最近,DeepSeek的研究员陈德里在个人博客上分享了一篇关于自主研究智能体的综述论文。这篇论文的诞生过程本身,就堪称一个绝佳的案例。
他坦言,这篇论文“1%是我写的,99%是Agent写的”。整个过程,他动用了自己开发的技能“DeliAutoResearch”,由DeepSeek-V4-Pro负责研究和写作,GPT-Image2负责绘图。经过6天时间、约108轮Agent调用,消耗了64.8万token,最终生成了2234行LaTeX代码,完成了一篇包含103个已验证参考文献、46页、538KB,并配有7个图表和4个表格的完整论文。

这篇论文的核心,正是探讨如何为自动研究智能体建立一个清晰的自主度分类体系。它系统性地分析了四大主流架构模式,并从可扩展性、成本、可靠性等多个维度进行了对比。同时,论文基于一个六维特征矩阵,深入剖析了17个主流系统,并最终提出了该领域面临的六大开放问题及相应的研究方向。

陈德里对此感触颇深。他认为,代码智能体的出现,正在导致计算机科学领域的论文数量“疯狂膨胀”。过去需要至少一个月才能完成的工作,如今他本人投入的“总CPU时间”不到两小时。当然,他也附上了一句免责声明:所有观点仅代表个人,与任何组织无关。

DeepSeek研究员与V4 Pro合写的论文
当前,基础模型的飞速发展正推动AI工具从单纯的研究辅助,转向真正的自主研究。但整个领域面临一个尴尬的局面:缺乏统一框架、术语混乱、评估标准不一。为了解决这个问题,陈德里和他的AI“合著者们”提出了一个L1到L5的自主分级体系。
这个体系巧妙地借鉴了自动驾驶的SAE分级标准,为混乱的AI智能体领域梳理出了一条清晰的演进谱系。

- L1(自动补全):这是最基础的级别,类似于早期的GitHub Copilot,核心能力是预测并补全用户的下一行代码。
- L2(任务执行):以ChatGPT、Claude等聊天机器人结合工具插件为代表。它们能够分解任务,但每一步执行都需要人类的明确批准。
- L3(多步骤执行):这是目前的主流水平,例如Claude Code、Cursor Agent。智能体可以自主执行10到100个步骤,只在关键决策点请求人类审核。
- L4(受限领域全自主):人类仅需提供研究目标和评估最终成果。智能体可以在特定领域内独立完成多步实验、编写代码乃至撰写论文,但其核心局限在于无法自主选择研究问题。
- L5(完全自定议程):这是尚未实现的理想状态。智能体能够自主选题、分配资源、进行长期知识积累并开展跨领域持续研究。其核心瓶颈在于持续知识积累、可靠自我评估以及架构的规模化。
目前,行业前沿初步触及L4的门槛,而L5仍是一个远景设想。论文明确指出,真正的瓶颈并非模型的基础能力,而在于“持续知识积累”和“可靠自我评估”这两个系统性难题。
除了按自主性分级,论文还从架构角度总结了四种主流模式。
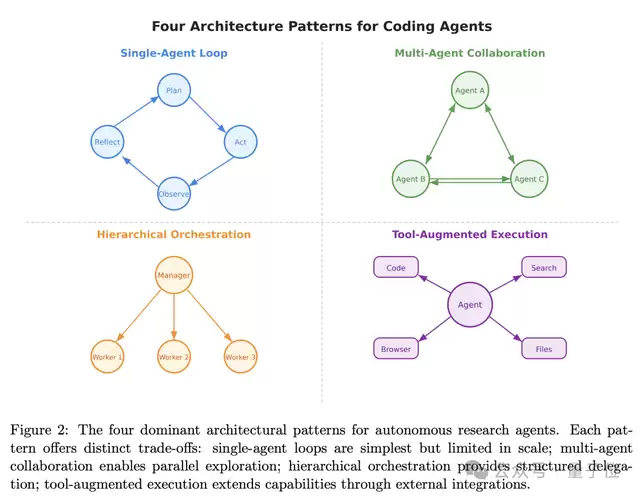
- 单智能体循环:以早期的ReAct、Reflexion、LATS、思维树(ToT)为代表。由单一模型进行“推理-行动-观察”的循环迭代。优点是简单高效,但处理复杂任务的能力有限。
- 多智能体协作:以CAMEL、AutoGen、MetaGPT等框架为代表。通过多个智能体分工协作、多视角交叉验证来提升效果。缺点是成本较高,且智能体间的沟通容易陷入混乱。
- 分层调度:以Claude Code和Devin为代表。采用分层规划、任务分解的策略,非常适合长周期、高复杂度的研究任务,也易于人类监管。
- 工具增强执行:以SWE-Agent等为代表。其核心能力高度依赖于外部工具,如代码执行环境、网页浏览器、API/数据库、多模态工具等。智能体与计算机接口(ACI)的设计直接决定了其性能天花板。
这四种模式并无绝对的优劣之分,关键在于针对不同的任务场景选择合适的工具:简单短任务可选单智能体循环(低成本、易实现);需要多视角纠错的复杂分工可选多智能体协作;长周期、高复杂度研究适合分层调度(强规划、易监管);需要深度对接外部工具和环境时,工具增强执行则是更优选择(其能力边界由工具决定)。
不过在实际应用中,为了取长补短,混合架构正成为更普遍的选择。
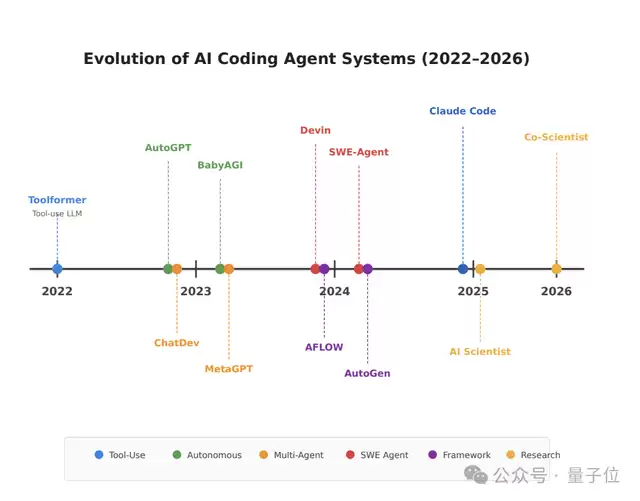
基于上述研究框架,论文横向对比了当前常见的17个自主研究智能体。分析揭示,该领域已经从早期脆弱、通用的原型,演进到了L4级别的受限领域专用系统。其中,代码智能体的成熟度最高,而科学智能体也已开始产出可验证的新发现。
而要迈向L5的完全自主,核心瓶颈依然清晰:持续知识积累、可靠自我评估以及架构的规模化。
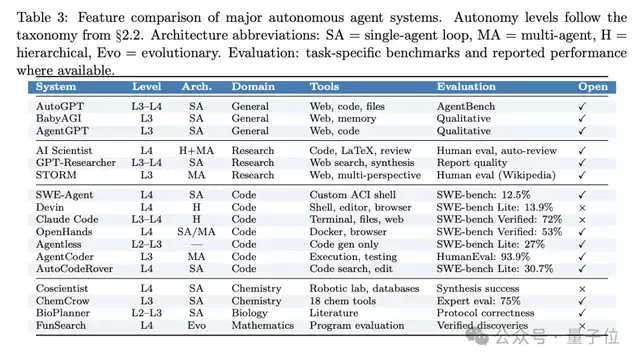
最后,论文提纲挈领地指出了领域面临的六大开放问题:
- 认知循环陷阱:智能体容易陷入重复无效的策略循环,缺乏自我终止能力。
- 上下文限制:固定的上下文窗口(4K-1M token)无法支撑真正长周期的研究。
- 创新性评估:目前缺乏自动化方法来衡量研究成果的原创性与价值。
- 可复现性:模型的随机性和对提示词的敏感性,导致实验结果难以稳定复现。
- 安全与伦理:存在技术双用途风险、自主性提升带来的失控风险以及学术诚信风险。
- 成本问题:单任务成本可能高达50美元,高昂的成本正在加剧科研资源的不平等。
One More Thing
陈德里在分享中提到了一个有趣的视角。他坦言,高强度的工作导致的精力不足,曾让他搁置了许多个人计划,比如维护博客和持续写作。而现在,智能体让他有机会将这些事情重新捡起来。
除了这篇研究综述,他还利用智能体高效更新了个人主页。这一切都指向一个趋势:有了智能体的辅助,人类的角色正在从具体的“执行者”,转变为更高层次的“发起者”和“决策者”。效率的提升是显而易见的,而人与AI协作的边界,也正在被重新定义。