多模态智能体(Agent)最容易让人产生一种错觉:它看过图片,所以它就记住了图片。
但在许多真实的系统实现中,图片往往并没有作为“视觉证据”被长期保存。一个常见的做法是,先将图片压缩成一段文字描述(Caption),然后将其存入向量数据库、摘要系统或长期记忆模块。当Agent后续需要回答问题时,真正被检索出来的并非原始图像,而是一段经过改写、压缩和筛选过的文字。
问题恰恰出在这里:用文字记住图片,不等于记住了图片本身。
一段文字描述可以概括一个房间、一张截图、一块色卡,或者指出某个角色出现在画面中。然而,它很容易丢失那些更关键的信息:局部的布局关系、相似物体之间的身份差异、精确的颜色值、细小的文字、纹理细节,以及视觉状态随时间变化后的最新版本。
为了探究这个问题,来自罗格斯大学、圣母大学、普林斯顿大学和AMD的研究团队联合提出了一个名为 《MemEye: A Visual-Centric Evaluation Framework for Multimodal Agent Memory》 的评估诊断框架。这项研究试图回答一个核心问题:多模态Agent的长期记忆,究竟是在记住“文字化后的摘要”,还是在保留并使用真正的视觉证据?


当前问题:视觉证据经常不是“必需品”
首先,我们需要正视一个容易被忽略的现实。
目前许多多模态记忆基准测试(benchmark)虽然包含了图片,也要求模型在长对话中回答问题,但这并不必然意味着模型必须依赖原始图片才能作答。
有些问题看似是视觉问题,但答案可能早已隐藏在对话文本中;有些图片仅需一句粗略的描述即可替代;还有些多轮记忆任务,考察的其实是“有没有记住文字事实”,而非“有没有保留视觉细节”。
举一个直观的例子:
如果问题是:“用户上次上传的是一张厨房照片还是卧室照片?”
那么,Caption只需写一句“这是一张厨房照片”就足够了。Agent完全不需要真正保留图像。
但如果问题变成:“后来出现在地板旁边的三个柜门样本中,哪一个和之前靠近铜色把手的样本是同一个?”
这就不是普通Caption能轻松解决的了。模型需要保留局部区域、相似物体、实例身份之间的细微差别。
更进一步,如果问题是:“最开始化石柜里的标签编号是A,但后来展柜被重新贴了标签。现在有效的编号是多少?”
这不仅需要看清图片,还需要判断哪个视觉状态是最新的、有效的,也就是要处理视觉记忆中的更新、冲突和覆盖逻辑。
这类问题在真实的Agent应用场景中其实非常普遍:家装设计方案会更改,导航路况会出现新变化,健康仪表盘的数值会更新,游戏状态会不断演变,社交聊天中间出现的人物或物品也可能在后续会话中再次出现。
所以,真正的挑战并非“模型能不能看图”,而是:它能否在漫长的交互历史中,保留足够精细的视觉证据,并在状态发生变化后,准确筛选出当前仍然有效的证据?
这正是MemEye研究工作的出发点。
核心动机:图转文不能代表真正的视觉记忆
为了节省计算和存储成本,许多系统会将图片转换成文字描述,再将描述存入记忆。这种做法被称为“Caption Hack”,既实用又常见。
但它存在一个天然缺陷:图像一旦被压缩成文字,大量信息就不可逆地丢失了。
例如:
- 微小的标签、文字、数字、颜色的深浅渐变;
- 两个相似人物或物体之间的身份差异;
- 画面中局部区域的位置关系;
- 某个物体后来被移动、替换或覆盖的视觉痕迹;
- 多张图片之间所呈现的状态更新链条。
这些信息在Caption中极易被省略,因为Caption生成通常优先描述“看起来重要”的整体语义,而非保留所有未来潜在问题可能需要的细节。
这就引出了一个基准测试设计上的关键问题:如果一个基准测试中的问题,仅靠Caption或对话文本就能回答,那么它就很难证明系统真正具备了视觉记忆能力。
因此,MemEye的目标并非简单地增加更多图片,也不是只看最终准确率,而是建立一个更精细的诊断框架,用以区分不同的失败原因:
- 是不是视觉证据在压缩过程中被丢弃了?
- 是不是找到了相关图片,但找错了时间点?
- 是不是证据都在,但模型不会整合更新后的状态?
- 是不是当前的多模态记忆架构只解决了其中一部分问题?
MemEye:两个轴拆解“视觉”与“记忆”
MemEye最核心的设计,是一个二维评估框架。
这个框架将多模态长期记忆拆解为两个相互独立但又紧密交织的维度:
- X轴:视觉证据粒度
- Y轴:记忆推理深度
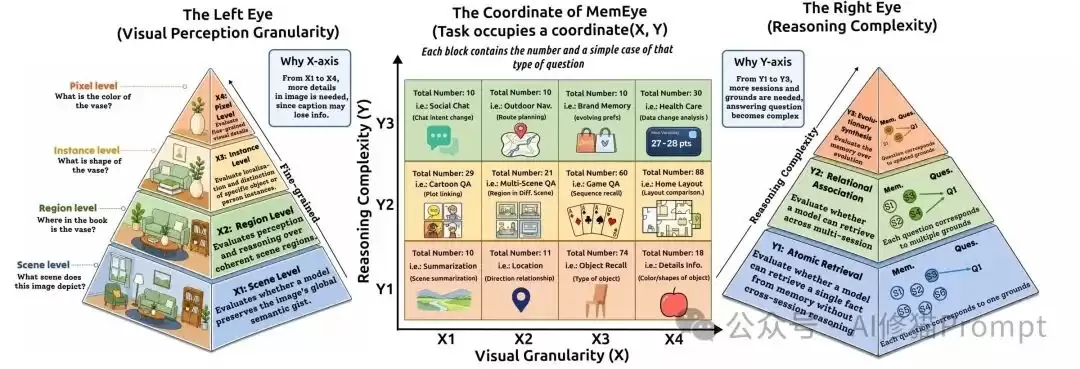
X轴:模型到底需要记住多细的视觉证据?
X轴衡量的是:回答问题所需的决定性视觉证据有多精细。
X1:场景级证据
这是最粗粒度的视觉证据,例如场景类型、整体活动、全局语义。
例子:画面是在厨房、街道、漫画场景,还是健康仪表盘?
这类信息通常比较容易被Caption保存下来。
X2:区域级证据
模型需要理解局部区域,而非只看全局。
例子:房间某个角落的柜子、地板上的样本、路口某个区域的障碍物。
此时,问题开始依赖于局部布局和区域关系。
X3:实例级证据
模型需要在多个相似对象或人物中区分“具体是哪一个”。
例子:三个相似的柜门样本中,哪一个和之前出现的是同一个?漫画里两个长相相似的角色,谁在后面再次出现?
这类问题很容易被Caption“拍扁”。一句“有三个样本”并不能保留每个样本的独特身份。
X4:像素级证据
这是最精细的视觉证据,包括小字、数字、颜色、纹理、精确数量、类似OCR的信息。
例子:仪表盘上的数值、展柜标签编号、衣服上的小图案、品牌Logo的细小差别。
这类信息最容易在文本摘要中丢失,也最能暴露基于Caption的记忆系统的局限性。
Y轴:模型要怎样使用这些记忆?
Y轴衡量的是:在找到视觉证据之后,模型需要进行多复杂的记忆推理。
Y1:原子检索
仅凭一个证据点就足以回答问题。
例子:只要找到某一轮的图片,就能回答当时的背景是什么。
这主要测试记忆的访问能力,即能否取回所需信息。
Y2:关系关联
模型需要将多个非冲突的线索串联起来。
例子:跨会话比较两个事件的先后顺序,或者将一个人物在前后不同画面中的出现联系起来。
这里的信息是累积的,不存在后续信息推翻前序信息的情况。
Y3:演化综合
这是最难的一层。模型需要处理更新、冲突、覆盖和状态变化。
例子:一个物体最初放在A位置,后来被移到B位置;一个标签最初是旧编号,后来被换成新编号;一条路线一开始可行,后来因为障碍物变得不可行。
此时,模型不能仅仅找到“相关证据”,还必须判断:哪一个证据是当前有效的视觉状态?
这正是许多基于检索的记忆系统容易失败的地方。它们可能找到了语义相关的旧图片,却没有意识到旧证据已经被后续的视觉信息所覆盖。
MemEye数据集:让图片变得不可替代
基于这个二维框架,研究者构建了一个以视觉为中心的长期记忆基准测试。
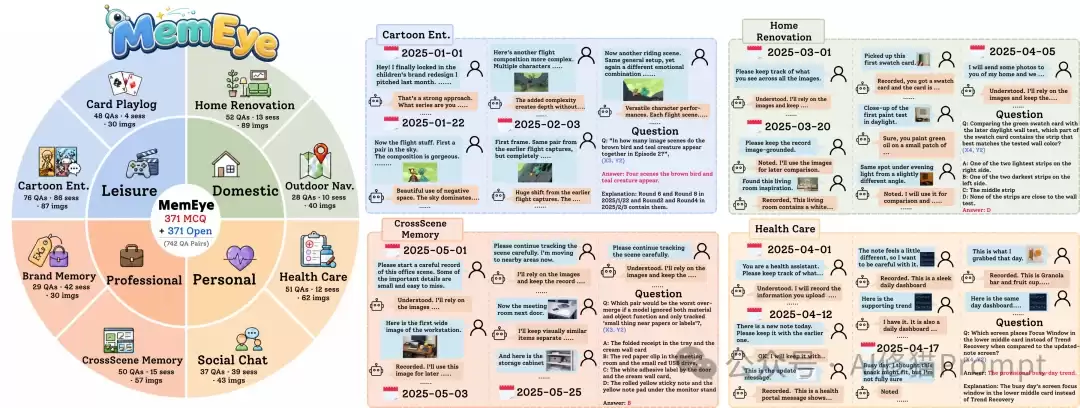
MemEye包含:
- 371个问题
- 221个会话
- 848轮对话
- 438张图片
- 8个生活场景任务
- 每个问题都有选择题和开放回答题两种镜像形式
这8个任务覆盖了四类真实生活场景:
- 休闲娱乐
- 牌局记录:追踪牌局状态、回合变化与历史记录
- 漫画娱乐:记忆漫画角色、情节线索与叙事关系
- 日常生活
- 家装改造:追踪家装状态、设计选择与后续更新
- 户外导航:记忆路线、地标位置与空间关系
- 专业场景
- 品牌记忆:记住Logo、品牌视觉元素与视觉身份变化
- 跨场景记忆:追踪不同场景中的物体状态与更新关系
- 个人场景
- 健康护理:记忆仪表盘、健康数据与状态更新
- 社交聊天:记住聊天过程中间出现的视觉细节与上下文线索
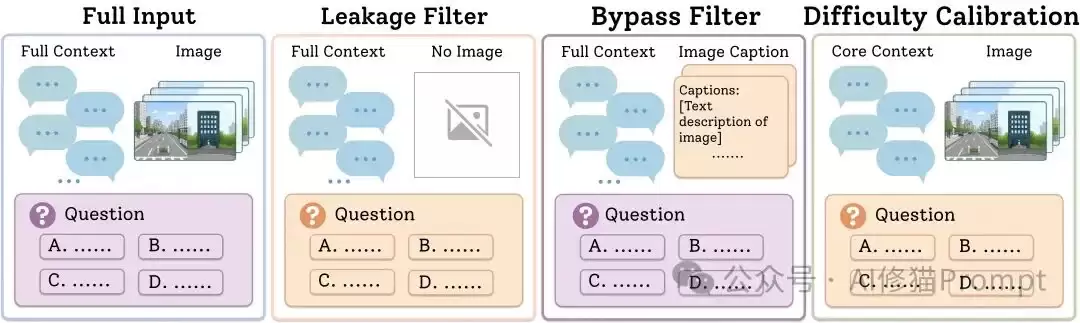
更重要的是,MemEye在构建时进行了多层过滤,尽量避免出现“看起来是视觉问题,实际靠文字就能答”的情况。
具体来说,研究者设置了几类验证关卡:
1. 去除对话泄漏
如果只给问题、选项和文字线索,不给图片,模型也能稳定答对,那么这个问题就会被移除或修改。因为这种题目并不能证明模型需要视觉记忆。
2. 去除Caption可绕过
如果把图片替换成极简的Caption(如“这是一张房间照片”),模型仍然能答对,则说明问题对原始图像的依赖度不够,同样会被移除或修改。
3. 控制问题本身可回答性
如果给模型正确的线索轮次和原始图片,它仍然答不出来,那么可能是问题本身表述不清,或者视觉证据不足。这类问题也需要修正。
4. 四轮选项旋转
对于选择题,正确答案会轮流出现在A/B/C/D选项位置,以减少模型因选项位置偏好而“蒙对”的情况。
这也正是MemEye想强调的一点:基准测试不只是堆砌数据,更重要的是让数据真正测试到目标能力。
实验设置:13种记忆方法 × 4个视觉语言模型
MemEye评估了13种记忆方法,覆盖了纯文本记忆和多模态记忆两大类。
基于文本的记忆:把图片转成Caption
这类方法将每张图片替换为密集描述(dense caption),然后系统仅在文字流上进行记忆、检索或推理。
代表方法包括:
- Full Context Text
- Semantic RAG Text
- Reflexion
- Generative Agents
- MemoryOS
- A-Mem
- SimpleMem Text
它们的优势在于:文字更容易组织、压缩和检索,也更适合记录更新和状态变化。
但其风险也很明显:如果Caption没有捕捉到关键的视觉细节,这个信息后续就无法找回。
多模态记忆:保留原始图像输入
这类方法直接保留或检索原始视觉输入。
代表方法包括:
- Full Context Multimodal
- Semantic RAG Multimodal
- MIRIX
- MMA
- M2A
- SimpleMem Multimodal
它们的优势在于:细粒度的视觉证据得以保留。
但保留图片本身并不等于会使用。系统仍然需要在很长的历史中,找到正确的图片,并判断哪个状态是最新的、哪个证据已经过期。
评估模型
论文中评估了4个视觉语言模型骨干:
- Qwen3-VL-8B-Instruct
- GPT-4.1-nano
- GPT-5.4-mini
- Gemini-2.5-flash-lite
选择题使用精确匹配(EM)评估,并对四种答案位置旋转取平均;开放回答题使用LLM-as-a-Judge作为主指标,并用BLEU-1等作为辅助指标。
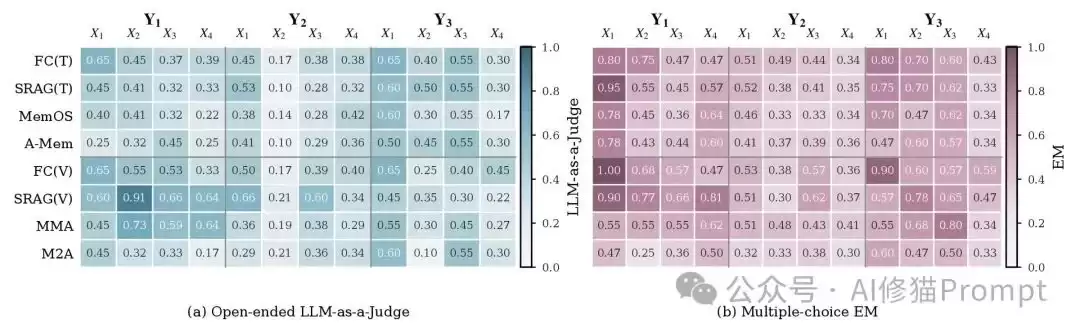
主要结果
实验结果最核心的结论可以概括为一句话:当前的多模态记忆系统并非“完全不会记”,而是在不同的环节会“断链”:有时丢失视觉细节,有时找错时间点,有时无法合成当前有效状态。
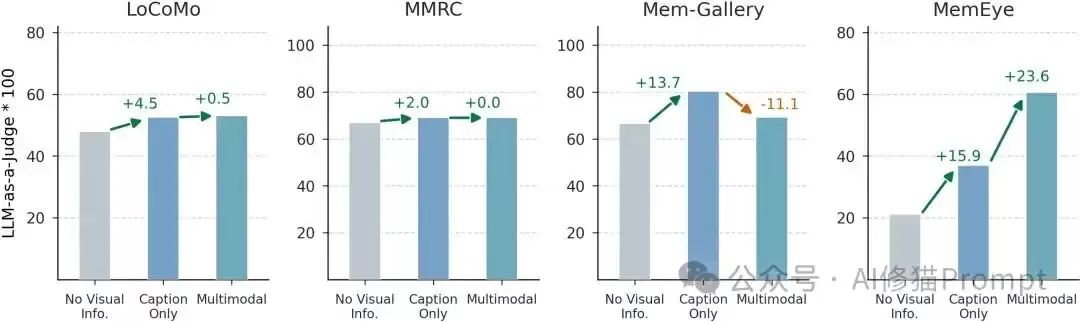
结果一:Caption在粗粒度问题上尚可,但在细粒度视觉证据上掉队明显
在X1/X2这类场景级、区域级问题上,基于Caption的记忆方法往往仍有竞争力。这并不意外,因为“整体场景是什么”、“某个区域大概有什么”通常可以被文字描述覆盖。
但到了X3/X4,即实例级和像素级问题,Caption的瓶颈便开始暴露无遗。原因很直接:Caption很难完整保留未来可能会被问到的所有视觉细节。
例如:
- 三个相似样本的具体身份;
- 小标签上的编号;
- 某个UI截图里的精确数值;
- 一个角色在不同画面中的细微外观差异。
这些信息不一定会出现在Caption中。即使Caption是由强大的模型生成的,它也不可能预知未来所有问题需要哪些细节。
这正是MemEye中Caption-Proof诊断想要测试的点:如果把图像换成Caption,性能会下降多少?下降得越多,说明该任务越依赖真正的视觉证据。
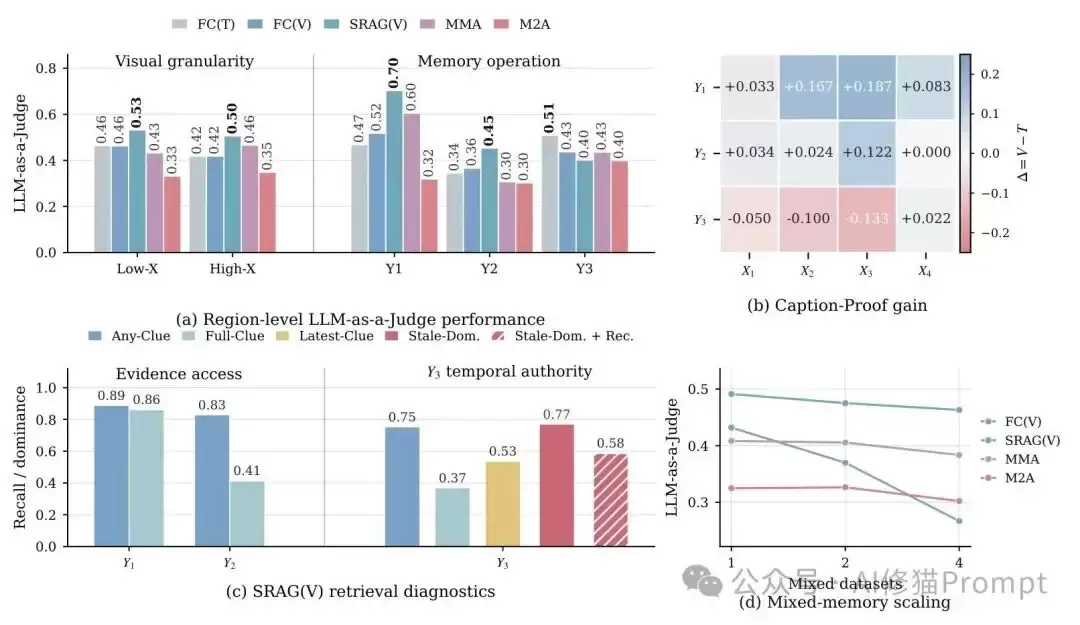
结果二:保留原始图像有帮助,但仍无法自动解决“状态更新”问题
很多人可能会想:既然Caption会丢失细节,那只要保留原图不就行了吗?
MemEye的结果表明:这还不够。
原图确实能帮助模型处理需要高视觉粒度(X轴)的问题,但在Y3演化综合任务中,关键瓶颈往往不是“图像是否可读”,而是“系统是否知道哪张图在当前有效”。
例如,一个场景中先出现了旧标签,后来又出现了新标签。检索系统可能把语义高度相关的旧标签也找出来,但它已经不是当前的有效状态。
这就是论文中反复强调的区别:找到相关证据 ≠ 找到有效证据。
像Semantic RAG这类方法很容易找出“语义相关”的图像,但如果它没有足够强的时间意识、状态更新机制或时效性感知选择,就可能将过期的证据排在前面。
结果三:文本记忆与图像记忆各有优势,但单独使用都不够
MemEye揭示了一个重要的权衡关系:
- 基于文本的记忆更擅长压缩、组织和记录状态变化,但容易丢失细粒度视觉证据;
- 基于图像的记忆更能保留原始视觉细节,但在长历史中容易被相似、过期、冲突的图像干扰;
- 基于检索的记忆能减少全历史输入的噪声,但如果只看语义相似度,容易选到过期证据;
- 全上下文记忆能看到更多历史,但随着历史变长、话题变多,也更容易被无关信息干扰。
因此,未来更稳健的多模态记忆可能不是单一模块,而是需要同时具备三种能力:
- 保留视觉证据:不要过早将图像压缩成不可恢复的文字;
- 记录结构化状态:明确什么被更新、什么被覆盖、什么仍然有效;
- 选择时间有效证据:不仅要找相关内容,还要判断哪个证据在当前时间点仍然成立。
为什么MemEye重要
许多基准测试最终只给出一个总分,告诉我们哪个模型更强。
但在记忆系统中,总分往往不够。因为两个系统可能总分接近,但失败原因完全不同:
- 一个系统可能能找到图片,但看不清细节;
- 一个系统可能看得清,但检索不到正确图片;
- 一个系统可能检索到相关图片,但选了旧状态;
- 一个系统可能所有证据都在,却无法整合更新链条。
MemEye的价值就在于,它把失败的位置拆解开了。
它让工程师可以提出更具体的问题:
- 失败发生在X轴吗?也就是视觉证据粒度不够?
- 失败发生在Y轴吗?也就是记忆推理深度不够?
- 是Caption压缩的问题?
- 是检索机制的问题?
- 是时效性判断的问题?
- 是视觉保存和状态更新之间的架构权衡问题?
这对于从事Agent记忆、多模态RAG、长上下文VLM、个人助理、医疗/健康仪表盘助理、GUI智能体的研究者而言至关重要。
因为真实世界中的Agent不会只回答“图片里有什么”。它们需要在长期交互中,持续更新一个关于世界的内部状态:用户喜欢什么、家里现在变成什么样、路线是否仍然可行、之前看到的异常是否还存在、哪个版本的信息已经过期。
如果记忆系统不能区分“旧的相关信息”和“当前有效信息”,它就会在真实应用中犯下危险的错误。
给系统设计的启发:多模态记忆不能只靠Caption,也不能只靠向量检索
读完MemEye的研究,最值得关注的并非某个方法得了多少分,而是其带来的三个设计启发。
启发一:不要过早丢弃原始视觉证据
Caption是有用的,但它不应该是唯一的记忆形式。
对于高风险或需要细粒度处理的任务,系统最好能保留原始图片、局部裁剪、视觉嵌入向量、OCR结果、结构化属性等多种形式,而不是仅仅存储一句描述。
启发二:记忆系统需要显式处理“状态更新”
长期记忆不是静态的资料库。
一个用户偏好可能改变,一个物体位置可能移动,一个健康指标可能更新,一张旧截图可能被新截图覆盖。
因此,记忆系统需要知道:
- 哪些证据是旧的;
- 哪些证据是新的;
- 哪些证据之间存在冲突;
- 哪个状态被后续信息覆盖;
- 回答当前问题时应该使用哪个版本。
这比普通的语义检索要困难得多。
启发三:未来系统可能需要图像记忆 + 文本记忆 + 结构化记忆的组合
一个更理想的架构可能是:
- 用图像记忆保留视觉细节;
- 用文本记忆保存可压缩的语义摘要;
- 用结构化记忆记录状态变化、时间戳、冲突和覆盖关系;
- 用时效性感知或状态感知的检索机制来选择当前有效证据;
- 最后再让视觉语言模型基于这些证据回答问题。
也就是说,多模态长期记忆不应该只是“把历史都塞进提示词”,也不应该只是“向量检索最相似的几条记录”。
它更像是一个能够维护状态、判断版本、保留原始证据的动态记忆系统。
不能只“看过”,而要记得对、找得到、用得上
MemEye指出的核心问题简单而关键:对于多模态Agent而言,长期记忆不只是存储更多历史,而是要保存正确粒度的视觉证据,并在时间变化中选出当前有效的状态。
如果一个系统只会把图片转成Caption,它可能在粗粒度任务上表现不错,但在细节问题上丢失关键证据。
如果一个系统只会保留原始图片,它可能看得更清楚,但仍然可能在长历史中找错图、选择旧证据、混淆当前状态。
如果一个系统只看总分,工程师很难知道它到底在哪里失败。
MemEye的意义,在于提供了一份更细致的“视觉记忆体检表”:它不仅问Agent答得对不对,还追问它为什么答错,错在视觉细节、检索路径,还是状态更新。
随着AI Agent越来越多地进入真实生活场景,多模态长期记忆将变得越来越重要。未来的Agent不应该只是“临时看图”的聊天机器人,而应该能在长期交互中,可靠地记住、更新、调用视觉世界中的证据。
这也是MemEye希望推动的方向:让业界更清楚地认识到,当前系统距离真正可靠的多模态记忆还有多远,以及下一步应该朝哪里改进。