仍然需要为每个独立的拷贝条目生成单独的Copy Engine (CE) DMA命令,并且这些命令是顺序执行的。这正是其性能潜力受到制约的根本原因。
2. 性能基准测试结果
理论分析需要数据支撑,下面直接展示实测性能对比。
测试平台配置
- GPU: NVIDIA RTX PRO 5000 72GB (Blackwell架构, sm_120)
- PCIe: 第五代 x16 通道 (实测带宽约 53 GB/s)
- CPU: 256核心,2个NUMA节点
- GFD配置: 15个数据收集(Gather)工作线程,3个CE通道,5倍大页暂存缓冲区
- 数据布局: Token以2倍步长分散在锁页(Pinned)CPU内存中
- 测试方法: 每个配置运行50次迭代,前15次作为预热不计入结果
测试代码位于项目中的examples/04_benchmark.cu文件,执行./gfd_benchmark命令即可运行。
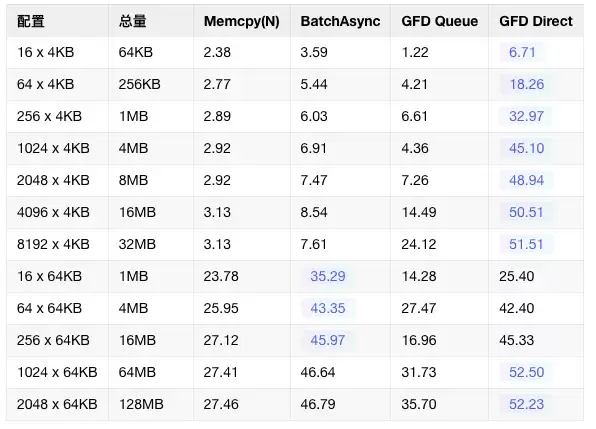
从性能对比图表中可以清晰地观察到以下趋势:
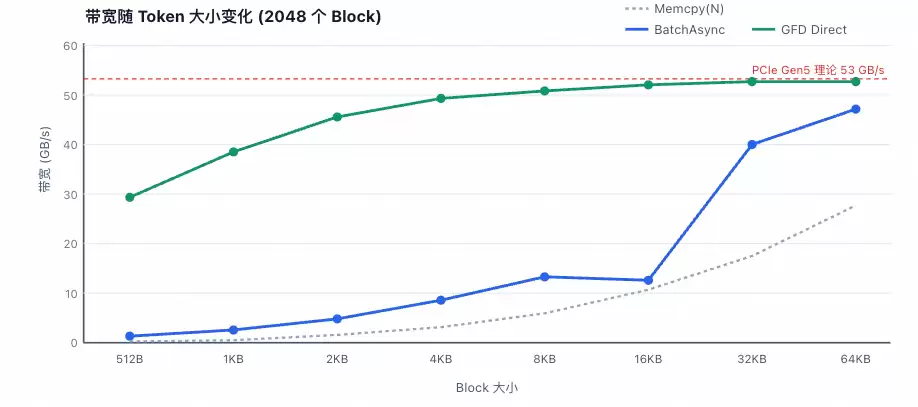
当拷贝的数据块数量较少时,cudaMemcpyBatchAsync凭借其减少API调用的优势,表现尚可。但随着拷贝块数(N)的增加,其性能迅速下降并趋于稳定。而GFD(Gather-For-Device)优化方案则能随着N的增加,持续利用更高的PCIe有效带宽,展现出优异的可扩展性。
产生这种差异的关键在于两者的实现路径截然不同:
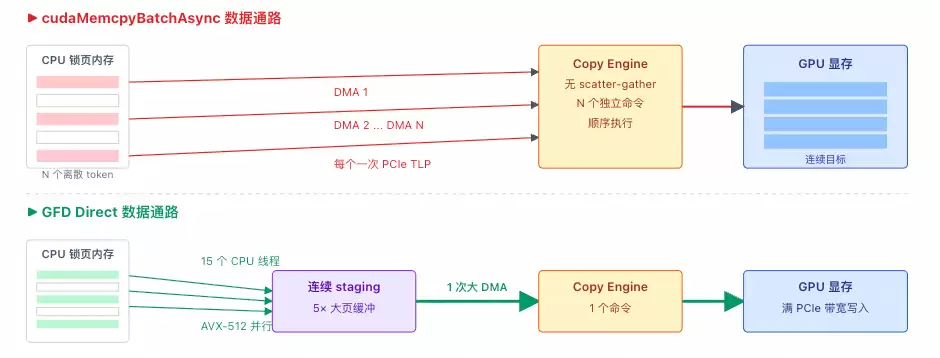
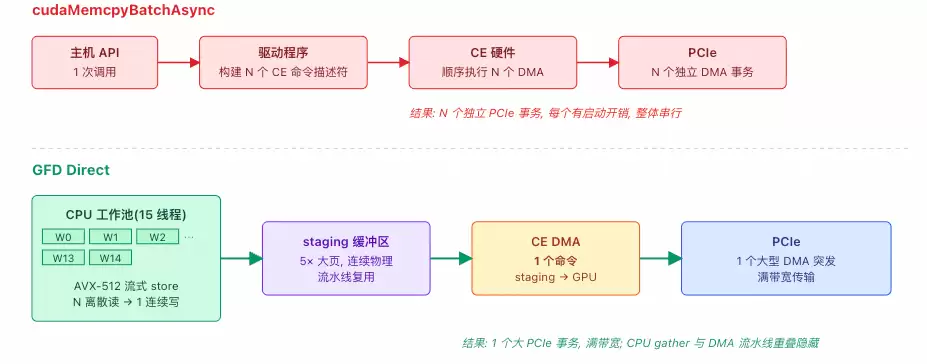
cudaMemcpyBatchAsync在底层本质上仍然是为每个离散的内存块生成独立的CE命令,由硬件顺序执行。而GFD方案则通过Gather线程先将分散在CPU各处的数据汇聚到连续的、由大页内存构成的暂存缓冲区中,然后由CE执行一次高效的、大批量DMA传输,从而巧妙地绕过了离散拷贝带来的性能瓶颈。
3. 多GPU并行扩展性测试
单GPU测试揭示了一些问题,而多GPU并行场景才是检验方案扩展性的“试金石”。我们设置每张GPU传输2048个大小为4KB的数据块(总计8MB,以2倍步长分散存储)。测试代码见examples/05_multi_gpu_benchmark.cu,运行./gfd_multi_gpu_benchmark。
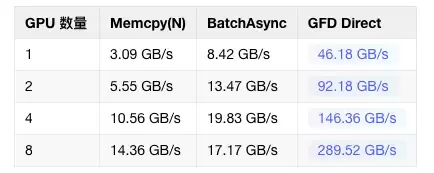
结果非常明显:cudaMemcpyBatchAsync在多卡场景下出现了严重的性能衰减,扩展性几乎为零。相反,GFD方案则保持了近乎线性的性能提升。
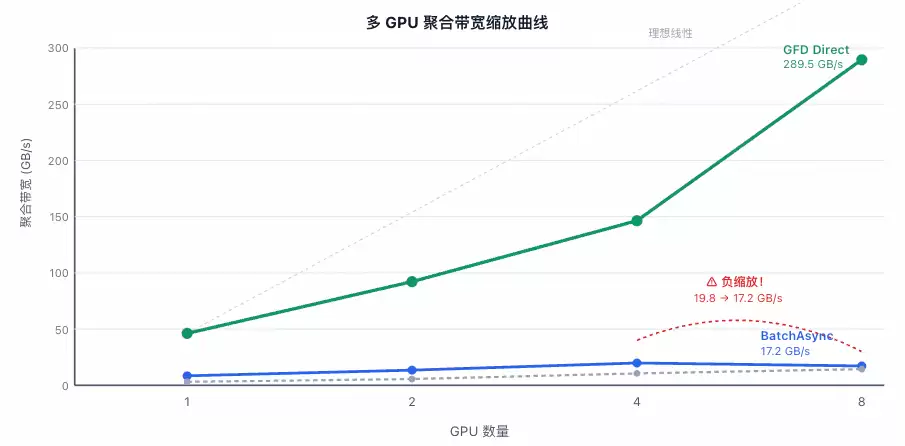
问题的根源在于驱动层面的锁竞争。当8个线程(对应8张GPU)同时调用cudaMemcpyBatchAsync时,它们需要竞争同一把全局驱动锁。每个线程大约需要持有锁717微秒来构建其2048个CE命令。平均而言,每张GPU需要等待大约3.5张其他GPU释放锁,导致总等待时间高达3.5 × 717 ≈ 2510微秒。这直接导致了整体吞吐量的坍塌。
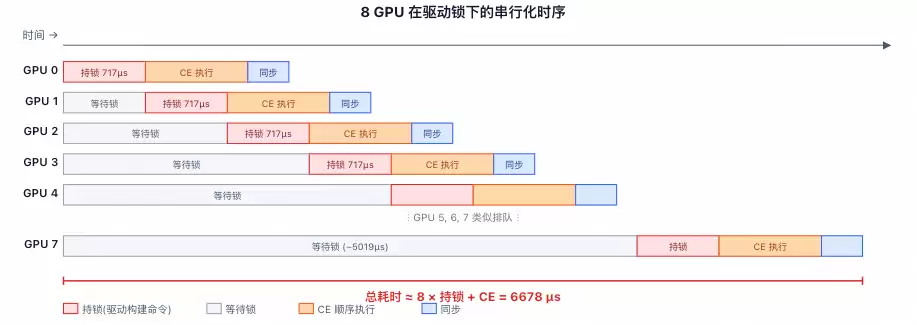
那么,GFD是如何实现近乎线性扩展的呢?其核心在于架构设计避免了中心化的锁竞争:
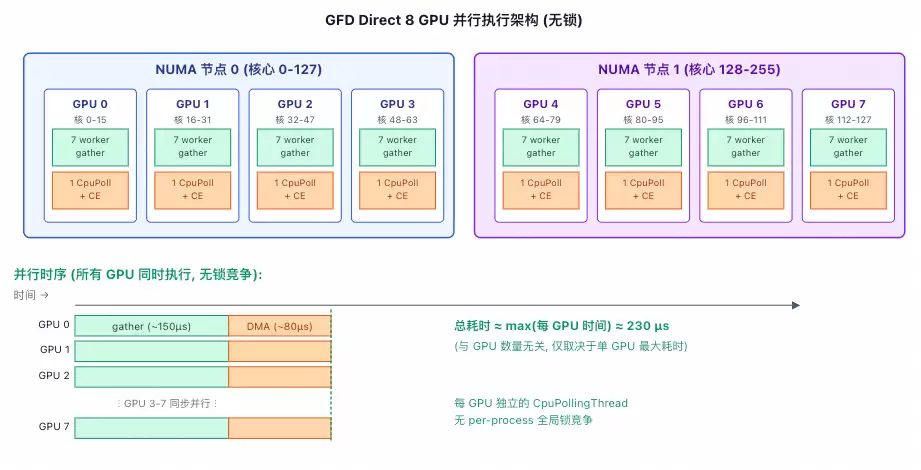

GFD为每个GPU实例分配了独立的Gather线程和专用的CE通道资源。每个实例在内部独立完成数据的收集与传输工作,实例之间不存在资源争用,从而完美实现了跨多GPU的并行扩展。
附录 A. cudaMemcpyBatchAsync 离散主机到设备批量拷贝示例
为了帮助开发者更好地理解和使用该API,这里提供一个完整的代码示例,演示如何使用cudaMemcpyBatchAsync进行离散的主机到设备内存批量拷贝:
#include
#include
#include
int main() {
const int NUM_TOKENS = 2048;
const size_t TOKEN_SIZE = 4096; // 每个Token大小为4KB
// 1. 在GPU上分配连续的目标缓冲区
char* gpu_buf;
cudaMalloc(&gpu_buf, NUM_TOKENS * TOKEN_SIZE);
// 2. 在CPU上分配锁页源缓冲区(模拟离散的KV-cache布局)
char* cpu_buf;
cudaMallocHost(&cpu_buf, NUM_TOKENS * TOKEN_SIZE * 2); // 2倍步长模拟离散存储
// 填充测试数据
for (int i = 0; i < NUM_TOKENS; i++) {
memset(cpu_buf + i * TOKEN_SIZE * 2, i & 0xFF, TOKEN_SIZE);
}
// 3. 构建批量拷贝所需的参数数组
std::vector dsts(NUM_TOKENS);
std::vector srcs(NUM_TOKENS);
std::vector sizes(NUM_TOKENS);
for (int i = 0; i < NUM_TOKENS; i++) {
dsts[i] = gpu_buf + i * TOKEN_SIZE; // GPU端连续排列
srcs[i] = cpu_buf + i * TOKEN_SIZE * 2; // CPU端离散排列(2倍步长)
sizes[i] = TOKEN_SIZE;
}
// 4. 配置内存拷贝属性
cudaMemcpyAttributes attr = {};
attr.srcAccessOrder = cudaMemcpySrcAccessOrderStream; // 源为锁页内存
attr.flags = 0;
// 所有拷贝条目共享同一种属性(索引为0)
std::vector attrIdxs(NUM_TOKENS, 0);
// 5. 创建CUDA流并执行批量异步拷贝
cudaStream_t stream;
cudaStreamCreate(&stream);
cudaMemcpyBatchAsync(
(void* const*)dsts.data(),
(const void* const*)srcs.data(),
sizes.data(),
NUM_TOKENS,
&attr,
attrIdxs.data(),
1, // numAttrs = 1,表示只有一种属性配置
stream
);
cudaStreamSynchronize(stream);
// 6. 验证拷贝结果
std::vector verify(TOKEN_SIZE);
cudaMemcpy(verify.data(), gpu_buf, TOKEN_SIZE, cudaMemcpyDeviceToHost);
printf("第一个Token的首字节: 0x%02x (期望值 0x00)\n", (unsigned char)verify[0]);
cudaMemcpy(verify.data(), gpu_buf + 100 * TOKEN_SIZE, TOKEN_SIZE, cudaMemcpyDeviceToHost);
printf("第100个Token的首字节: 0x%02x (期望值 0x64)\n", (unsigned char)verify[0]);
// 7. 释放资源
cudaStreamDestroy(stream);
cudaFree(gpu_buf);
cudaFreeHost(cpu_buf);
printf("批量拷贝完成: 共 %d 个Token, 每个 %zu 字节\n", NUM_TOKENS, TOKEN_SIZE);
return 0;
}