Claude Code缓存实战指南一周节省3亿Token成本
编者按:许多开发者在体验 Claude Code 时,普遍反映 Token 消耗速度过快,尤其在长会话场景下,额度更容易见底。但从工程效率角度分析,真正决定成本的关键,往往不在于你新增了多少代码,而在于系统能否高效复用已经处理过的上下文信息。
本文将深入解析如何通过缓存机制显著降低 Token 消耗。数据显示,作者在一周内通过缓存复用节省了超过 3 亿 Token,其中单日最高缓存复用达 9100 万。由于缓存 Token 的计费成本仅为普通输入 Token 的 10%,这意味着 9100 万缓存 Token 的实际费用,仅相当于处理了约 900 万普通 Token。Claude Code 长会话之所以感觉更“经用”,其核心秘密并非模型免费工作,而是大量重复的上下文被智能识别并复用了。
Prompt caching(提示缓存)机制的核心在于“保持连续性”。Claude Code 会将系统提示、工具定义、CLAUDE.md、项目规则及历史对话进行分层缓存;只要后续请求的前缀与已缓存内容完全匹配,Claude 便可直接读取缓存,无需重新处理整段冗长上下文。事实上,Anthropic 内部也会密切监控 prompt cache 的命中率,因为这不仅关乎用户额度消耗,更直接影响模型服务的运营成本与整体效率。
对于大多数用户,无需深究所有技术细节,只需培养几个关键使用习惯:避免让会话空置超过1小时;在切换任务时进行清晰的会话交接;尽量避免频繁切换模型;处理大型文档时,优先将其放入 Projects 功能中,而非反复粘贴至对话窗口。
本文不仅是一个节省 Token 的技巧分享,更旨在提供一套更贴近工程师思维的使用方法论:将对话上下文视为可管理的资产,让缓存持续发挥价值,从而让长会话避免重复的无用功。
以下为正文:
过去一周,通过缓存机制节省的 Token 总量超过 3 亿,单日最高节省达 9100 万。
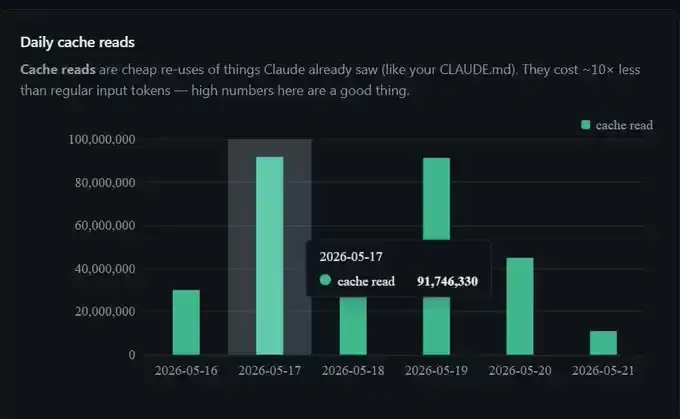
这并非调整了任何特殊设置,仅仅是 prompt caching 在后台正常工作的结果。
然而,真正理解缓存是什么,以及如何避免“中断”缓存之后,在相同的使用额度下,会话的持续能力得到了显著提升。因此,这里整理了一份 Claude Code prompt caching 的 80/20 实用指南,侧重于核心理解与实操,不涉及复杂的 API 底层细节。
核心摘要
缓存 Token 的成本仅为普通输入 Token 的 10%。因此,9100 万缓存 Token 的实际计费,大约只相当于 900 万普通 Token。
Claude Code 订阅版的缓存 TTL(存活时间)为 1 小时;API 默认是 5 分钟;而 Sub-agent 则固定为 5 分钟。
缓存机制分为三个层次:系统层、项目层和对话层。
在会话中途切换模型会破坏缓存,这包括开启“Opus plan”模式。
缓存到底如何计费?
每一个被成功复用的缓存 Token,其成本仅为重新处理一个普通输入 Token 的 10%。

所以,当仪表盘显示某一天有 9100 万 Token 命中了缓存时,实际产生的费用大概只相当于处理了 900 万 Token。这也是为什么,与没有缓存的情况相比,长时间使用 Claude Code 会让人感觉会话几乎是“免费”在延长。
在仪表盘中,有两个关键指标值得关注:
Cache create:指将内容首次写入缓存时产生的一次性成本。这部分投入会在后续对话中开始体现其价值。
Cache read:指 Claude 从缓存中复用的 Token,例如你的 CLAUDE.md、工具定义、历史对话消息等。相比重新作为输入处理,这部分成本便宜了 90%。

如果你的 Cache read 数值很高,说明你正在高效利用缓存;反之,如果这个数字很低,则意味着你可能在为同一批上下文反复付费。
Anthropic 的工程师 Thariq 曾指出:“我们实际上会监控 prompt cache 的命中率,一旦命中率过低,就会触发警报,甚至可能被认定为 SEV 级别的事故。”
他还在一篇文章中强调,当缓存命中率高时,会同时带来四个好处:Claude Code 的响应体感更快,Anthropic 的服务成本下降,你的订阅额度显得更耐用,长时间进行编码会话也变得更加可行。
但如果命中率很低,那么各方都会受损。
因此,双方的激励其实是一致的:Anthropic 希望你的缓存命中率更高,你自己也同样希望命中率更高。真正会拖累效率的,往往是一些看似不起眼、却会悄悄重置缓存的使用习惯。
缓存是如何在每一轮对话中增长的?
缓存机制依赖于“前缀匹配”原则。
不必陷入过深的技术细节,只需理解一个核心逻辑:只要某个位置之前的所有内容,与已经缓存的内容完全一致,Claude 就可以复用这部分缓存 Token,而无需重新处理。
一次全新的会话,大致是这样展开的:
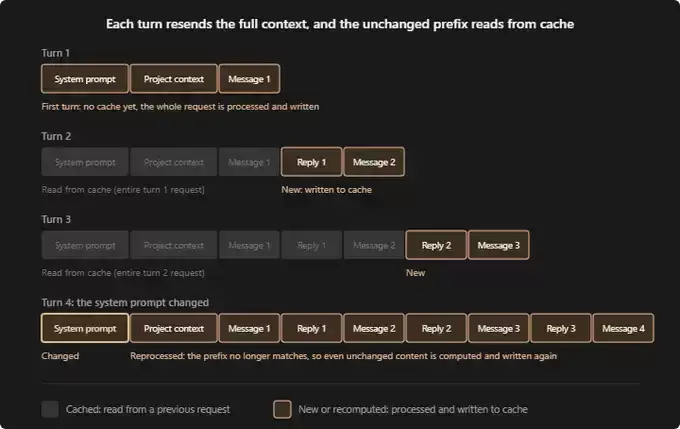
根据 Claude Code 的文档,其运行逻辑通常如下:
第一轮对话:此时尚未建立任何缓存。系统提示词、你的项目上下文(例如 CLAUDE.md、memory、项目规则),以及你的第一条消息,都会被完整地处理一遍,并写入缓存。这是成本最高的一轮。
第二轮对话:第一轮中的所有内容现在都已被缓存。Claude 只需要处理你的新回复以及下一条消息。这一轮的成本会显著降低。
第三轮及之后:逻辑相同。之前的对话历史仍然保留在缓存里,只有最新的一轮交互需要被重新处理。
缓存本身可以清晰地分为三个层次:

如图所示:
系统层:包括基础指令、工具定义(如 read、write、bash、grep、glob)和输出风格。这一层是全局缓存的。
项目层:包括 CLAUDE.md、memory、项目规则。这一层是按项目进行缓存的。
对话层:包括模型的回复和用户的消息,会随着每一轮对话的进行而不断增长。
如果在会话中途,系统层或项目层的任何内容发生了变化,那么所有相关的缓存内容都必须从头开始重新构建。这就是最“昂贵”的操作。可以想象一下:你已经聊到了第 16 条消息,这时突然修改了系统提示词,或者会话中断了一个小时以上,那么从第 1 条消息开始的所有 Token 都需要被重新处理并计费。
1 小时与 5 分钟的混淆
这是最容易产生误解的地方。
Claude Code 订阅版:默认的缓存 TTL 是 1 小时。
Claude API:默认 TTL 是 5 分钟。当然,你可以通过支付更高成本,将其提升到 1 小时。
任何计划下的 Sub-agent:其缓存 TTL 永远是 5 分钟。
Claude.ai 网页聊天:官方没有明确的公开记录。其行为可能与订阅版类似,但这一点尚未得到完全确认。
几个月前,曾有不少用户抱怨 Claude 订阅额度消耗过快。当时有一种猜测,认为是 Anthropic 悄悄将 TTL 从 1 小时降到了 5 分钟,且未通知用户。但事实并非如此,Claude Code 的 TTL 仍然是 1 小时。
问题在于,Claude Code 和 Claude API 的文档是分开的,而这两者本来就是不同的产品,因此造成了不少混淆。
如果你在大量运行 Sub-agent 工作流,或者直接使用 API,那么 5 分钟这个数字就非常重要。但对于 95% 的 Claude Code 用户来说,真正需要关注的,其实是那个 1 小时的窗口期。
覆盖 95% 用户的三个关键习惯
下面这些建议,是日常使用中真正具有实操价值的部分。
不要暂停太久
如果你的会话已经空闲超过一个小时,那么之前缓存的内容基本都已经过期了。你的下一条消息会触发系统重新构建缓存。在这种情况下,与其强行恢复一个已经“冷却”的旧会话,不如做一次清晰的交接总结,然后开启一个新会话,成本效益通常更高。
切换任务时,直接重新开始
使用 /compact 或 /clear 命令本身就会破坏现有缓存,因此不如利用这个节点进行一次彻底的重置。
一个实用的技巧是制作一个“会话交接”技能。它可以用来替代 /compact 命令。这个技能会总结我们已经完成了什么、还有哪些待定决策、哪些文件最重要,以及接下来应该从哪里继续。然后执行 /clear 命令,并把这份总结粘贴进去,就可以像从未中断一样继续推进工作。
相比之下,/compact 命令有时运行得也比较慢。而这个交接技能通常在一分钟内就能完成。
在 Claude 聊天中,大文档尽量放进 Projects
Claude.ai 网页版的缓存机制虽然没有非常详细的官方说明,但 Projects 功能显然与普通的对话线程采用了不同的优化策略。因此,如果你需要粘贴很大的文档,最好把它们放进 Project 里,而不是直接塞进对话中反复处理。
哪些操作会悄悄破坏缓存?
有几件事会在没有明显提醒的情况下,导致缓存被全部重置。
切换模型:因为缓存依赖前缀匹配,而每个模型都拥有自己独立的缓存空间。只要切换了模型,下一次请求就会在没有任何缓存命中的情况下,重新读取完整的历史对话。
“Opus plan”模式:这个设置会在规划阶段使用 Opus 模型,在执行阶段使用 Sonnet 模型。此前在一些 Token 优化指南中推荐过它,这有其原因。但需要理解的是,每一次执行计划的切换,本质上都是一次模型切换,也就意味着要重新建立缓存。从长期会话来看,它仍然有助于延长额度,但你需要清楚底层到底发生了什么。
关于编辑 CLAUDE.md:在会话中途编辑 CLAUDE.md 文件是可以的。这个修改不会立即生效,而是要等到下一次项目重启时才会应用。因此,当前正在运行的会话缓存不会受到影响。
一个查看 Token 使用情况的仪表盘
前文展示的截图,来自一个第三方的 Token 使用仪表盘。
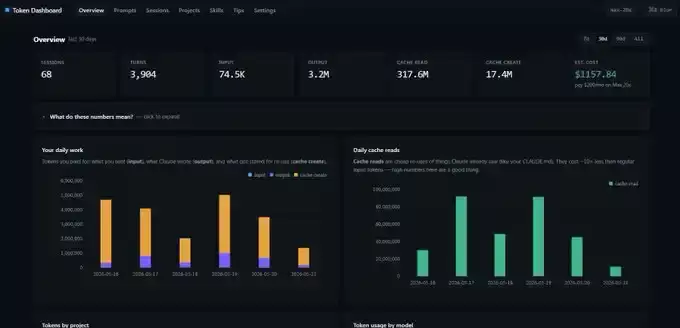
这是一个托管在 GitHub 上的开源项目。你可以将仓库链接交给 Claude Code,让它在本地 localhost 上完成部署。部署后,它会读取你过去所有的会话记录进行分析,而不是从零开始统计。这样一来,你一开始就能看到每天详细的 input、output、cache create 和 cache read 数据。
不过需要注意一点:这个仪表盘统计的是本地设备上的 Token 数据。如果你从台式机切换到笔记本使用,数字就不会完全一致。每台设备都会生成自己独立的一套统计视图。
总结
Prompt caching 是一个可以深入研究的话题。Thariq 的相关文章讲得比这里更全面,如果你想了解全貌,值得一读。
但你并不需要完全理解所有细节才能从中受益。掌握最关键的 80/20 原则就足够了:缓存 Token 比普通 Token 便宜 10 倍;Claude Code 的缓存 TTL 是 1 小时;切换模型会破坏缓存;在任务之间做好清晰交接,通常比让一个旧会话放到“过期”后再硬接着用更划算。
相关攻略

Anthropic (ANTH PVT):2025年,它会成为下一个OpenAI级别的AI巨头吗? 在全球人工智能的竞赛中,Anthropic (ANTH PVT) 的崛起速度堪称现象级。这家由前OpenAI核心成员创立的公司,已从一家专注于AI安全的研究型初创企业,迅速蜕变为全球估值最高的私营科技

最近科技圈有个动向挺有意思:AI公司自己,正在花大价钱招人“写文章”。 科技媒体Business Insider日前报道,明星AI公司Anthropic正在扩招一批高薪写作岗位,核心目标很明确——强化品牌叙事和市场沟通。说白了,就是得有人能把那些复杂的技术术语和产品能力,掰开揉碎了,转化成普通人、甚

最近,Anthropic在一轮融资中展示的数据,让市场看到了AI模型层盈利路径的清晰信号。根据其向投资者披露的预测,公司一季度营收达到48亿美元,二季度预计将跃升至109亿美元,并在6月当季有望实现5 59亿美元的运营利润。更关键的是其成本结构的变化:一季度,每赚1美元,就要在算力上投入71美分;到

Anthropic与DeepMind负责人预测超级智能临近,分别预计2028年AI将实现自我改进、2030年出现通用人工智能。双方一致认为AI将百倍于工业革命的影响力重塑社会,人类仅剩约三年准备应对巨变。

AI领域领军人物近期发出紧迫警告。Anthropic联合创始人预测,AI可能在2028年底实现递归自我改进,届时将能自主设计更强AI。DeepMind负责人则评估,通用人工智能或于2030年前后降临,其冲击强度与速度可能是工业革命的百倍。两人均指出,AI进化已超越社会适应阈值,留给人类调整的时间窗口可能仅剩三年左右。
热门专题







热门推荐

水产市场是什么 在AI Agent的生态中,能力共享与协同进化是核心驱动力。水产市场(Seafood Market)正是为OpenClaw框架量身打造的AI Agent能力共享平台。你可以将其理解为AI领域的“应用商店”或“技能交易中心”,旨在实现AI能力的快速流通与组合创新。 目前,平台已集成超过

在信息爆炸的时代,高效地将音视频内容转化为可编辑、可检索的文字,已经成为内容创作者、研究者和职场人士的刚需。今天要聊的这款工具——MeowTXT,正是瞄准了这一痛点,它不仅仅是一个简单的转录工具,更是一个集成了智能识别、摘要和翻译的AI生产力平台。 MeowTXT是什么 简单来说,MeowTXT是一

OpenFang是什么 在AI Agent领域,我们常常面临一个困境:大多数系统仍然停留在“你说一句,它动一下”的被动模式,离真正的自动化还有距离。今天要聊的OpenFang,正是在尝试打破这个局面。它是一个用Rust语言构建的开源Agent操作系统,其核心创新在于引入了“Hands”的概念——你可

AngelSlim是什么 随着大模型参数规模不断增长,如何实现高效推理与低成本部署已成为开发者面临的核心挑战。腾讯混元团队推出的开源工具包AngelSlim,正是为解决这一难题而生。它是一个面向全模态大模型的综合压缩与加速解决方案,集成了量化、投机采样、稀疏化及知识蒸馏等前沿技术,旨在为各类大语言模

在信息过载的数字化时代,音频与视频内容已成为知识传递、创意表达与商业沟通的核心载体。然而,如何将这些宝贵的非结构化媒体资产,高效、精准地转化为可搜索、可分析、可编辑的文本格式,始终是内容创作者、市场研究人员、学者及商务人士的核心痛点。一款强大的AI转录工具,正是打通音视频内容价值闭环、释放生产力潜能