随着AI应用从概念验证迈向规模化部署,企业面临的算力挑战正日益复杂化。日常办公与开发流程需要持续稳定,而大模型推理、多智能体协同等高负载任务又亟待处理,同时还需在成本控制、快速部署与高效运维之间取得平衡。市场呼唤的,已不仅是单一的“性能怪兽”,而是一个能够灵活应对多重压力的综合性算力平台。
正是洞察到这一核心需求,英特尔近期推出了至强600工作站处理器与锐炫Pro B70/B65 GPU组合。这套方案的核心策略非常清晰:通过CPU与GPU在架构层面的深度融合与协同,构建一个“攻守兼备、软硬一体”的统一平台,旨在为AI开发者和企业用户提供集高性能、高灵活性与高性价比于一体的新一代工作站解决方案。

英特尔市场营销集团副总裁、中国区总经理 郭威
平台化重塑:超越单纯的性能竞赛
本次产品发布的意义,远超硬件参数的简单升级。其真正的价值在于,英特尔正致力于对平台能力进行系统性重塑。这意味着,企业最终将获得一个经过深度优化与整合、能够无缝覆盖从轻量级应用到重型AI负载的完整算力单元。
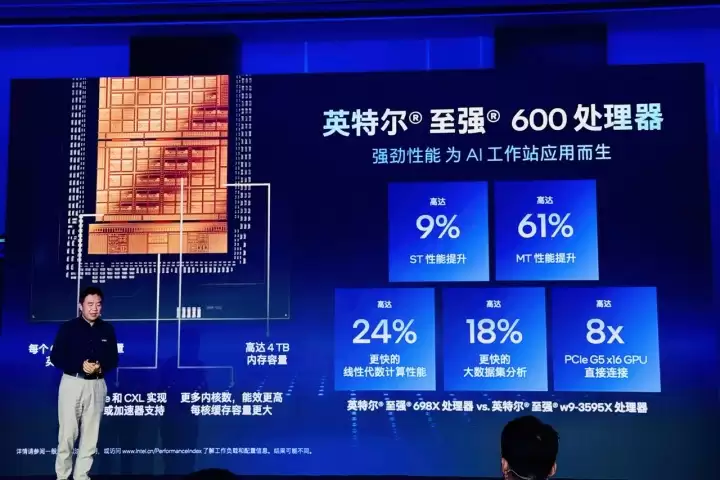
至强600:筑牢通用计算与AI加速的基石
作为整个平台的“智慧中枢”与资源调度核心,至强600工作站处理器在四个关键维度实现了显著增强。
首先是基础算力。其顶级型号拥有多达86个性能核心,多线程性能相比前代产品最高提升可达61%,睿频频率也达到了4.8GHz。这为各类复杂计算与数据处理任务提供了充沛的原始动力。
其次是扩展能力。处理器原生支持多达128条PCIe 5.0通道,结合芯片组,能够为多块GPU、高速NVMe存储以及高速网络设备提供充足的带宽,彻底解决硬件扩展时的带宽瓶颈问题。
更为关键的是AI能力的原生集成。至强600的每个核心均内置了英特尔AMX(高级矩阵扩展)引擎,并且新增了对FP16数据类型的原生支持。这使得其在AI与机器学习工作负载上的性能最高可提升17%。在实际应用中,例如图像降噪这类典型的视觉处理任务,处理速度甚至能提升4到5倍。这种提升不仅仅是“速度更快”,它实质性地降低了企业在本地部署和运行AI应用的技术门槛与总体拥有成本(TCO)。
此外,依托成熟的英特尔vPro平台技术,至强600还集成了多密钥内存加密、一键系统恢复等强大的企业级管理与安全特性,并能灵活适配塔式、机架式乃至边缘计算等多种部署形态,在追求极致性能的同时,确保了安全性与可管理性不打折扣。

锐炫Pro B70/B65:专注推理与图形处理的利器
如果说至强600构筑了稳固的计算基石,那么锐炫Pro B70/B65 GPU则是专为攻克图形与AI推理难题而打造的利器。基于第二代Xe2架构的锐炫Pro B70,针对图形渲染、通用并行计算及AI加速进行了全面优化。
它配备了高达32GB的大容量显存和32个Xe核心,AI算力峰值达到367 TOPS。这意味着它能够支持参数规模更大、上下文窗口更长的模型进行高效推理。特别是在多用户并发访问或高负载场景下,大显存与高算力的结合确保了系统依然能够维持高吞吐量与低延迟响应,这对于保障企业级AI应用的稳定与流畅体验至关重要。
在软件生态与部署灵活性方面,锐炫Pro B70支持SR-IOV虚拟化技术,并获得了超过50家独立软件供应商(ISV)的认证。同时,它对包括vLLM、oneAPI和PyTorch在内的完整Linux软件栈提供了良好支持。企业因此可以基于同一硬件平台,灵活地构建从单卡到多卡的系统配置,轻松实现从开发测试到生产部署的平滑过渡。同步推出的锐炫Pro B65同样提供32GB显存,算力为197 TOPS,为用户根据不同的预算和性能需求提供了更丰富的选择。

“双芯”协同,赋能实际场景
“1+1>2”的协同效应,最终需要在具体的应用场景中得到验证。英特尔联合众多生态合作伙伴,针对企业AI落地过程中的实际痛点,打造了一系列端到端的解决方案。
例如,与火山引擎联合推出的AgentSphere一体机。它充分利用至强600与锐炫Pro B70提供的32GB大显存和高密度算力,实现了更高并发、更低时延且更稳定的多智能体协同能力。一体机的标准化交付形态,也极大地简化了企业的部署流程与后期维护工作,使得AI员工管理平台这类创新应用能够快速上线并投入使用。
在智能办公领域,联想智能会议系统Lenovo SCH-900S借助锐炫Pro B70的强大算力与显存,实现了多会议室并发接入与实时AI会议纪要生成,显著提升了会议效率与协作体验。而在企业知识管理领域,飞致云基于锐炫Pro B70的多卡并行能力,打造了长上下文RAG(检索增强生成)解决方案,支持大语言模型和视觉大模型的高效并发推理,利用高带宽显存优势,大幅提升了智能问答系统的响应速度与答案质量。
垂直行业应用同样广泛受益。在医疗健康领域,东华医为利用该AI工作站平台实现了病历智能质控与辅助生成;在创意设计与数字内容领域,亦心闪绘借助锐炫Pro B70的强大图形与AI算力,实现了秒级“图生图”的实时渲染能力,让创作者的灵感能够瞬间转化为可视化的作品。
结语:开启规模化AI应用的务实之道
从处理器到GPU,从底层硬件架构到上层应用生态,英特尔此次的布局清晰地展现了其平台化战略思维。通过至强600与锐炫Pro B70/B65的深度协同,企业最终获得的是一套能够精准平衡高性能、低成本、易部署和高安全性的综合算力解决方案。

英特尔中国区技术部总经理高宇展示新品
当前,人工智能正处在从“技术可用”向“规模商用”跨越的关键时期。本地化、一体化、易于管理的算力平台其战略价值日益凸显。英特尔以“双芯协同”架构所规划的这条技术路径,显得尤为务实且高效——它不仅提供了应对复杂AI任务所需的强悍性能,同时周全地考虑了企业在实际运营中最关注的灵活性与总体经济性。这种以平台为核心、致力于系统级创新的发展思路,很可能将成为未来AI基础设施演进与升级的一个重要方向。




