今天,资本市场因一项大模型核心技术指标而沸腾。
被誉为“全球大模型第一股”的智谱(股票代码:02513.HK)股价再度强势拉升,盘中涨幅一度突破30%。截至收盘,股价报1282港元,单日涨幅超过26%,公司市值攀升至5715.7亿港元,创下历史新高纪录。
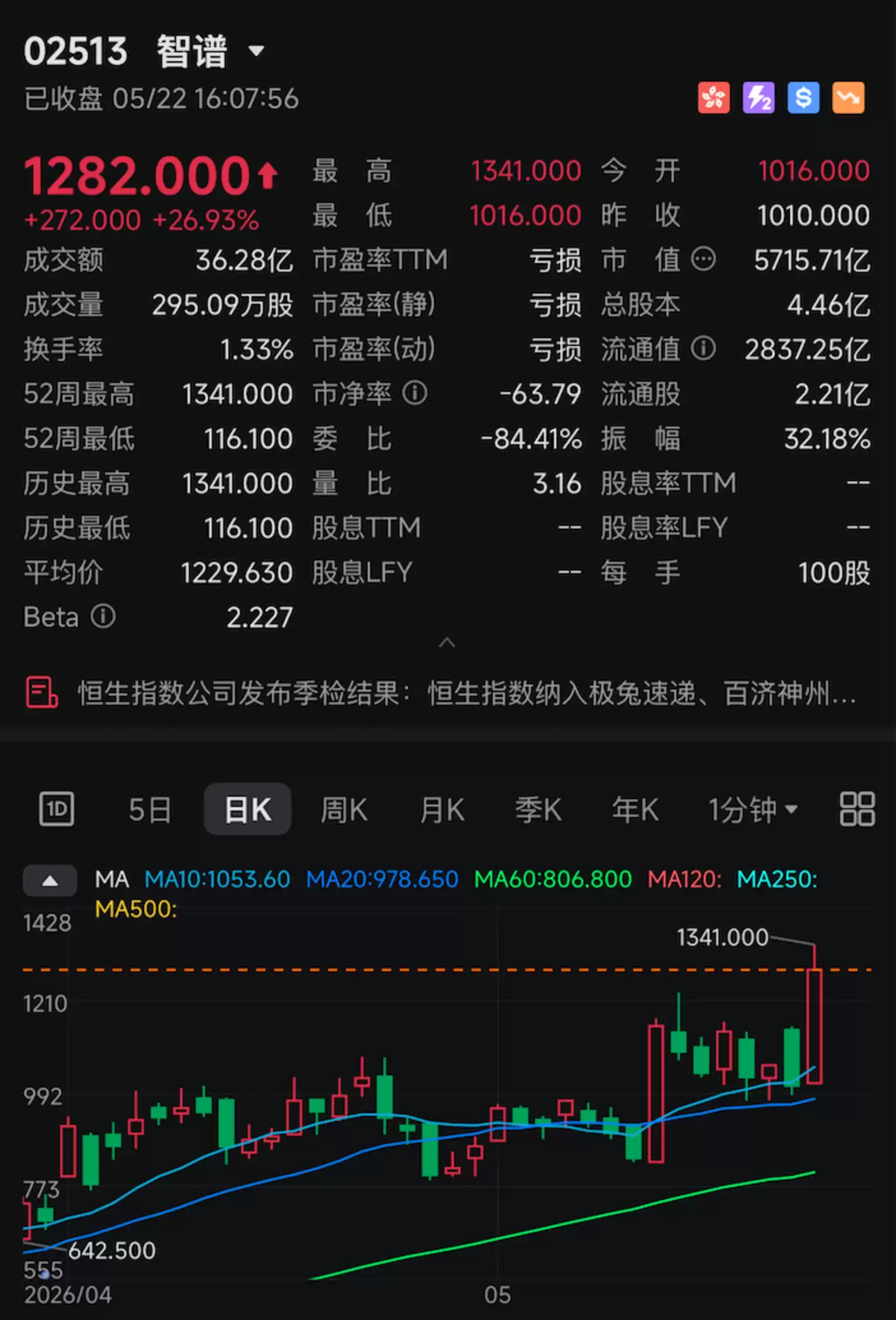
点燃这场资本行情的,是一个看似具体甚至有些枯燥的技术参数:每秒400个token。
就在5月22日,智谱正式面向企业客户开放了GLM-5.1高速版API接口服务。其核心宣传卖点极为聚焦:模型输出速度达到每秒400个token,一举刷新了全球大模型厂商API服务的速度上限。
起初,这很容易被视作又一次技术营销事件。但深入剖析其背后的技术细节便会发现,资本市场的热烈反响并非没有依据。这个数字,很可能正在重新划定AI行业下一阶段竞争的焦点。
每秒400个token究竟意味着什么?
将其换算为更直观的文字产出,大约相当于每秒生成200个汉字。这意味着,一位专业作家需要伏案一分钟高强度输出的文字量,如今被压缩至一秒钟之内。过去需要数天才能完成的文稿创作,或是工程师埋头数日才能搞定的代码重构任务,在AI的辅助下,现在可能只需一杯咖啡的时间便能产出初稿。
01 速度,比你想象的更重要
在过去三年的大模型军备竞赛中,“速度”这一维度常常被忽视。行业的聚光灯始终聚焦于两条主赛道:一是参数规模,追求模型更大、更智能;二是成本价格,追求每个token更便宜、更普惠。而“响应速度”,似乎从未站上舞台中央。
这背后存在一个固有认知:以往的“快”,往往是通过牺牲模型核心能力换取的。想要提速?通常意味着采用更小、更精简的模型架构,代价则是性能的显著缩水。因此,速度与模型能力长期被视为鱼与熊掌,难以兼得。
GLM-5.1高速版此次的关键突破在于,它打破了这种传统的性能权衡。在完整保留其旗舰级基座模型全部能力的前提下,将文本生成速度推向了每秒400个token的峰值。无论是置于国产大模型还是全球视野中审视,这都标志着“旗舰级智能”与“极致低延迟”首次实现了真正意义上的并存,无需妥协。

为什么推理速度突然变得如此关键?根本原因在于,AI应用的核心战场正在发生深刻迁移。
当人工智能从简单的问答聊天机器人(ChatBot)阶段,演进至智能体(Agent)时代,交互模式发生了根本性变革。一个智能体要完成一项复杂任务,往往需要模型进行数十轮甚至上百轮的自我规划与调用:任务分解、代码编写、API调用、信息检索、工具使用……这是一个环环相扣的链式协作过程。
在这种新型工作模式下,每一轮调用之间的延迟会被无情地累积放大。试想一个需要50轮调用的复杂任务,如果每轮交互能节省1秒延迟,整个任务的完成时间就能快上近一分钟。对于实时语音交互、AI编程助手或高频商业决策系统而言,这种时间差距直接决定了用户体验的优劣,甚至关乎产品的市场成败。
从更深层次看,在固定的时间预算内,更快的推理速度意味着模型能够探索更深的思维路径,进行更多轮次的自我验证与纠错。速度,正从一个纯粹的系统性能指标,演变为直接影响模型智能上限的关键因素之一。
02 提升速度,究竟有多难?
那么,当前行业主流的大模型推理速度水平究竟如何?
国际头部厂商中,OpenAI的GPT-4o大约在每秒100到150个token,Anthropic的Claude Sonnet系列则在每秒80到120个token区间。国内主流旗舰模型的API响应速度,大多落在每秒50到100个token的范围内。相比之下,400 tokens/s的速度,达到了行业平均水平的3到5倍之多。
更为关键的是,这种速度差距并非简单地通过堆砌更多算力就能轻易弥补。这背后存在一个巨大的“效率鸿沟”。
从纯理论计算能力分析,一台搭载8块顶级H200 GPU的服务器,其每秒的数据吞吐能力高达38TB。对于GLM-5.1这类模型,生成单个token大约需要读取42GB的激活参数。理论上,这套系统逼近每秒1000个token也并非天方夜谭。
但现实情况是,许多现有系统实际只能跑出每秒几十个token的速度。瓶颈究竟在哪里?
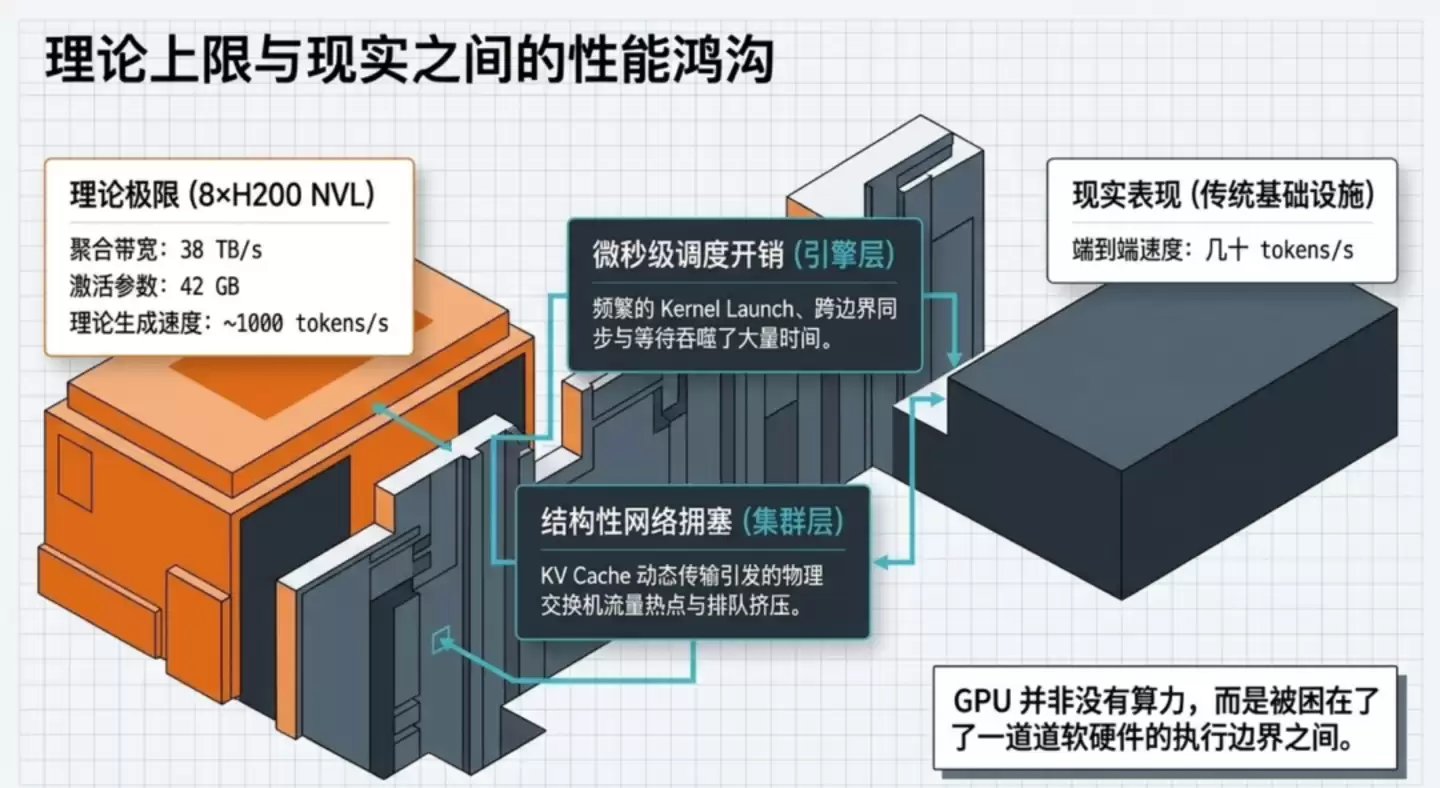
GPU本身的原始算力往往并非瓶颈,大量时间其实被浪费在了等待、空转和低效的系统调度上。这就像一辆拥有顶级发动机的超级跑车,却因为变速箱和传动系统效率低下,始终无法发挥其全部潜力。
智谱此次实现突破的核心,正是在于从推理引擎、并行计算策略到底层网络架构这三个层面进行了系统性协同创新,从而有效地填平了这道效率鸿沟。
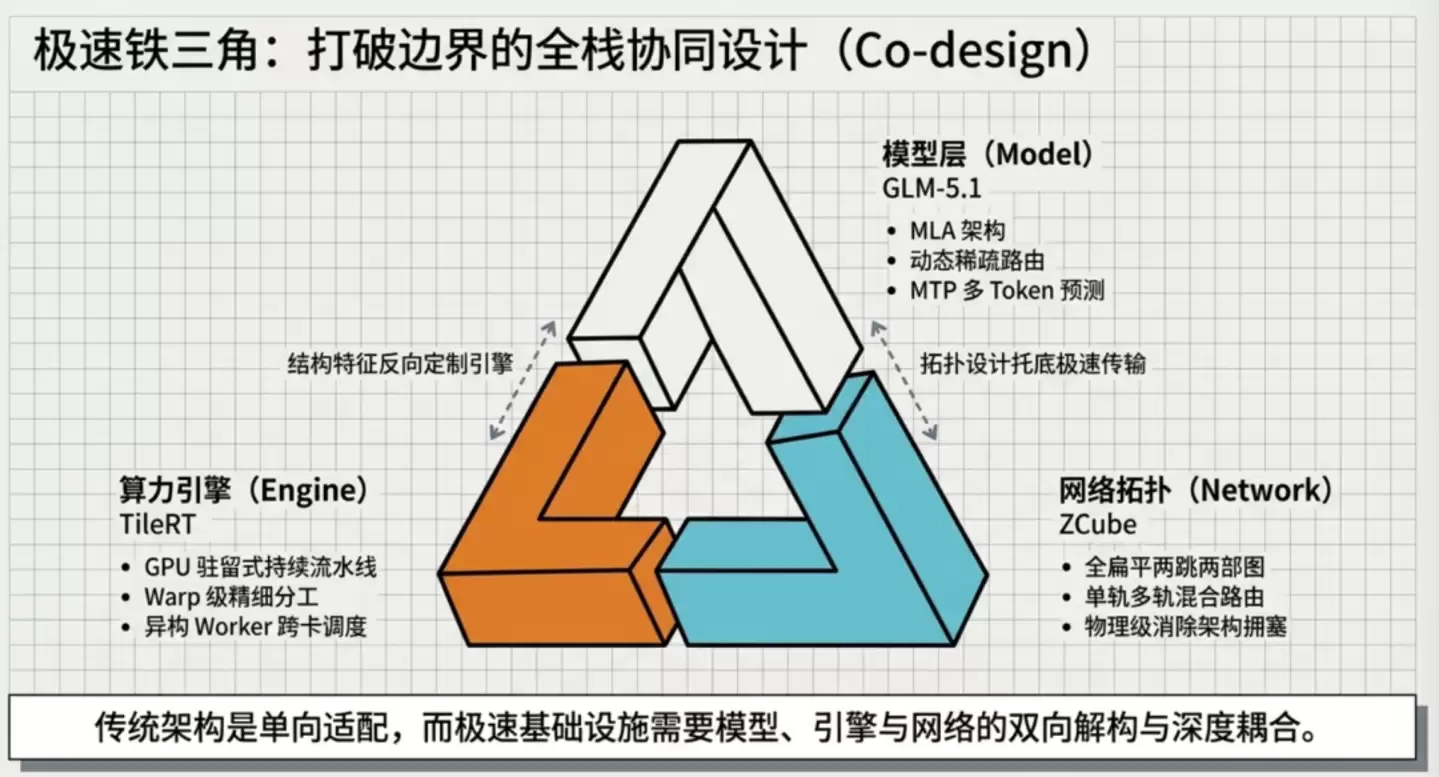
03 三层技术叠加,逼近硬件物理极限
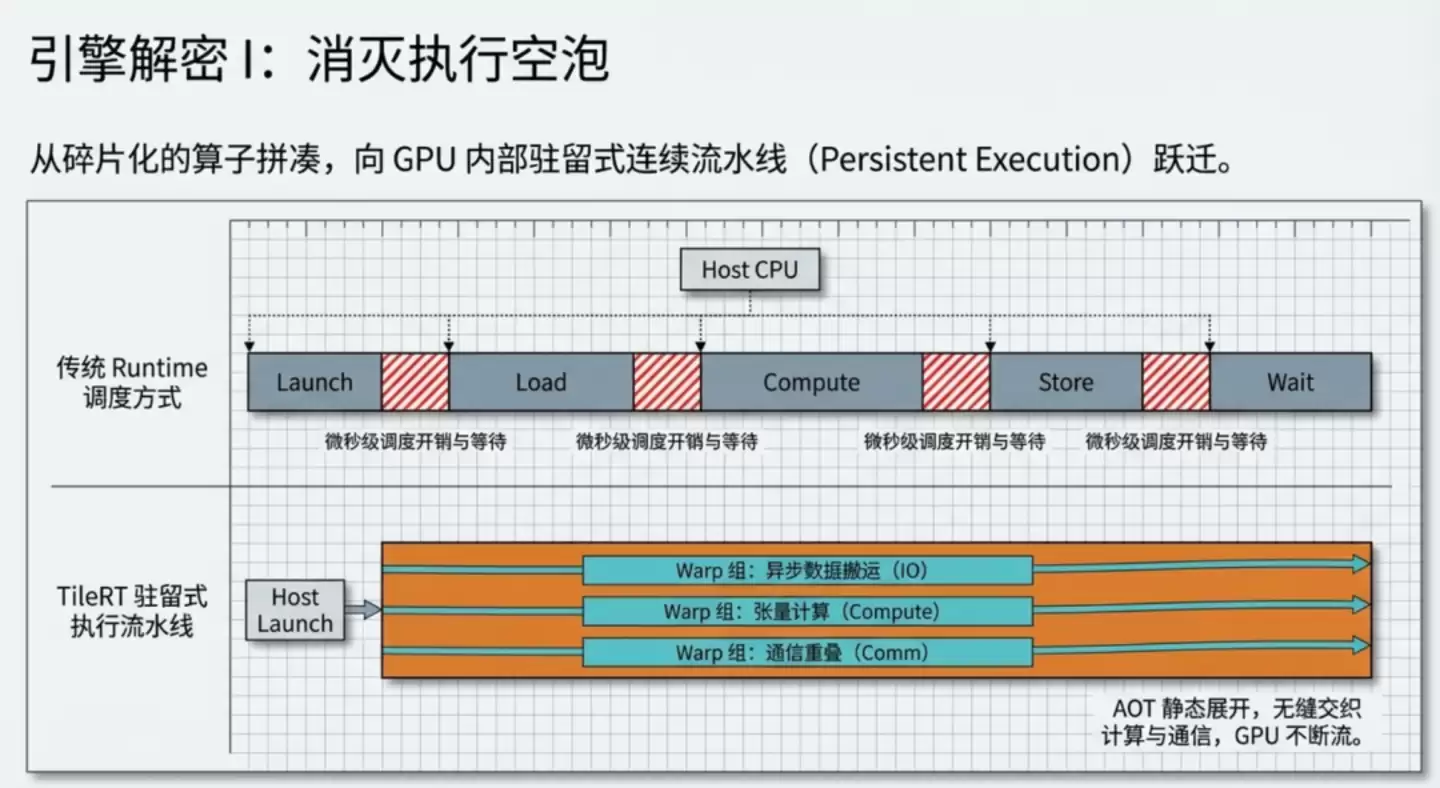
要理解这场效率革命,首先需要了解传统大模型是如何工作的。通常,模型计算被分解成一个个独立的“算子”,每个算子启动一次计算核心,算完后便停止,等待同步,再启动下一个。在模型训练阶段,每次计算动辄耗时数秒,这种启动开销尚可忽略。
但到了推理生成阶段,尤其是生成单个token时,关键计算步骤可能只需要几十微秒。此时,启动和等待的开销占比就变得非常可观,成了拖慢整体速度的主要瓶颈。
智谱自研的TileRT推理引擎,其核心思路正是彻底改变这种“走走停停”的间歇模式。它的做法是在代码编译阶段,就将整个模型的计算逻辑图静态展开,编译成一条持续运行、高度优化的计算流水线。运行时,GPU始终保持高速运转状态,计算、数据搬运、通信等操作并行推进,中间结果尽量驻留在GPU内部的高速缓存中,避免反复读写慢速的显存。简而言之,实现了从“频繁启停的班车”到“永不停歇的高速列车”的模式转变。
这其中,一项名为“Warp专门化”的设计至关重要。要理解它,需先了解GPU的基本工作原理。与CPU不同,GPU内部集成了成千上万个简单的计算单元,它们以32个为一组捆绑行动,这个组被称为“Warp”。同一个Warp内的所有单元必须同步执行完全相同的指令。
在传统计算框架中,所有Warp都执行同一套指令序列。而TileRT则创新性地让不同的Warp组承担起专门化的职责:一部分Warp专门负责预取数据,一部分专攻核心数学计算,另一部分则负责与其他GPU进行通信。三组“专业团队”同时工作,形成高效的流水线作业,互不等待。这就好比将建筑施工从“一个工人搬砖、砌墙、验收轮流干”,升级为“搬砖组、砌墙组、验收组协同并行”的现代化工程模式。
解决了单卡内部的效率问题后,多卡并行又带来了新的挑战。行业通行做法是采用“张量并行”,即将模型的权重矩阵切分到多张GPU上,各自计算部分结果后再汇总。这套方案对于矩阵乘法这类规整运算非常有效,是目前的主流并行策略。
但GLM-5.1所采用的注意力机制是MLA(多头潜在注意力)。这种机制有一个显著特点:它能将传统注意力机制中需要大量存储的中间状态(KV Cache)压缩成紧凑的“潜在向量”,从而显著节省显存、提升计算效率。然而,MLA的计算流程中包含一个特殊的“稀疏索引”环节——这类似于需要快速从一个庞大的图书馆中精准找出最相关的几本书。
“找书”(即稀疏索引)这个步骤高度依赖全局信息,不适合平均分摊到多张GPU卡;“精读”(即后续的密集计算)才适合并行处理。如果强行让所有8块GPU都参与“找书”过程,大量时间将浪费在卡间通信和同步等待上。
TileRT引擎的解决方案是采用“异构并行”策略。它让GPU 0扮演专门的“图书馆检索员”角色,负责全局的稀疏索引和路由决策;而GPU 1到7则作为“精读分析员”,专注于后续的密集计算任务。两类处理器采用最适合各自任务特性的并行策略,高效协同完成整个计算层的处理。
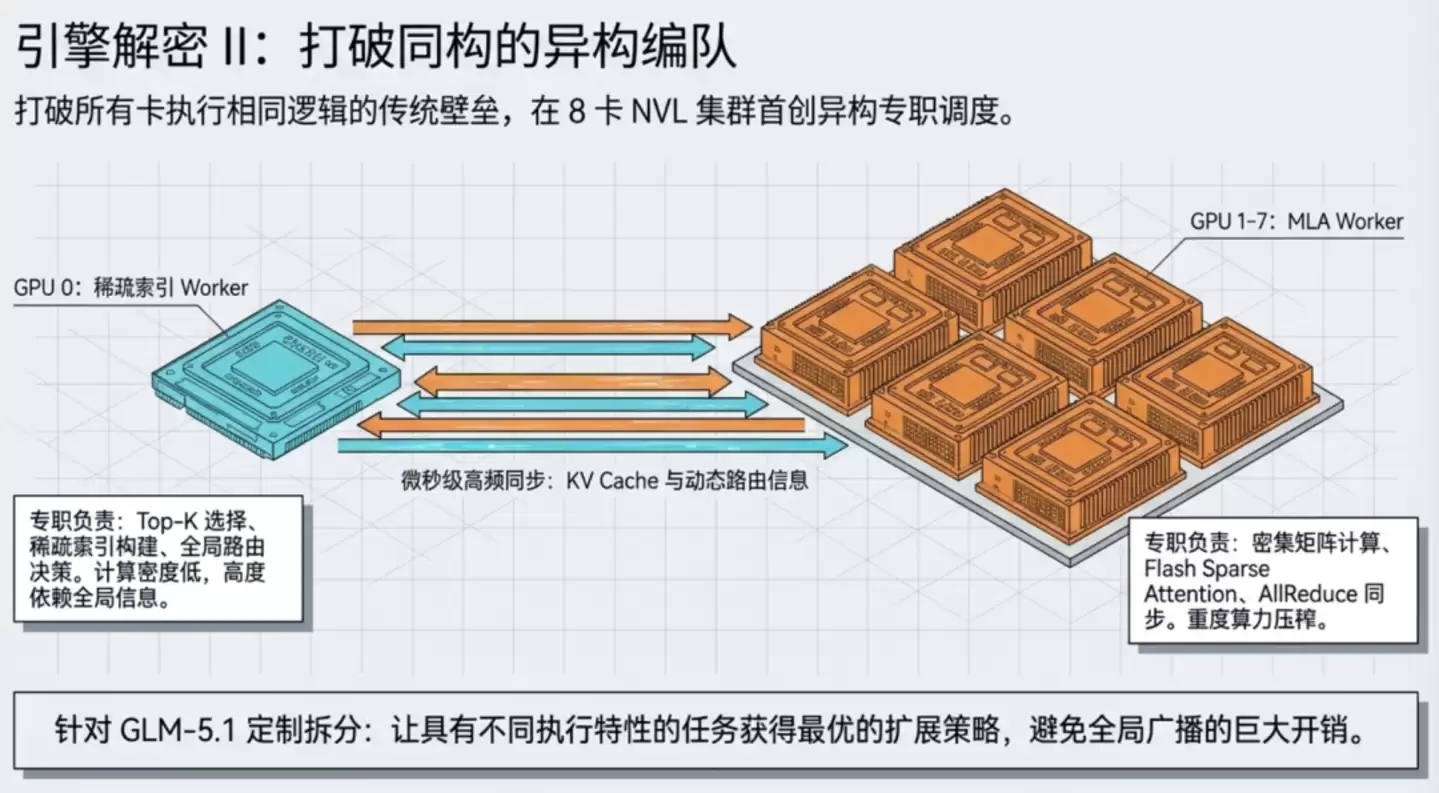
更进一步,TileRT还将GPU之间的通信操作直接内嵌到执行流水线之中,不再将其作为独立的步骤进行处理。从外部视角看,整个8卡系统完成一层注意力计算,只需要一次内核启动,内部的所有通信和计算都在持续流动的流水线内无缝衔接完成。
这场由400 tokens/s引发的股价暴涨,本质上是一次清晰的市场投票。它明确地表明,当大模型的基础能力达到一定门槛后,行业竞争的焦点正在从“模型能做多好”转向“模型能做多快”。推理速度,这个曾经隐藏在后台的性能指标,正在快步走向舞台中央,成为定义下一代AI应用体验与商业价值的关键变量。




