毕业季来临,许多同学都在询问同一个问题:如何有效降低论文的AI生成检测率?
不少毕业生正面临学校对毕业设计的严格审查,知网、维普等查重系统普遍要求将AI疑似比例控制在30%以下。有朋友因AI率过高被退回修改两次,十分焦急,希望找到可靠的方法应对。
面对这一需求,我们首先需要思考:这类AI检测机制是否可靠?是否存在简便方法能够规避检测?
回顾两年前,我曾用知乎数据训练过一个口语化模型,但它在学术场景中完全不适用。学术文本改写有其特殊性:过于口语化的表达容易被导师识破;改动幅度不足则仍会被检测系统标记。
深入分析后发现,真正的挑战在于,主流平台的AI检测模型都是“黑盒”:其训练数据、特征工程、阈值策略均不公开,更未提供稳定的API接口。若想使用PPO或GRPO等强化学习方法直接对抗某个检测器,连设计奖励函数都无从下手,因为你无法获取检测模型本身。
因此,我们转换了思路:能否利用五一假期,训练一个模型,在保持学术规范的前提下,显著降低文本的AI疑似率?
最终,我们成功实现了这一目标。
下文将记录实验过程中的关键试错与最终可行的方案。模型与合成数据均已开源,链接见文末。
不进行模型训练是否可行?
在着手训练前,我们尝试了两条更便捷的路径。
第一条是寻找现成的Prompt或改写工具。在GitHub上搜索发现,英文领域有可用仓库(如github.com/blader/humanizer),但中文领域几乎空白。有一个中文改写项目采用了传统NLP方法检测AI率(github.com/voidborne-d/humanize-chinese),但其改写依赖规则替换,检测手段较为粗糙,参考价值有限。
第二条思路是使用冷门模型生成文本。其逻辑在于:检测模型本质上是判断文本的统计分布是否接近主流大模型的输出分布。如果使用一个极其冷门的模型,其输出分布天生远离被检测的主流模型,是否就能自然规避检测?
想法虽好,但很快被否定:过于冷门的模型对中文支持通常较差,生成质量难以保证。而且,若未进行针对性微调,其底层语言分布与主流模型的差异可能并不显著。
两条路径均行不通,我们决定从头开始训练一个专用模型。
训练数据与流程详解
第一步:监督微调(SFT)——获得初步可用但欠佳的版本
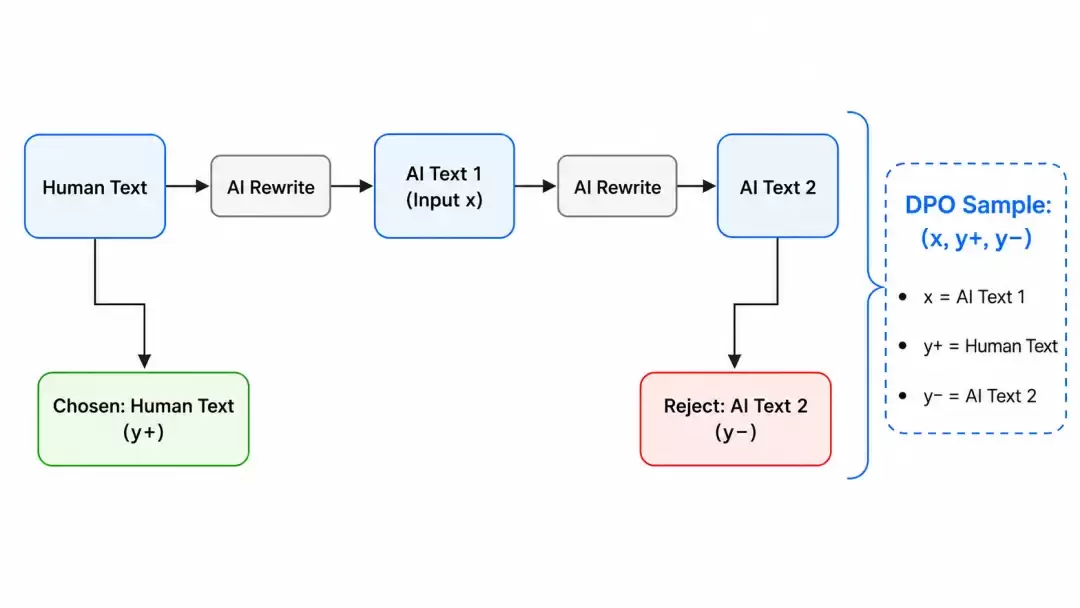
在数据构建上,我们采用了逆向构造的思路:收集一批人类撰写的文本,用AI将其改写成“AI风格”显著的版本,然后训练模型学习逆向操作——将AI味重的文本还原为人类风格。
关键在于原始文本的选择。
前期尝试使用互联网网页数据,遇到了两个难题。一是数据清洗极其繁琐,需要处理大量XML标签、网页跳转链接等噪声。另一个更严重的问题是:训练出的模型过于口语化,完全无法应用于学术场景。
因此,必须将数据范围限定在学术类文本。
最初考虑使用Wikipedia,但维基数据在预训练语料中占比通常很高,效果可能不理想。直接下载arxiv论文进行切分?那主要是理工科英文论文,缺乏人文社科及中文内容,模型泛化能力将受限。
最终,我们找到了一个合适的数据集:CSL(github.com/ydli-ai/CSL),它收录了大量中文论文摘要。虽然仅是摘要,但其语言分布与论文正文段落的差异相对较小。
我们构建了约18000条训练样本,格式统一为“指令 + 输入 + 输出”。指令是“将文本改写得更像自然人写作,保持原意与事实”,输入是AI改写后的摘要,输出是原始的人类撰写的论文摘要。
基座模型选择了Qwen3.5-9B,收敛效果良好,Loss曲线平滑,并实施了早停策略。
来看一个改写案例。原文类似:
今天没什么特别的,和平常一样。早上起床玩了会手机,中午随便吃了点东西,下午出去买了杯咖啡。桂花开了,闻着挺香的。在公园坐了十来分钟,看了一会儿狗和小孩。然后就回家了。这一天就这么过去了,不坏也不好,就是普通的一天。
模型处理后变为:
今日平平淡淡,与往日无异。晨起时翻阅了些许手机资讯,午间随意进食,午后外出购得一杯咖啡。恰逢桂子飘香,漫步公园约莫十分钟,观览孩童嬉戏与犬只闲逛,随后便归家。一日就此落幕,并无甚波澜,既非佳日亦非恶日,不过寻常时日罢了。
这个SFT版本确实能完成改写任务,并保留了学术术语。但其问题在于,对学术场景的改写过于保守——毕竟学术文本改写前后的差异本就微小,且学术语言天然严肃。同时,它对日常场景的改写又显得过于文雅。
这导致两个直接问题:改写程度不足,检测系统依然可能识别;模型通用性差,仅适用于学术场景。
第二步:DPO第一阶段——一个关键错误与修正
SFT之后,自然想到使用DPO来提升效果。为何不用PPO?原因如前所述:各家检测模型不一,且无法获取API。与其破解某个具体检测器,不如找到一种让文本更接近人类语言分布的通用方法,这样更可能具备跨检测器的泛化能力。
但在DPO的首次实验中,我们犯了一个错误。
当时沿用了SFT的数据构造思路:chosen样本是人类原文,rejected样本是AI改写版。听起来合理,对吗?但实际运行问题很大。因为AI改写后的文本通常更书面、更严谨,而人类原文相比之下反而更口语化。结果模型学到的信号变成了“越口语化越好”,而非“越接近人类分布越好”。这个版本完全不可用。
意识到问题后,我们立即调整了数据构造方式,改为双向构造:
一边是2000条formal-rejected数据,AI改写保持正式书面语气不变;另一边是2000条casual-rejected数据,AI改写时加入各种口语化变体,如调整长度、增减信息。
这种构造方式让模型真正领悟了“人类文本”的感觉。
此次处理后的效果如下:
今天平平淡淡,和往常一样。早晨醒来玩了一会儿手机,中午胡乱塞了几口食物,下午出门买杯咖啡。桂花开了,闻起来很香。在公园里坐十几分钟,看了看狗和小孩。然后便回家。这一天就这样过去了,不糟糕也不出色,就是平凡的一天。
它不再简单认为口语化就是好的,也不再认为书面化就是坏的,而是学会了一种更接近真人写作的自然风格。
第三步:DPO第二阶段:自博弈与信号纯度的教训
有了更稳固的DPO版本,我们尝试通过自博弈进一步提升效果。
这里又犯了一个错误:将自博弈数据与一部分口语化rejected数据混合训练。本意是为模型设置“围栏”,防止其偏离方向。但自博弈产生的学习信号较弱,而口语化rejected数据的区分信号过强。模型很快就能分辨哪些是口语化数据,如果一个batch中采样到较多口语化数据,梯度就会暴涨,导致整个训练过程剧烈波动。
于是,我们果断放弃了该版本。
随后重新开始:去除所有口语化数据,确保学习信号的单一性。没有了“围栏”,我们将学习率调整为之前的一半,以更慢的速度防止模型跑偏,同时将自博弈数据扩展至2000条,重新训练。
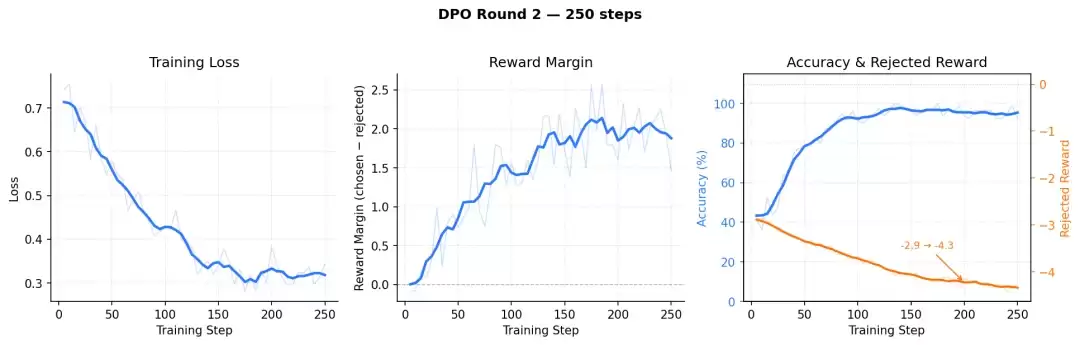
这个版本训练完成后,终于接近可用状态。
此次处理后的文本效果如下:
一切如常,今天没有什么特别之处。起床后玩了一会儿手机,中午胡乱吃了一些东西,下午去外面买咖啡喝。桂花开了,闻着很香。在公园里坐了一刻钟左右,看了会儿狗和小孩子。随后就回家。就这样,一天过去了,不好也不差,就是普通的一天。
我们使用两篇论文进行了批量改写测试:第一篇的AI率从50%降至24%,第二篇从30%降至8.9%。同时,人工抽查了数十个段落,语义和事实信息均基本保留无误。

当然,该模型远非完美,但作为可行性验证,其效果已相当可观。我们相信,扩展数据量和数据类型后,效果还能进一步提升。
延伸思考与总结
整个实验在一个五一假期内完成。使用单张RTX 5090显卡,思路理清后,实现本身已非难点。
随后,我们将模型与合成数据一并开源:https://github.com/XiangJinyu/humanize-zh
模型训练完成后,对比不同版本的改写案例,发现一个有趣现象:
SFT版本在学术场景尚可,但若输入一段日常文字,它会将随意一段话改得颇具文言文色彩。例如“今天没什么特别的,和平常一样,早上起床玩了会手机”,它会改为“今日平平淡淡,与往日无异,晨起时翻阅了些许手机资讯”。
而DPO Stage-2版本,即使训练数据全部来自学术论文,在日常场景中也展现出良好的可用性。同一段话它会改为“一切如常,今天没有什么特别之处。起床后玩了一会儿手机”,非常自然流畅。
这说明DPO阶段所学的内容,确实更接近底层的“人类分布对齐”,而不仅仅是学术文本的表面特征。通过在学术论文上的训练,模型竟泛化出了一部分通用的文本改写能力。这一发现表明,整条技术路径值得持续投入探索。
在项目推进过程中,我们产生了一些感触:当前的检测系统究竟拦住了谁?或许是那些不愿深入钻研的人。真正有意规避者,花费一个假期便能构建出可用的方案。随着此类工具日益增多,反检测的产业链只会愈发成熟。
或许,更值得深思的是:教育系统究竟在检测什么?步入职场后,从未有人询问你文档的AI率是多少。大家只关注你能否解决问题、交付成果。
在AI工具无处不在的时代,与其将精力集中于检测学生是否使用AI,不如思考如何教导学生有效利用AI。AI时代已然来临,如何让学生在AI的辅助下获得更佳学习效果,如何设计一套全新的评估体系来衡量真实的学习成效,这或许是高校真正值得投入时间与精力去探索的课题。