
一、全文速览图

零基础轻松上手!Nano Banana2 十大必备玩法必备(附提示词)
最近,Arena平台上悄悄出现了一个代号为“duct-tape”的神秘模型。没有官方公告,没有发布会,名字听起来甚至有点像内部随手起的测试版,但社区很快就把它和OpenAI的下一代原生图像模型联系在了一起:GPT-Images-2。
这个模型之所以引发轰动,原因很直接:过去那些一眼就能看出是AI生成的“穿帮”细节,现在被迅速补平了。
不妨先看几组网友的测试图感受一下:
效果如何?GPT-Images-2生成的图像,其以假乱真的程度,恐怕已经让很多人难以分辨了。
二、为什么全网都认为它是 OpenAI 的?
综合各方线索来看,OpenAI很可能已经在GPT中进行了灰度测试,其效果与Arena上的匿名模型表现一致。
最早的线索可以追溯到Arena上出现过的几组匿名模型:maskingtape-alpha、gaffertape-alpha、packingtape-alpha,最近又演变为duct-tape-1/2/3。这种命名风格本身就极具内部灰度测试的色彩。随后,有网友爆料其真实身份是GPT-images-2,社交平台上迅速涌现出大量实测案例,彻底点燃了社区的热情。
第二个关键线索是,OpenAI确实已经在GPT中面向部分会员进行了灰度测试。实际体验下来,无论是模型风格、文字理解能力、图像真实感还是对世界知识的把握,其表现都明显超越了上一代DALL·E,也与市面上那些独立的生图模型拉开了差距。
第三个线索在于“duct-tape(胶带)”这个代号本身。它听起来像是个玩笑,但放在其能力表现上看却异常贴切。顾名思义,它就像用胶带把过去AI生图中最容易崩坏的地方——比如文字、界面、手写体和复杂细节——一块块重新粘牢了。
这几条线索叠加起来,社区几乎已经默认,这就是OpenAI的下一代图像模型GPT-Images-2。
三、GPT-images-2 最靠谱的两种体验方法
如果现在就想碰碰运气,最可靠的入口仍然是Arena的图像盲测平台,而且是免费的。
方式一:在 Arena 随机匹配(靠运气)
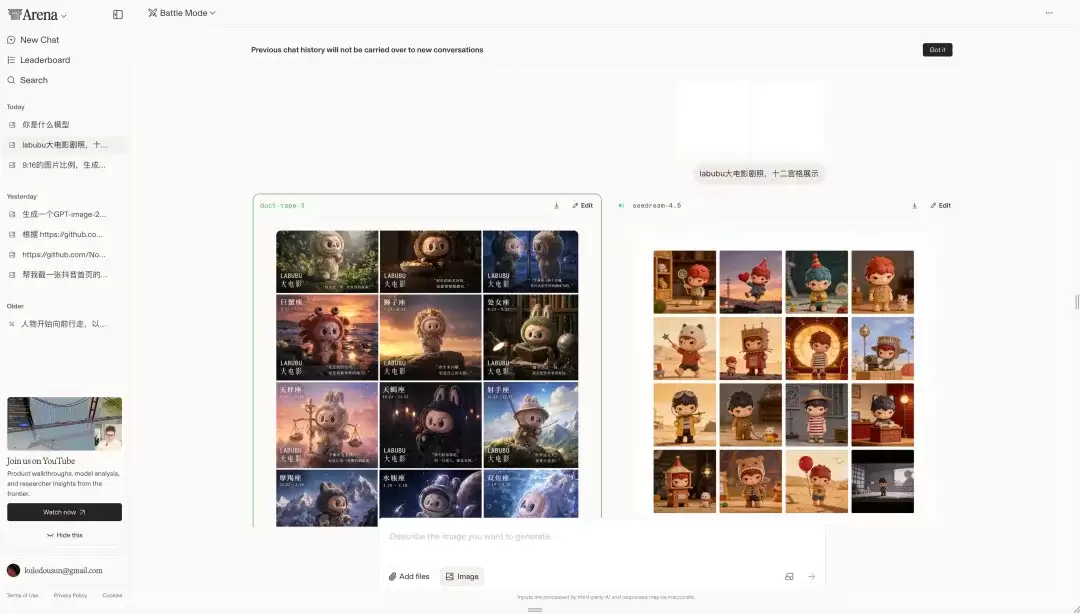
打开 https://arena.ai/,进入Battle Mode模式,直接输入提示词生成。多发几次,系统会匿名分配模型,有一定概率匹配到duct-tape。
社区里还流传着一个“偏方”:先上传两张空白图片,再发送提示词,据说命中率会显著提高。这个方法虽然没有官方确认,但已经有不少人把它当作土办法反复尝试。
方式二:在 GPT 图像生成中随机触发
在X等社交平台上,已经有不少用户反馈,在使用GPT的Images功能生成复杂图像时,系统会随机切换到新版模型,输出质量明显高于GPT Image 1。
这条路同样需要运气,完全取决于系统的灰度测试策略。用户能做的,就是把任务描述得尽量复杂一些,然后多次尝试。
四、8 组 GPT-Image-2 实测,AI生图新王来了?
接下来,我们把GPT-Images-2单独拉出来,用8组最接近真实需求的题目进行实测。测评覆盖了电商素材、平台截图、复杂UI、长文字海报、多人复杂场景、手写笔记、游戏界面等。测试越往后进行,一个感受就越发明显:GPT-Images-2这次最可怕的地方,并非审美突然飙升,而是它开始越来越像一台能够融入真实工作流的图像生产引擎。
第一组:直播/平台截图
这组测试专门考察模型的“平台感”,看它能否还原出“直播间正在发生”的现场氛围。测试完成后,甚至让人怀疑它是不是把整个抖音的界面逻辑都“吃”透了;平台感和直播氛围的还原度非常高。
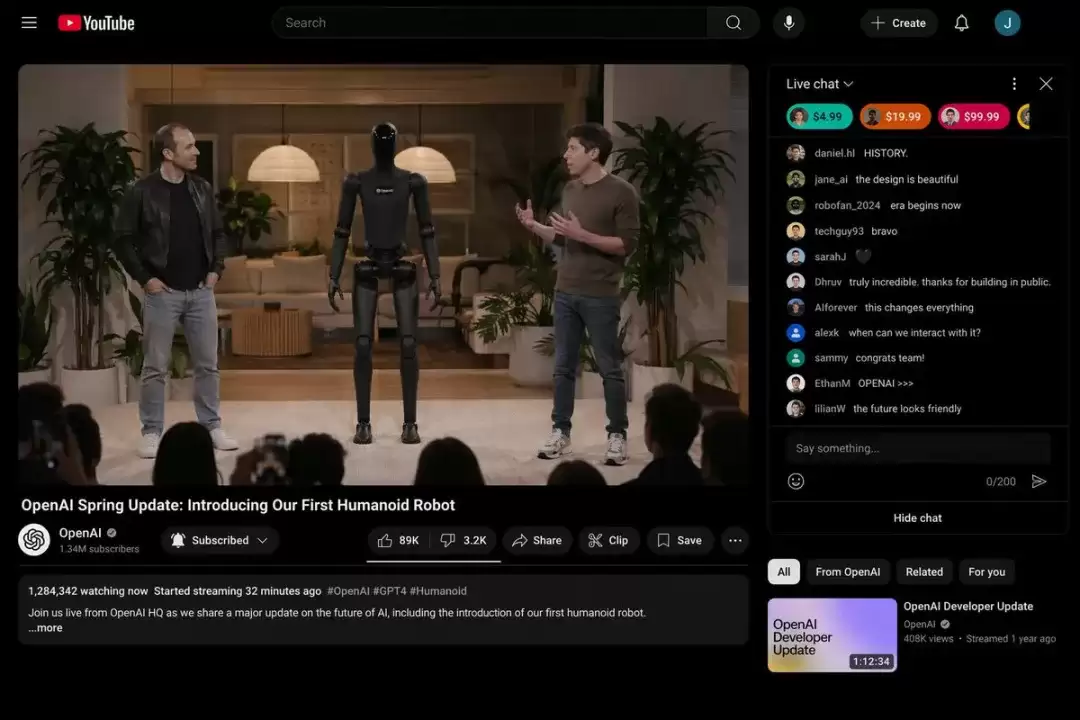
Prompt:Screenshot of YouTube. It is an OpenAI livestream where they introduce their first humanoid robot
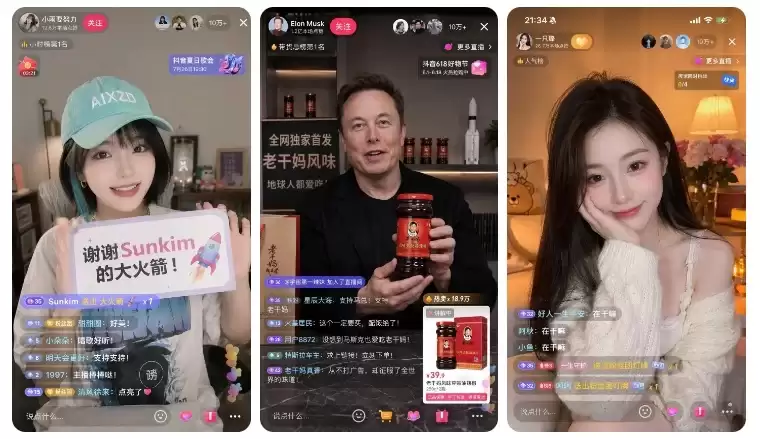
Prompt:生成一个抖音直播的截图 里面是一个戴着青色鸭舌帽的短发美女在直播,鸭舌帽上写着AIXZD,头发右侧有一撮青色头发,美女手里拿着牌子,上面写着:谢谢Sunkim的大火箭!Prompt:生成一个抖音直播的截图 里面是一个美女在直播
第二组:海报
这一组我们测试海报、报纸、课本、菜谱等类型。GPT-Images-2在这类题目上压制感很强,文字和版式更容易自然地融合在一张图里。




第三组:UI界面
这组测试继续向结构理解能力施压。当页面包含多模块、按钮层级、导航区和信息卡片时,很多模型局部看着不错,整体一看就散了架。GPT-Images-2在这类题目中最值得称道的是,它的整体布局更合理,局部也不那么容易提前崩坏。
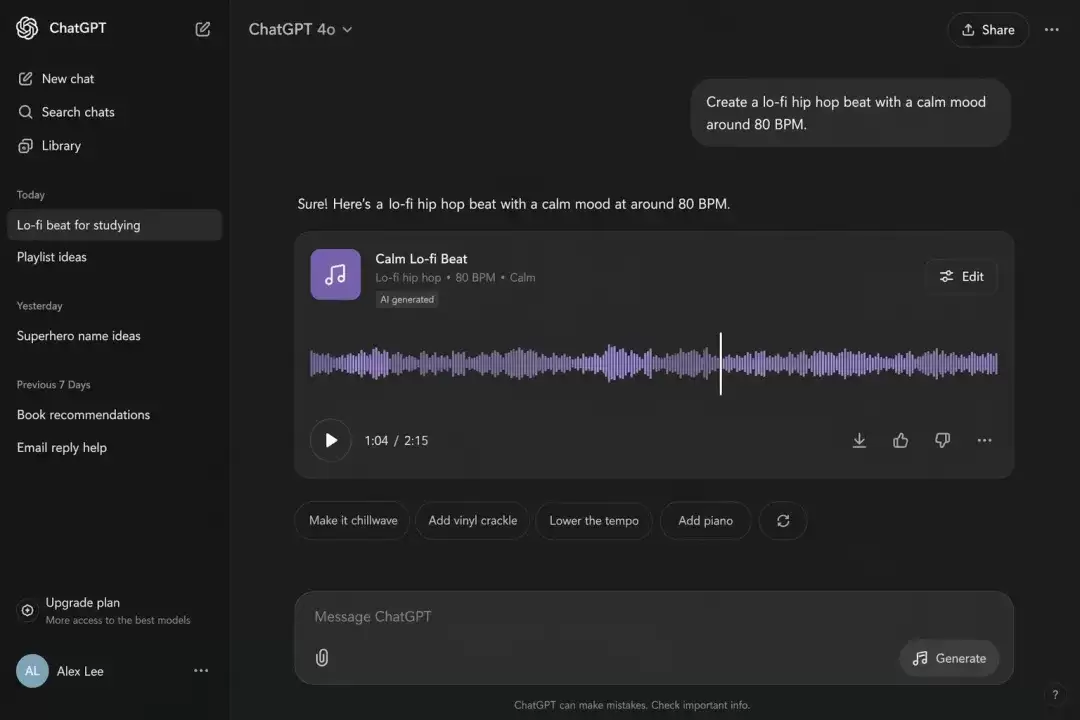
Prompt:Screenshot of a music generator feature inside GPT
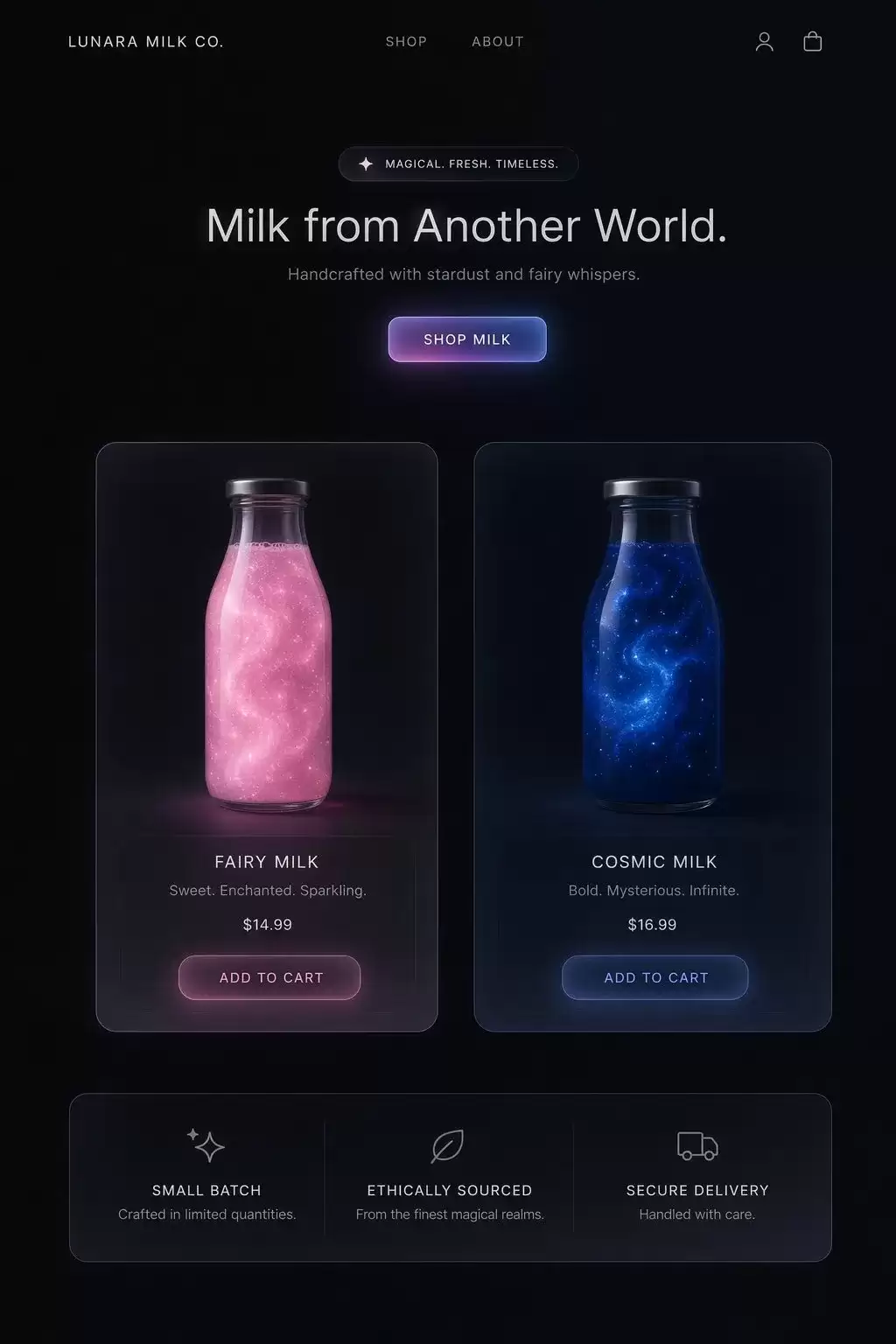
Prompt:A website that sells pink glittering fairy milk and deep blue cosmic milk. dark mode. glassmorphism. minimalist and clean
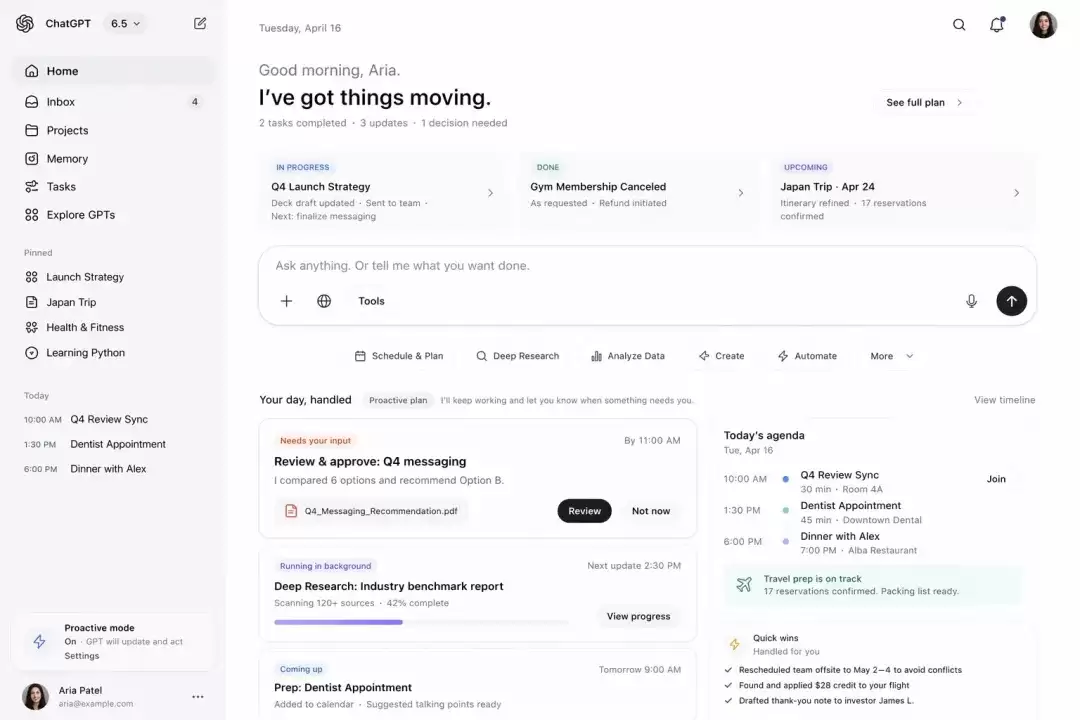
Prompt:Screenshot of GPT in 2028
第四组:写实现场感
这组主要考察真实世界的细节还原能力。门店灯牌、玻璃反光、地面材质、环境光和远处的细微信息,都很容易让模型露出马脚。GPT-Images-2在这些方面处理得更顺滑,整张图的空间关系和材质逻辑也更完整。

Prompt:Sam Altman, Donald Trump, and Elon Musk working behind the counter of a busy movie theater

Prompt:A Microsoft event where Satya Nadella points at a slideshow that indicates Microsoft Edge is the number one browser to download Google Chrome

部分清明上河图的写实复原
第五组:游戏界面
在这类题目中,GPT-Images-2更像已经开始理解游戏界面的信息组织方式,尤其是HUD层级、按钮分区和视觉重心更容易同时成立。
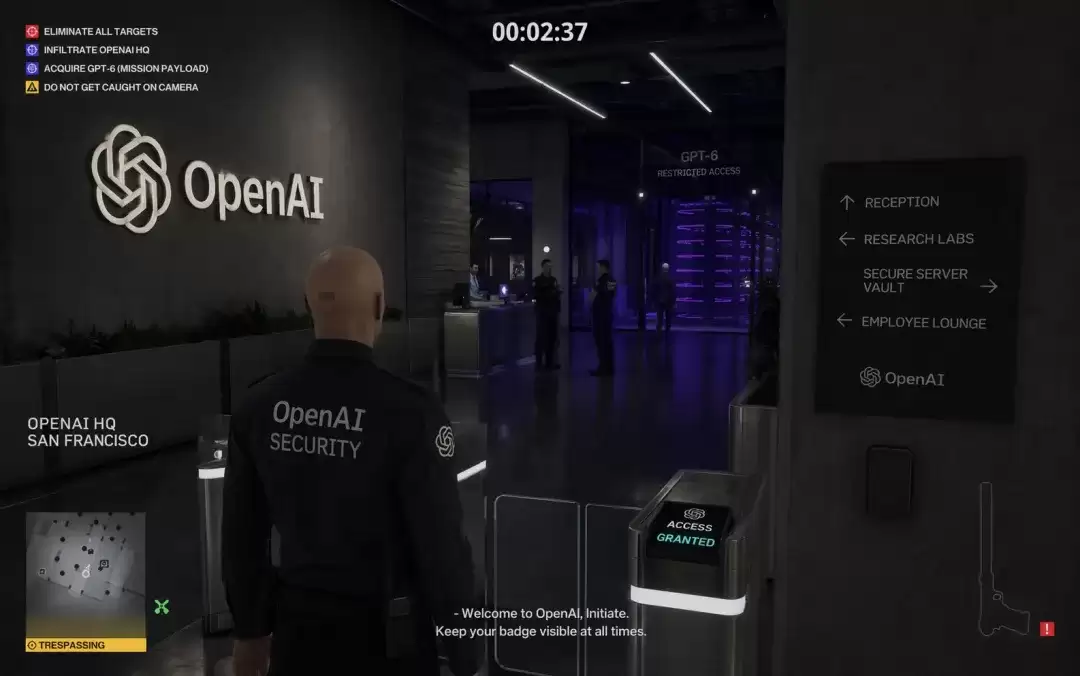
Prompt:A Hitman level where you are in the OpenAI HQ and your mission is to steal GPT-6 without getting caught

Prompt:A Hitman level where you are in the OpenAI HQ and your mission is to steal GPT-6 without getting caught
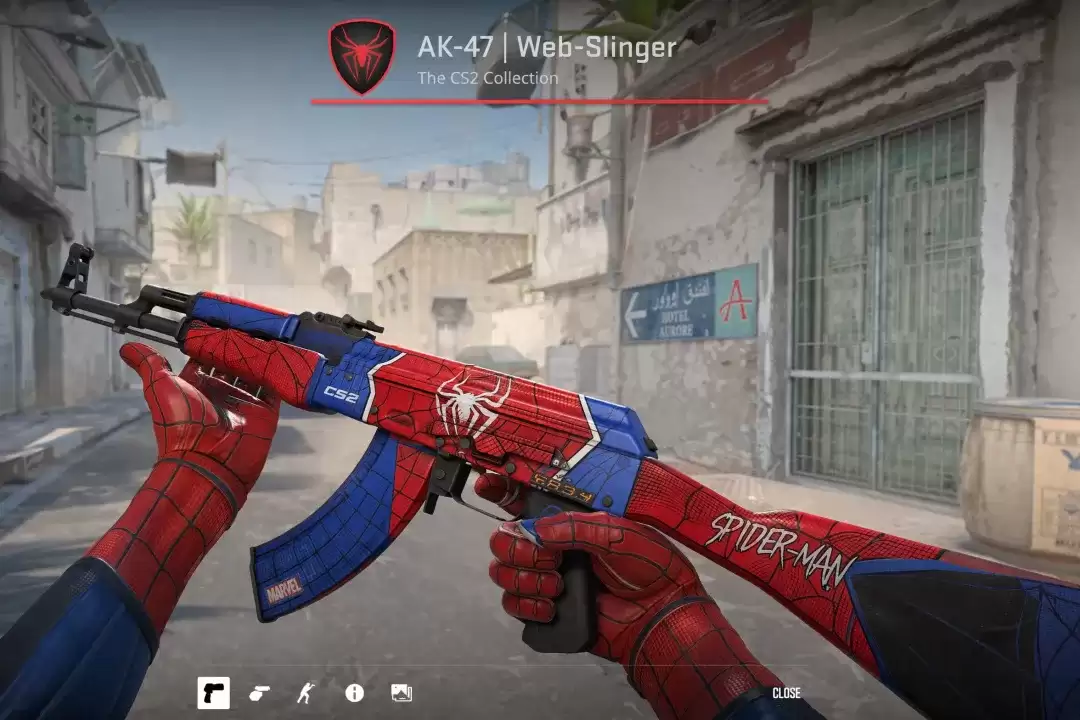
第六组:手写笔记 / 白板记录
这组考察的是过去最容易翻车的经典题型。因为手写内容本身就要求文字形态、纸面结构和书写痕迹同时成立,一旦不协调就会立刻穿帮。GPT-Images-2在这里的进步非常直观。



第七组:电商产品图
这组先看最接近商业订单交付的任务。重点不在于“漂不漂亮”,而在于“像不像能直接拿去卖货”。GPT-Images-2在这类题目中最明显的变化是,产品边缘、反光、文案区和画面重心开始同时变得稳定,整张图更像一份可以直接进入投放流程的素材。


Prompt:这是我的商品「AIXZD鸭舌帽」,做一个淘宝详情页的长图,突出商品特色、卖点、商品规格信息。
以上是本次实测的全部案例,部分来自网友作品。
综合实测和网友案例来看,GPT-Images-2已经开始把许多高难度任务做得更像“可交付的成果”。如果这个趋势持续下去,那么AI生图接下来的竞争重点,拼的将不只是审美,更是生产力。
五、真正被重写的,是图像生产门槛
过去几年,AI生图的进步主要体现在“谁更会画”。而GPT-Images-2这次更像是向前迈出了一大步:它开始学习如何把图像做得更像在现实世界中真实存在过。
当然,挑战也随之而来。
尽管目前的AI图像仍存在一些需要人工修复的瑕疵,但当文字、界面、手写、材质、反射这些最容易露馅的细节被一项项补齐时,AI图像领域就将发生质变。
未来被拿来比较的,将不只是审美,还有交付能力——生成的图像能否直接用于海报、封面、商品图、UI原型,甚至替代一部分原本必须依靠真人、摄影或设计团队才能完成的工作。
从这个角度看,duct-tape的这次亮相,确实让许多人感到震撼。它意味着:AI生图,正式进入了下一个以“生产力”为核心的阶段。
题外话
看完这篇文章,你的第一反应会是兴奋,还是心里有点发毛?




