今天,AI领域再次迎来一枚重磅冲击波。DeepSeek正式发布了其V4系列模型的预览版,技术报告一经公布,便引发了行业内的广泛讨论。其核心看点在于,它似乎正在将一些曾经看似遥远的技术指标,转变为触手可及的现实。
一个拥有1.6万亿参数的庞大模型,却能高效处理长达百万token的上下文,同时将推理计算成本大幅削减至前代的27%左右。这些数字背后,究竟代表了怎样的技术突破与产业意义?
一、性能全景:开源领域的新“天花板”
评价一个大模型,最直观的方式莫过于看它的综合能力“成绩单”。
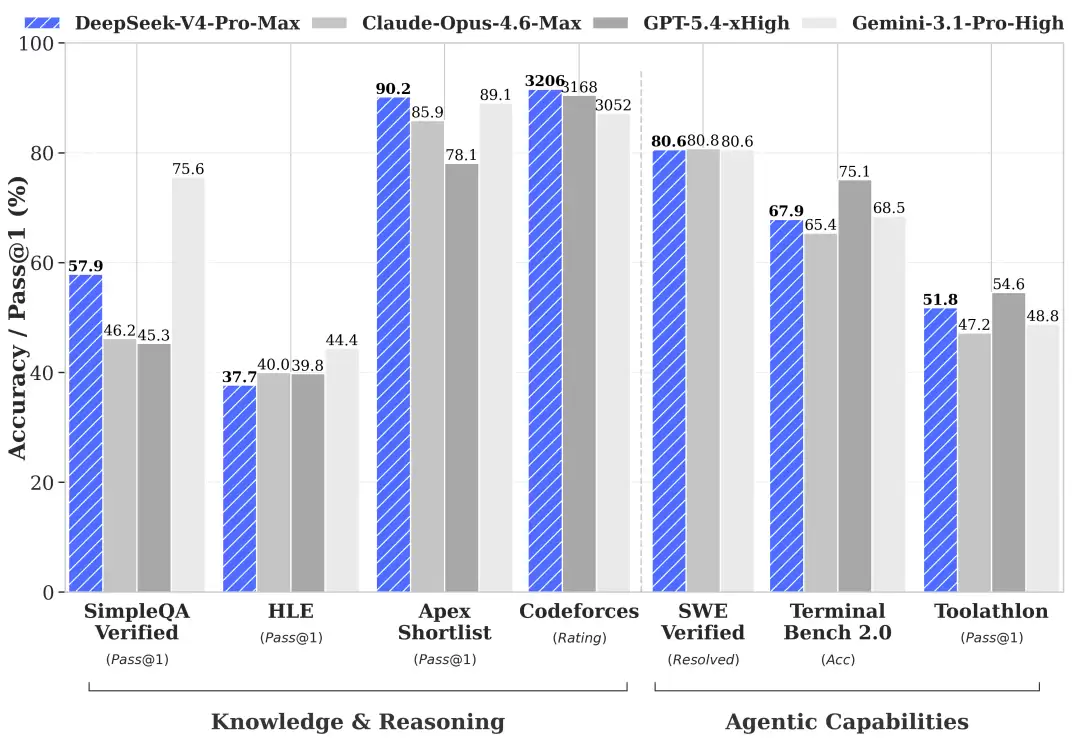
从多项基准测试来看,DeepSeek-V4-Pro-Max在知识、推理、编程、长文本理解等核心维度上,已经全面超越了此前的主流开源模型。尤其在编程竞赛Codeforces的模拟测试中,其表现甚至能排进人类选手的前23名,这标志着其逻辑与问题解决能力达到了新的高度。
与闭源巨头相比,情况同样值得关注。在知识类任务上,它与Gemini-3.1-Pro尚有细微差距,但推理能力已十分接近。更值得注意的是其“小杯”版本DeepSeek-V4-Flash,仅以284亿激活参数,就在推理效果上逼近了GPT-5.2,展现出极高的性价比。简而言之,这套组合拳打出了“开源最强,闭源可战”的态势。
二、核心突破:让百万上下文真正“可用”
“百万级上下文”这个概念并不新鲜,但过去的实现往往伴随着计算速度慢、成本高昂、显存占用巨大等现实问题,使其更多停留在演示阶段。
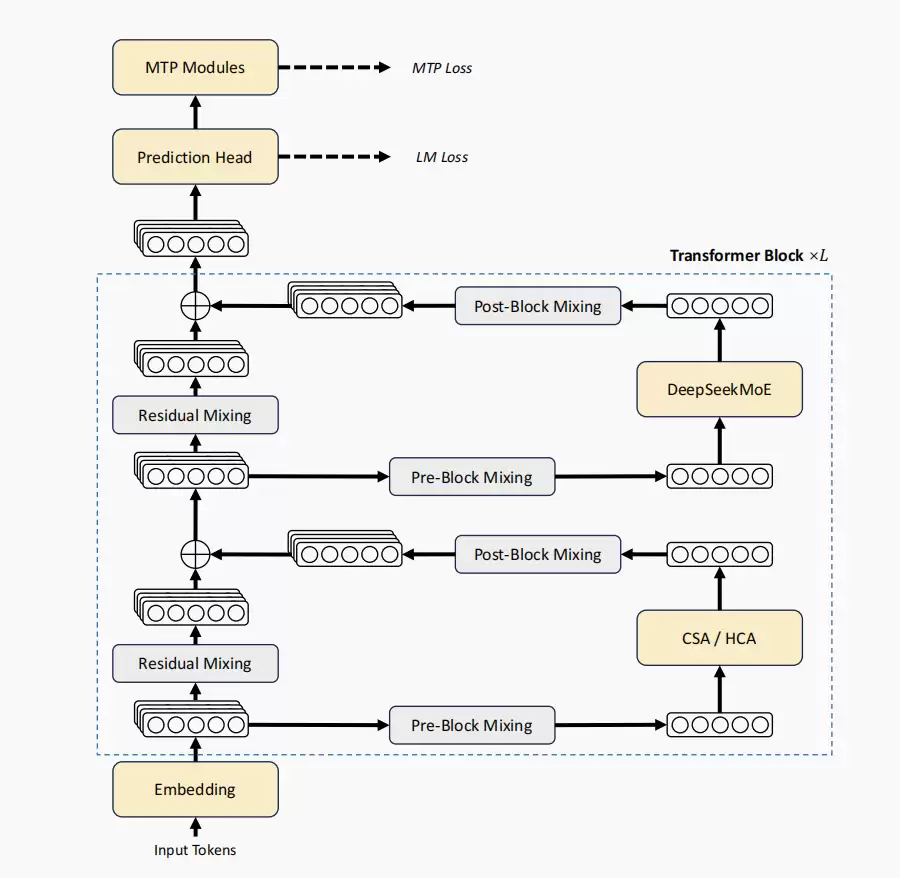
DeepSeek-V4的解法,核心在于一套创新的“混合注意力”架构,其思路可以概括为“高效压缩”。
混合注意力如何工作?
传统注意力机制在处理长序列时,计算复杂度会呈平方级增长,这是效率瓶颈的根本原因。V4的混合注意力通过两种策略应对:
- 压缩稀疏注意力(CSA):将每4个token打包成一个“压缩单元”,然后仅对筛选出的最重要512或1024个单元进行精细计算。这好比阅读一本巨著时,先通过目录锁定关键章节进行精读。
- 重度压缩注意力(HCA):进行更极致的压缩,每128个token视为一个整体进行处理,适用于超长文档的全局理解。
通过交替使用这两种注意力层,并辅以滑动窗口、注意力下沉等技术,最终实现了惊人的效率提升:在处理百万token时,V4-Pro的计算量仅为上一代V3.2的27%,KV缓存占用更是只有10%。
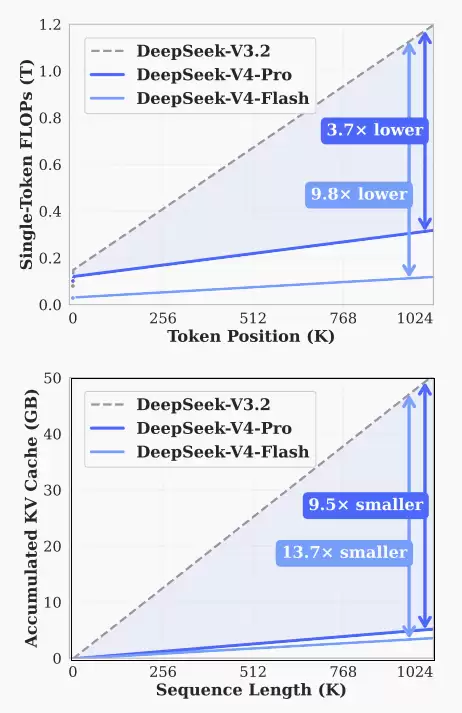
这意味着,长文本处理正从一项昂贵的“实验室能力”,转变为可用普通计算资源驱动的“实用工具”。
长文本能力实测
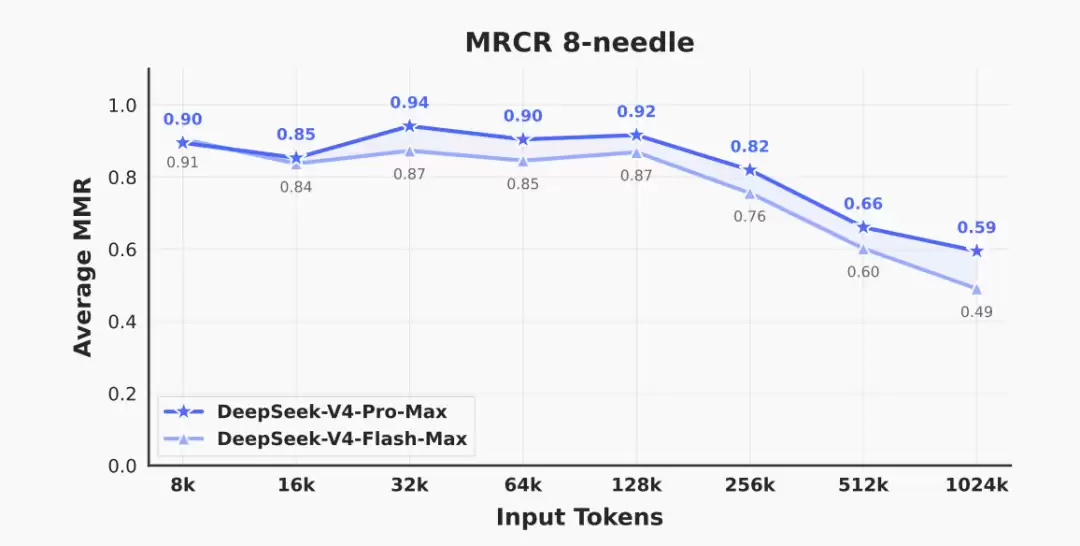
在经典的“大海捞针”测试中,模型在128K长度内几乎能做到完美检索;即便扩展到百万token,准确率虽有下降,但仍优于Gemini-3.1-Pro。在更贴近真实复杂问答的CorpusQA测试中,也展现了全面领先的优势。
三、架构精进:稳定与效率的基石
除了注意力机制,V4在模型基础架构上也进行了多项关键升级。
1. 流形约束超连接(mHC):稳定信号传输
模型采用了流形约束超连接来替代传统的残差连接。这相当于在深层网络的信息通道中加入了“稳压器”,有效缓解了训练中梯度爆炸或消失的问题,使得超大规模模型的训练过程更加稳定。
2. Muon优化器:加速训练收敛
训练中引入了Muon优化器处理大部分参数,其收敛速度表现优于传统的AdamW。同时,团队还自研了混合牛顿-舒尔茨迭代方法,提升了参数正交化的效率。
3. 训练稳定性技巧:化解梯度震荡
训练万亿参数模型时,突如其来的“损失尖峰”是常见挑战。DeepSeek团队发现MoE层的路由机制是诱因之一。为此,他们采用了“提前路由”策略,即利用上一步的旧参数预先计算路由,避免因路由剧烈变化导致的梯度震荡。再结合对SwiGLU激活函数线性部分的截断处理,几乎消除了训练中的损失尖峰现象。
四、推理加速:从算法到工程的极致优化
为了让模型在实际部署中更快、更省,工程层面的优化同样深入骨髓。
- FP4量化:对MoE专家权重和注意力模块中的QK路径采用了FP4格式进行存储和计算,实现了内存减半、速度翻倍的效果。关键是,这是通过量化感知训练实现的,精度损失微乎其微。
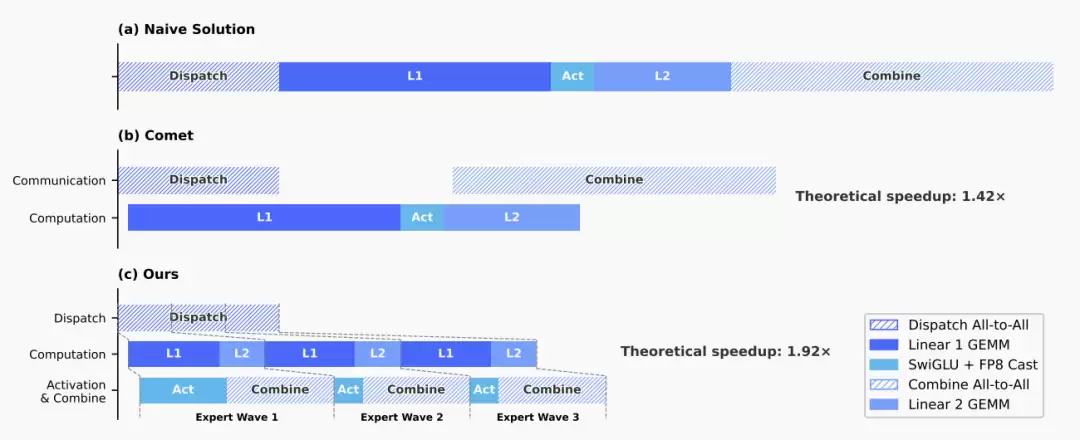
- 专家并行优化:通过精细的调度,将MoE层的通信与计算完全重叠,几乎隐藏了通信延迟。实测带来了1.5至1.73倍的推理加速。
- 自研领域专用语言(TileLang DSL):使用自研的DSL编写底层算子,在保持灵活性的同时极大提升了执行效率,将CPU侧的调度开销从几十微秒降低到1微秒以下。
五、数据与训练:构建能力的源泉
模型的预训练数据规模超过32T token,在质量和多样性上较前代均有提升。特别加强了对代码、数学、长文档和多语言数据的覆盖。此外,还引入了智能体数据,让模型初步具备了使用工具和调用API的能力。
在数据处理上,沿用了128K的大词表,并采用了样本级注意力掩码,以减少文本被不当截断的情况。
六、后训练策略:从“通才”到“专才”再到“全能”
预训练产出的是基础“通才”,要胜任具体任务,还需精细化的后训练。DeepSeek的策略分为两步:
1. 分领域培养“专才”
针对数学、编程、智能体、指令跟随等不同领域,分别进行监督微调和强化学习。其强化学习采用了GRPO方法,并创新性地使用“生成式奖励模型”,让模型自身参与评判,减少了对人工标注奖励模型的依赖。
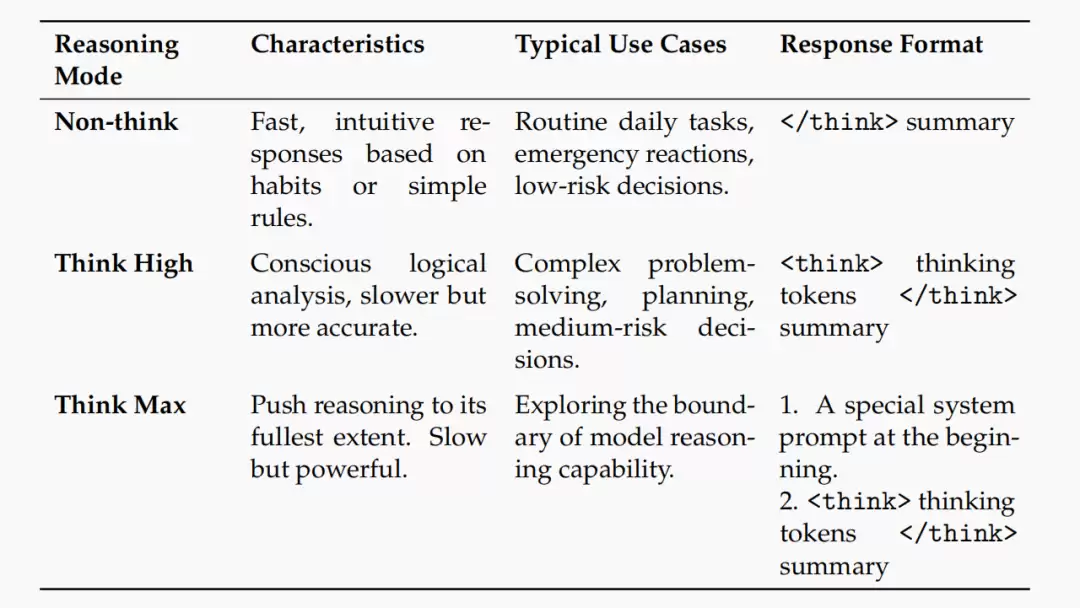
更有趣的是,模型被训练出三种“思考模式”:
- Non-think:快速直觉响应,适用于日常对话。
- Think High:进行中等长度的链式思考,处理复杂问题。
- Think Max:进行极限深度的推理,用于探索模型的能力边界。
2. “全能”模型合并术
如何将多个“专才”模型的能力融合到一个“全能”模型中?团队采用了“同策略蒸馏”方法。让目标模型(学生)自己生成问题,然后同时学习各个领域专家模型(老师)对该问题的输出概率分布。这使得最终模型能在一个问题上,灵活借鉴不同领域专家的长处。
七、场景化验证:不止于基准测试
技术指标最终要落到实际应用中才有价值。
中文写作
在与Gemini-3.1-Pro的对比中,DeepSeek-V4-Pro在功能性写作上取得了62.7%的胜率。用户反馈显示,V4在遵循指令方面更为严格,而Gemini有时会表现出过于强烈的自身风格。但在超高难度或多轮迭代的创意写作上,与Claude Opus 4.5相比仍有提升空间。
搜索与问答
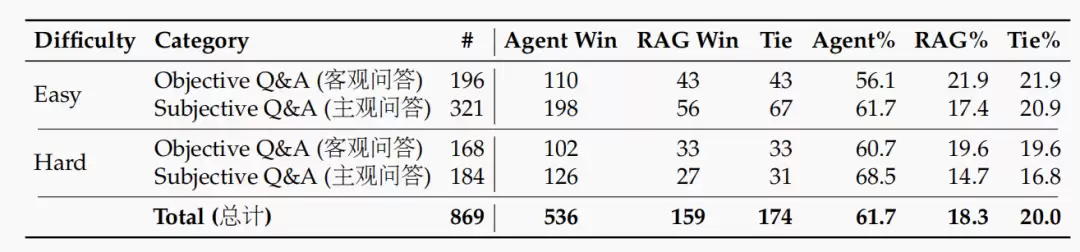
- RAG模式:相比V3.2,V4-Pro的胜率从10.4%大幅提升至28.1%。
- 智能体搜索:在处理复杂问题时,其通过自主规划调用工具的方式,比传统RAG更准确,而成本仅略有增加。
专业白领工作
在涵盖金融、教育、法律等领域的30个高级专业任务测试中,DeepSeek-V4-Pro-Max对比Claude Opus 4.6,取得了63%的非败率,尤其在任务完成度和内容深度上表现突出。但在格式美观度和总结精炼度上,尚有优化余地。
代码智能体
在内部的真实研发任务测试中,V4-Pro-Max的通过率达到77%,高于Claude Sonnet 4.5,并接近Opus 4.5等顶级模型。内部调研显示,高达91%的开发者愿意将其作为主力编程辅助模型。

八、总结与展望
总体来看,DeepSeek-V4系列通过创新的注意力压缩机制和极致的系统工程,将百万级长上下文处理从“技术可行”推向了“实用高效”。这标志着开源大模型首次在核心的推理与长文本能力上,如此逼近闭源模型的顶级水平。
当然,其架构为了追求稳定性和性能,集成了一些已被验证的技术模块,显得略微复杂,部分训练稳定性的原理也仍有待进一步阐释。但这并不妨碍它成为当前开源大模型领域一个强有力的新标杆。模型的权重已在社区开源,为后续的研究与应用提供了宝贵的基础。
技术的竞赛从未停歇,而每一次实质性的突破,都在为更广阔的应用场景打开新的大门。