在生物医学信息检索与人工智能交叉领域,如何让机器学习模型精准理解并回答基于科研文献的专业问题,是一项关键挑战。本文将深入解析PubMedQA——一个直接从PubMed海量摘要中构建的生物医学问答数据集,它专为训练与评估模型在专业文本上的逻辑推理与阅读理解能力而设计。
那么,PubMedQA的核心任务是什么?其目标非常明确:给定一个具体的生物医学研究问题(例如“术前使用他汀类药物能否降低冠状动脉搭桥术后心房颤动的发生率?”),模型需要仔细阅读对应的学术论文摘要,经过推理分析后,最终输出“是”、“否”或“可能”的确定性判断。该数据集规模庞大,共包含1000个由领域专家精确标注的实例、6.12万个未标注实例,以及超过21.1万个人工生成的问答对,为模型训练提供了丰富资源。
PubMedQA的每个数据样本均经过精心设计,结构清晰,包含以下四个核心组成部分:
第一是研究问题,通常直接源自论文标题或由其衍生而来;
第二是上下文,即论文的摘要正文,但刻意隐去了结论部分;
第三是“长答案”,这正是被隐去的摘要结论,理论上它应能直接回应问题;
第四是总结性答案,即最终的“是/否/可能”判断。
这种独特的结构使PubMedQA在众多数据集中脱颖而出。它是首个要求模型对生物医学研究文本进行深度推理,特别是对其中的定量数据、实验证据与逻辑关系进行分析,才能得出答案的问答评测基准。这显著提升了任务难度,对模型的真实理解能力提出了更高要求。
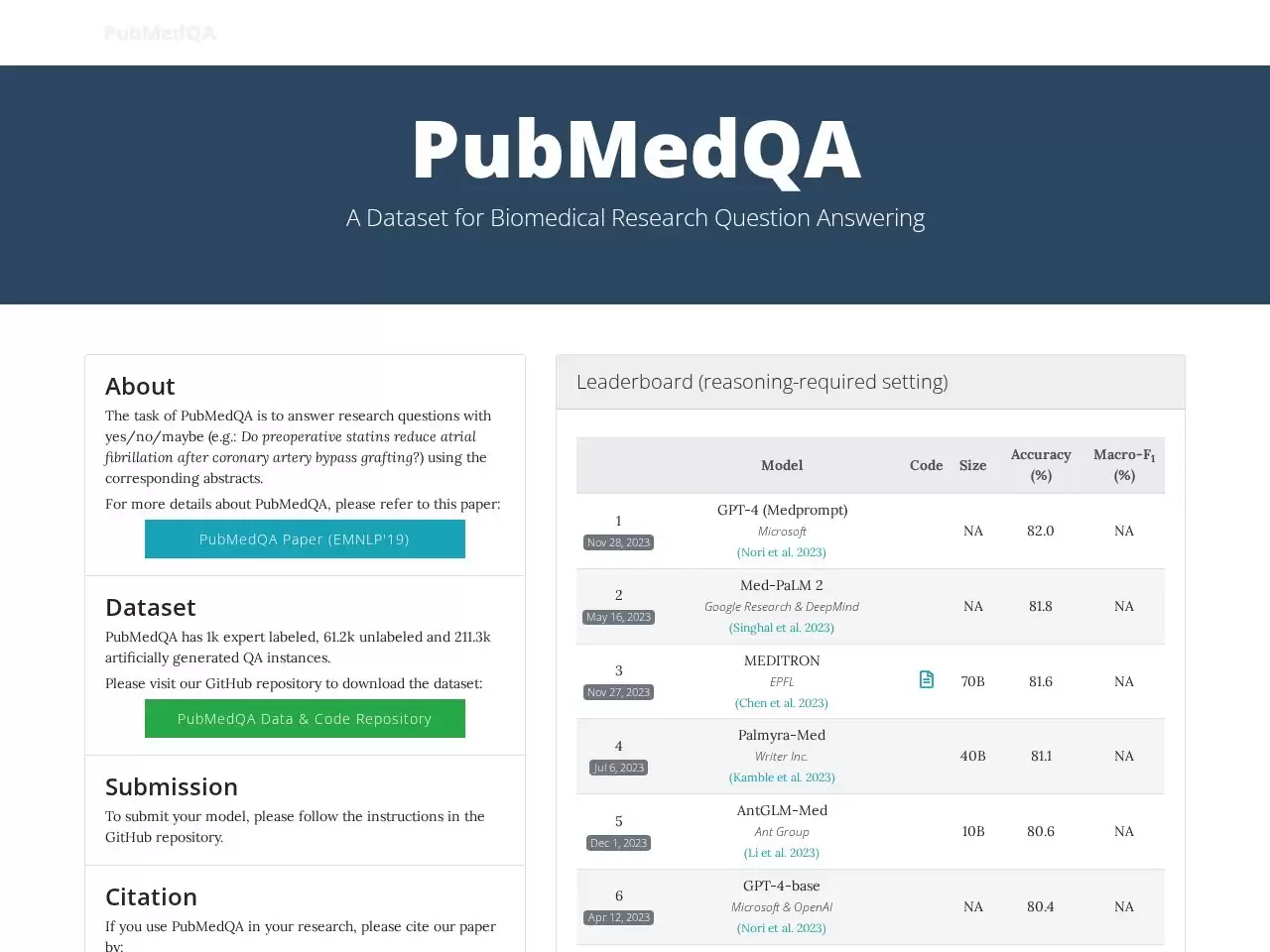
目前,在该数据集上取得最佳性能的模型,是基于BioBERT预训练模型进行多阶段微调,并引入长答案的词袋统计特征作为辅助监督信号。即便如此,其最高准确率也仅为68.1%。作为对比,人类专家在此任务上的平均准确率约为78.0%,而一个简单的“多数类基线”模型准确率只有55.2%。这些数据清晰地揭示,现有人工智能模型在生物医学文本推理方面仍有显著差距,存在巨大的优化与提升空间。
对于致力于生物医学自然语言处理、智能问答系统或文献挖掘的研究人员与开发者,PubMedQA数据集已全面公开,可通过其官方项目页面获取,以促进该领域的技术进步与创新应用。




