关于DeepSeek,业内一直有个流传甚广的印象:这家公司影响力巨大,但似乎不怎么赚钱。
原因看起来很简单:它没有订阅制,没有花里胡哨的增值服务,唯一的收费项目就是API,而价格又便宜得惊人,还时不时来个“骨折”降价。
就在5月22日晚,DeepSeek宣布其最新旗舰模型API价格永久下调75%,从6月1日起生效。这已经不是第一次了。
但问题来了:这一切背后的商业逻辑究竟是什么?难道真是“赔本赚吆喝”吗?
上周末,亚马逊AWS新加坡区域的生成式AI技术负责人吉里什·迪利普·帕蒂尔(Girish Dilip Patil)发表了一篇题为《DeepSeek的10万亿美元大战略》的分析文章,从产业内部视角,为我们拆解了DeepSeek的底层棋局。

文章提出了一个极其反常识的判断:DeepSeek正以“低价”为核心叙事,在AI产业链中引发一场结构性海啸。其目标并非单纯争夺市场份额,而是要彻底重塑现有的AI硬件产业格局。在这场变革中,英伟达、SK海力士、三星、美光等巨头现有的领先地位可能被动摇,部分市场机会将向中国公司转移。
那“10万亿美元”指的是什么?正是整个因DeepSeek而可能被撬动的、从硬件到应用的全新市场机会。
这篇文章迅速引爆了全球AI圈的讨论,不止在中文互联网,在X(原Twitter)上也获得了广泛关注。颇具影响力的AI内容博主罗汉·保罗(Rohan Paul)就转载了此文,并给予了高度评价。值得一提的是,罗汉的粉丝中包括谷歌现任CEO桑达尔·皮查伊。
说回作者吉里什,他的视角之所以独特,在于其工作性质让他必须接触AI全栈——从大模型架构、推理优化,到GPU硬件、云服务、企业部署乃至开发者生态。因此,他分析DeepSeek时,跳出了单纯的“模型能力”对比,而是从最底层的技术变革出发,逐步推演至硬件产业,最终勾勒出整个生态的图景。
那么,这篇备受关注的文章到底说了些什么?
01 改写底层逻辑
一提到“便宜”,我们很容易联想到过去的各种商业大战——网约车、外卖、共享单车……“补贴抢市场”的剧本似乎已经刻进了我们的认知里。
但DeepSeek的“便宜”,本质并非抢流量,而是一种战略性的“解绑”:将AI能力从对特定顶级硬件的重度依赖中解放出来。
从V3到V4,DeepSeek在模型记忆(Memory)和推理(Inference)上的两大改进,最终都指向同一个字:“省”。
大模型每次对话,都需要将之前的上下文存储在KV Cache中,而这部分通常消耗最昂贵、也最紧缺的HBM(高带宽内存)。根据吉里什的测算,在100万token上下文、8bit KV精度和16bit索引精度下,DeepSeek V4的KV Cache仅占5.48GB HBM。相比之下,GLM5需要60GB,Qwen3-235B-A22B更是高达89GB。
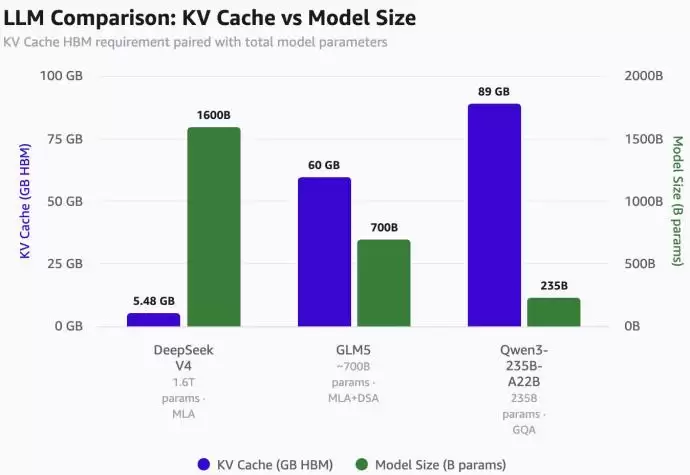
这巨大的差距不仅在于参数规模,更源于架构设计。DeepSeek V4采用的MoE(混合专家)、MLA(多头潜在注意力)以及DSA、CSA、HCA等一系列设计,核心目标是一致的:将长上下文从吞噬显存的“黑洞”,转变为可被压缩、转存、重新加载的系统工程问题。
一旦KV Cache被压缩到如此小的规模,意味着模型推理可以更多地依赖SSD、NAND闪存、LPDDR内存等价格亲民的存储介质。结果就是,你不再需要购买那么多昂贵的HBM,同时,对英伟达顶级GPU的依赖也随之降低。
过去,想入局AI,先得斥资数百万购买英伟达GPU。花钱还是其次,关键还得“等”。目前HBM的短缺已到何种程度?2025年11月下单的GB200,至少要等到2026年第二季度才能交货。回想2022年特斯拉芯片短缺最严重的时期,一辆Model Y的最长交付周期也不过24周。
某种意义上,一张高端GPU,比造一辆新能源汽车还要难。
正因如此,DeepSeek的技术叙事对中国AI产业链意义重大。国产芯片当前最大的机会,未必是立刻在绝对性能上追平英伟达顶级GPU,而是先找到能够真实承载AI负载的应用场景。
DeepSeek将模型做得更省显存、更适应长上下文、更容易被拆分到不同硬件上运行,这无异于为国产GPU、存储厂商、服务器厂商以及异构计算框架打开了一扇门,留出了关键的“接口”。
此前,英伟达、SK海力士、三星、美光等公司收入暴涨,正是因为AI硬件的所有压力都集中在GPU和HBM这条狭窄的赛道上。DeepSeek的策略,相当于把更多国产厂商拉入了游戏,让他们有机会参与到推理、缓存、存储、调度的每一个环节中。
模型不再只为最强的硬件服务,硬件也不必只有最强的那一类才有价值。中国的产业机会,正蕴藏于此。
再看其API定价策略。就在吉里什文章发布前一天,DeepSeek V4 Pro宣布token价格永久下调75%,输入token价格降至每百万0.435美元,缓存命中价格更是低至每百万0.0036美元。这个价格比Claude Opus 4.7便宜19倍,比GPT-5.5便宜12倍。
如此力度的降价,绝非简单的“赔本赚吆喝”。在DeepSeek开启首次融资时,创始人梁文锋就曾向投资人明确,要为DeepSeek建立健康的商业模式。显然,他不可能让公司长期亏损。
低价API本质上是一种高明的生态策略,也是DeepSeek向整个产业链释放的明确信号:它仍在赚钱,但梁文锋不急于赚眼前的“快钱”和“大钱”。他的目标,是让足够多的开发者、企业、硬件厂商围绕DeepSeek的技术体系进行适配和投入。
原因很简单:成本足够低,试错门槛就足够低。花几百甚至几十块钱就能完成初步适配,对企业而言,这笔账实在太划算了。
一旦生态形成,DeepSeek的角色就将从一家“基座模型公司”,蜕变为“AI基础设施公司”。它负责制定标准、定义产业规则,这或许才是梁文锋真正看重的价值。
梳理下来,DeepSeek的技术选择与商业策略背后,存在一个清晰而强大的逻辑闭环:
降低模型对顶级硬件的依赖 → 让更多硬件厂商有机会参与,形成良性竞争 → 竞争促使硬件成本整体下降 → 更低的硬件成本支撑更低的API定价 → 极低的API价格吸引海量开发者和应用 → 应用爆发产生巨大的推理负载 → 巨大的负载催生对数据中心、存储、电力、散热设施的庞大需求。
这是一个自我强化的正向飞轮,而DeepSeek,正站在这个飞轮的起点。
这不禁让人联想到当年的Linux:它不靠操作系统授权费赚钱,却最终撬动了整个开源软件与服务器产业的生态。DeepSeek的开源策略、低价API、毫无保留的技术论文分享,都在为同一个终极目标服务——成为事实标准,然后在基于此标准构建的庞大产业链中,获取最核心、最持久的价值。
02 从算力到电力
如果DeepSeek的野心真是站在整个AI生态的起点,那么宁德时代对其的投资,就显得顺理成章了。
我们习惯用英伟达来指代AI基础设施,但真正的AI基础设施远不止GPU。它应该是数据中心、供电系统、散热方案、储能设备以及电网调度能力的总和。
这里存在一个反直觉的经济学现象:DeepSeek把单次推理成本打下来,按理应该降低对硬件和电力的总需求。但实际情况可能恰恰相反——降本会触发需求的指数级膨胀。
当API价格从每百万token几美元降到几毛钱软妹币,大量过去因成本过高而不敢尝试或浅尝辄止的应用场景,都会开始大规模调用模型。使用量的增长速度,很可能远超单次成本下降的速度。最终结果就是,全球AI推理的总负载不是减少,而是会大幅增加。
需求膨胀的直接后果,就是基础设施承受巨大压力。你需要更多的服务器来支撑业务,而这些服务器运行起来,就需要消耗更多的电力。
于是,一个结论浮出水面:数据中心的供电能力、散热效率、能源成本,将成为未来AI公司最核心的竞争力之一。
这并非空想,已是正在发生的现实。OpenAI与AMD的战略合作协议中,就明确约定了以“千兆瓦”(GW)为单位的算力部署里程碑。一千兆瓦是什么概念?相当于一座大型核电站的发电量。说到底,AI基础设施的竞争,早已演变为能源的竞争。
更进一步看,AI数据中心本身,正在成为一种新型的能源基础设施。
与传统数据中心相对平稳的负载不同,AI推理负载极易受应用流量波动影响。一个爆款产品可能瞬间引发模型调用量激增,随之而来的就是服务器、电力和散热的峰值压力。
对数据中心运营商而言,挑战不只是“电够不够用”,还包括如何管理电价、应对波动、配置备用电源和储能系统。
举个例子,许多地区的工业电价存在显著的峰谷差价,夜间用电便宜,白天高峰时段昂贵。如果数据中心配备储能系统,就可以在夜间低价时段充电,在白天电价高、负载大时放电。这样既节省了电费成本,也为应对突发流量提供了缓冲。
过去一年,宁德时代通过关联方,已经接触了数据中心和电力设备领域:投资第三方数据中心运营商世纪互联(VNET),布局高压直流供电系统厂商中恒电气。这些动作,都精准指向了AI数据中心的“电力侧”。
DeepSeek此轮融资的投资者名单,本身就是一张清晰的产业地图:国家AI基金代表政策支持与长期资本,显示这是国家战略层面的布局;腾讯代表应用层和巨量分发渠道,意味着DeepSeek的技术将快速渗透消费互联网;而宁德时代,代表的正是能源与数据中心底座——标志着国产AI基础设施的竞争,已从“算力”全面延伸至“电力”。
这早已不是一次普通的创业公司融资,而是在构建一个围绕DeepSeek技术的、涵盖资本、应用、能源的“AI基建联盟”。

03 部分闭环与需求制造
回看去年,DeepSeek、智谱、MiniMax、月之暗面(Kimi)之间的差异还不像今天这般明显,大家还都是颇具潜力的“小龙”。但时至今日,四家公司已走上截然不同的道路。
智谱选择的是政企市场路线。标普全球(S&P Global)对其的描述是,收入主要来自本地部署和云端部署。智谱的API价格并不便宜,甚至是“小龙”中最贵的,但这并未阻碍其增长。目前其市值已达5700亿港元,上市四个多月,股价累计涨幅超过10倍。
智谱的增长逻辑很清晰:其核心客户是企业和政府机构,他们需要的是能稳定交付、通过合规审查、并能在自有机房中安全运行的解决方案。这恰恰是智谱的强项。创始人唐杰近期表示看好“长周期任务”,或许暗示GLM模型的下一阶段特性将围绕此展开。
尽管智谱也开源,但它无法复制DeepSeek的路径。作为上市公司,它必须向股东证明持续的收入和利润增长。大幅压低API价格意味着牺牲利润率,这与股东利益直接冲突。
MiniMax则走出了另一条路,更偏向应用和多模态产品。在其收入结构中,海螺、星野、Ma vis等AI原生产品贡献了很大比例。根据其2025年财报,AI原生产品收入从2024年的2180万美元增至2025年的5310万美元,公司总收入增至7900万美元。
因此,MiniMax的商业逻辑是尽快将模型能力封装成用户愿意付费的产品,并通过产品体验来获取客户。它会学习DeepSeek的成本效率,因为视频、语音、智能体都是重算力消耗的产品,成本控制不住,商业化就很难跑通。但和智谱一样,MiniMax也需要利润、需要用户订阅收入,并且非常看重海外市场。
相比之下,月之暗面(Kimi)是最接近DeepSeek的,但仍有本质不同。
首先,和DeepSeek一样,Kimi尚未上市。它同时拥有C端聊天会员服务和B端API,也开源了如Kimi K2.6这样的模型。据外媒报道,其年化经常性收入在4月已超过2亿美元,增长来自付费订阅和API使用。根据OpenRouter数据,调用Kimi K2.5最多的两个场景是OpenClaw和AI编程软件Kilo Code,都是日常办公入口。
Kimi与DeepSeek的核心区别在于,前者更注重“打开次数”和用户直接体验。因为Kimi的强项——长文本处理、代码、智能体——都是高度“直接面向用户”的场景。它的目标是把模型能力包装成一个用户愿意高频使用、长期依赖的产品入口。
反观DeepSeek的APP,虽然流量巨大,但它并非一个功能丰富的“超级APP”,更像一个专注于问答功能的工具。
归根结底,智谱、MiniMax、Kimi都在回答同一个问题:用户为什么愿意为我付费?
而DeepSeek在回答另一个问题:整个产业链为什么要围绕我来进行适配?
DeepSeek的API定价、开源模型、对国产AI芯片的积极适配,本质上是将自己打造成一个行业“定价基准”和“性能标尺”。企业采购模型时会拿它比价,开发者选择模型时会以它为参考,芯片和存储厂商做硬件优化时也会对标它的需求。
一旦DeepSeek成功奠定这个生态起点的地位,整个AI产业链的定价权、技术路线乃至价值分配,都可能需要围绕梁文锋设定的框架重新调整。
这也解释了,为什么DeepSeek敢于在API价格上如此激进。因为价格,只是它宏大故事中最显眼、最易被感知的那一部分。