就在整个AI社区热切期待DeepSeek-V4正式发布的关键时刻,一项突破性的研究成果横空出世,迅速成为技术圈热议的焦点。这项研究提出了一种名为HISA(分层索引稀疏注意力)的全新机制,精准地瞄准了当前大型语言模型在处理长上下文任务时面临的核心效率瓶颈——索引计算开销过大。根据论文公布的实验数据,在处理高达64K长度的上下文时,HISA相比DeepSeek当前采用的DSA(DeepSeek稀疏注意力)索引机制,能够实现最高2至4倍的显著速度提升。

更为关键的是,这种性能的飞跃并非以牺牲模型精度为代价。实验验证表明,HISA在几乎完全保持模型原有精度的前提下,实现了“即插即用”的便捷部署,无需对预训练模型进行任何额外的重新训练或微调。
研究团队直接在DeepSeek-V3.2和GLM-5这类主流大语言模型上,替换了原有的注意力索引模块,跳过了复杂的微调步骤。在关键信息检索、长文档问答、多轮对话理解等一系列核心评测任务中,模型的精度表现均与原方法基本持平,甚至在某些场景下略有提升。
两步走策略,彻底解决长上下文索引瓶颈
这篇论文的目标非常明确:为当前大模型广泛采用的稀疏注意力机制,设计一个更高效、更智能的“检索引擎”。
以DSA为代表的token级稀疏注意力机制,其核心原理是通过只计算与少数关键token相关的注意力权重,从而大幅降低模型的计算复杂度。然而,这一设计背后隐藏着一个效率陷阱:为了精准筛选出这些关键token,模型需要一个“索引器”来为当前查询的每一个token,与历史上下文中所有token逐一计算相关性得分,再从中选出得分最高的部分。
问题的症结正在于此。当输入文本长度L急剧增加时,这个逐对打分的计算量会呈平方级(O(L²))增长。这意味着文本长度翻倍,索引计算的开销可能激增至四倍。在处理128K甚至1M级别的超长文本时,索引器的计算成本甚至会反超核心的注意力计算本身,成为制约模型推理速度的主要性能瓶颈。
因此,研究团队提出了一个核心问题:能否在不改变最终稀疏注意力结果质量的前提下,大幅降低索引器的搜索成本?
HISA的诞生正是基于这一思路,其核心逻辑清晰而高效:既然对每个token进行全局搜索过于耗时,那么就采用“先粗筛,后精查”的两步走策略。首先按“块”快速过滤掉大量无关内容,再在缩小的候选范围内进行精细的token级筛选。
这种方法在功能上实现了对原有索引模块的完全等价替换,无需改动后续的注意力计算流程。可以将其形象地理解为“更换了一个效率更高的筛网,但筛选出的精华颗粒几乎完全相同”。
具体操作流程分为两个步骤,全程复用原模型的打分函数,无需引入任何新的可学习参数:
第一步,块级粗过滤。 将超长文本序列切割成固定大小的“token块”(例如每块包含128个token),并为每个块计算一个具有代表性的“整体特征向量”(相当于为每块内容生成一个摘要标签)。接着,使用原索引器的打分规则,仅对这些块级别的特征向量进行快速打分。然后,筛选出分数最高的m个候选块(例如64个),其余低分块则被直接排除。由于块的数量远少于token总数,这一步能高效过滤掉绝大部分不相关的内容,节省大量计算资源。
第二步,块内精挑token。 仅在第一步选出的m个高相关性块内部,使用原索引器的规则对单个token进行精细化的二次打分,并最终选出全局最相关的k个关键token。
此外,研究团队还引入了一个巧妙的工程优化:强制保留输入文本的第一个块和最后一个块。这一设计确保了开头的背景设定信息和结尾的最新上下文内容不会被误筛,同时也更好地处理了文档拼接或对话延续时的边界连贯性问题。
HISA的核心优势主要体现在两个方面:计算复杂度的显著降低,以及卓越的工程部署友好性。
从计算复杂度分析,HISA成功将原索引器每层O(L²)的计算成本,降低到了O(L²/B + L×m×B)(其中B是块大小,m是选取的块数)。上下文长度越长,块级粗过滤的效果越精准,其带来的加速比也就越显著。
从工程落地角度看,它的优势更为突出:首先,其输出格式与原索引器完全一致,下游的注意力计算模块无需进行任何适配性改动;其次,无需对预训练模型进行重新训练,也无需调整复杂的KV缓存结构,可直接替换原有索引器;最后,它具有智能自适应性,在处理短文本时会自动“退化”为原生的逐token索引方法,仅在处理超长上下文时才动态激活分层筛选机制,实现效率与精度的最佳平衡。
实测性能:速度飞跃,精度无损
论文在DeepSeek-V3.2和GLM-5两大主流开源模型上进行了全面而严格的测试,结果表现卓越。
在推理速度方面,在64K标准文本长度下,HISA相比原版DSA索引器最高实现了3.75倍的惊人提速,在常规参数设置下也能稳定达到2倍以上的加速效果。
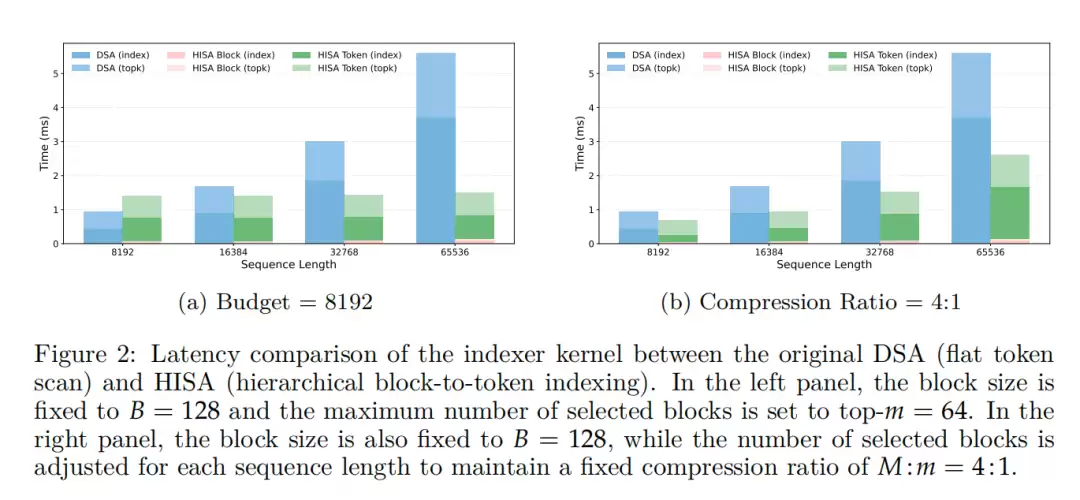
值得关注的是,输入上下文长度越长,HISA的提速优势越明显。这一特性完美契合了当前大模型向128K、1M乃至更长上下文窗口发展的实际应用趋势,为超长文本处理提供了可行的效率解决方案。
在模型精度方面,HISA也几乎完全保留了原DSA方法的精度水准,并且显著优于简单的块稀疏注意力方法。研究团队进行了经典的“大海捞针”测试,用于评估模型在超长无关文本中精准定位并提取关键信息的能力。结果显示,HISA与DSA的检索精度曲线几乎完全重合,在各种文本长度和关键信息插入深度下,其检索准确率都接近DSA的近乎满分水平。

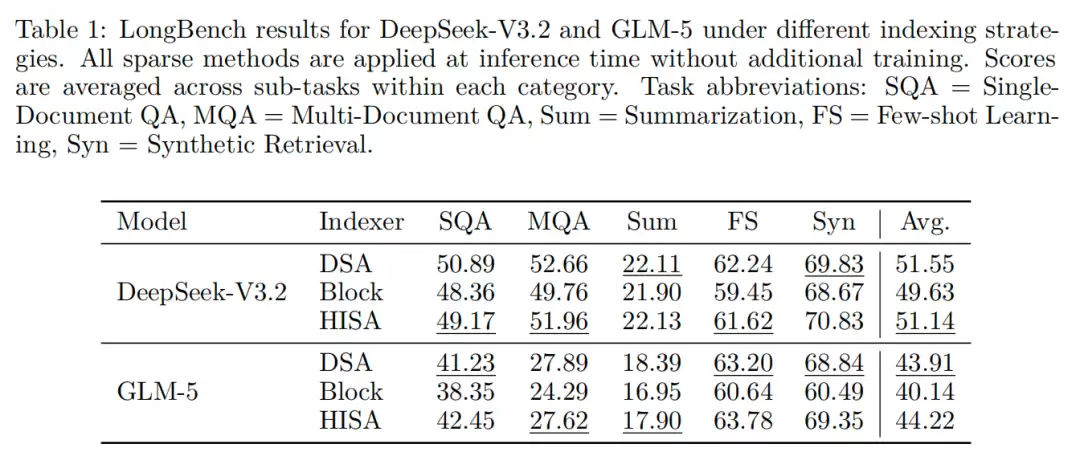
在更全面的长文本理解任务(基于LongBench基准)上,HISA的综合得分也与DSA基本持平。甚至在部分对token级筛选精度要求极高的场景,如合成信息检索、少样本学习等任务中,HISA的表现出现了小幅反超,展现了其潜在的优势。
在超参数鲁棒性测试中,无论块大小(B)和选取块数量(m)如何变化,HISA的性能表现都相当稳定,其评测分数始终与DSA基线高度接近,未出现显著的性能波动或下降。
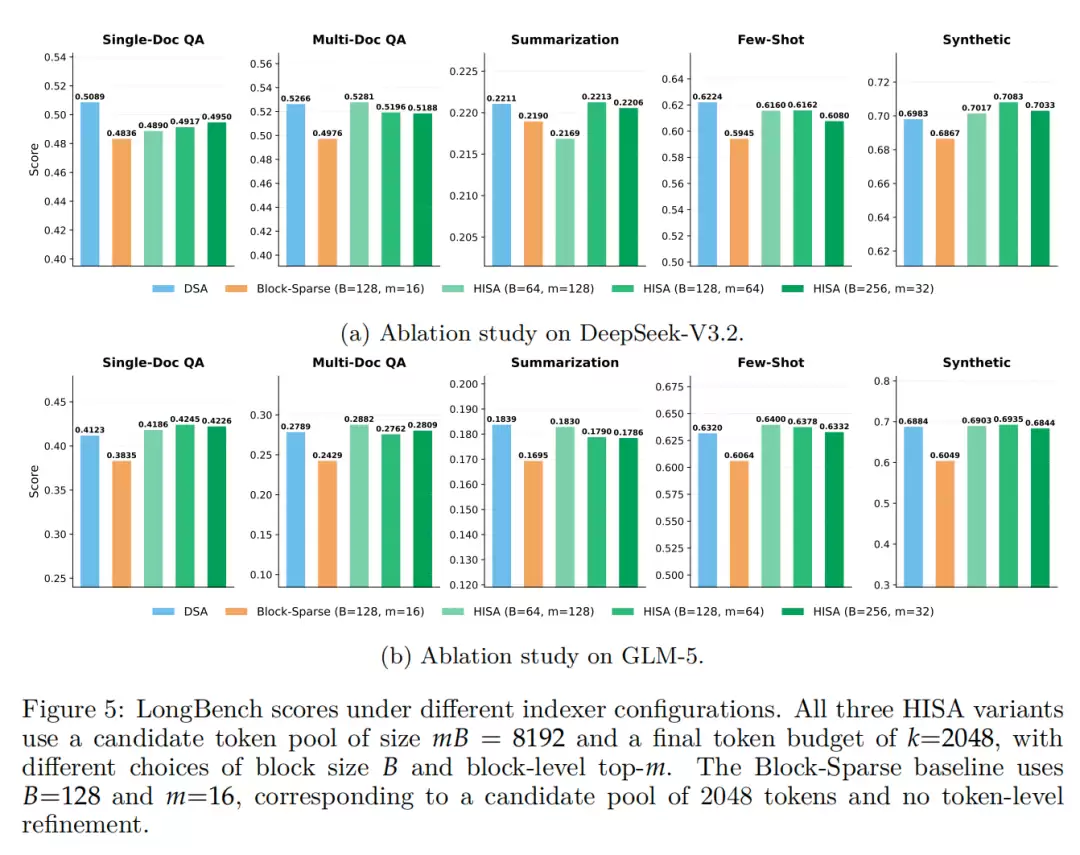
这充分说明HISA对超参数的选择并不敏感,具有极强的鲁棒性,在实际工程部署时无需进行精细且耗时的参数调优,降低了使用门槛。
当然,目前HISA也存在一些可以继续探索的优化方向,作者在论文中也展望了后续的改进思路:首先,当前采用固定大小的文本块,若一个块内同时包含高度相关与完全无关的内容,其“整体特征向量”的准确性会受到影响。未来可探索自适应块大小、重叠块或更先进的块特征聚合计算方式。其次,目前HISA仅在推理阶段直接应用,未来可以考虑将块筛选机制与模型预训练过程相结合进行联合优化,以进一步提升筛选的精准度。最后,当前测试主要聚焦于索引器模块本身的加速比,未来需要将其整合到完整的大模型服务框架中,测试端到端的请求吞吐量和响应延迟等实际业务指标。
团队背景
这篇重磅论文来自北京大学的张牧涵研究团队。张牧涵博士是北京大学人工智能研究院的Tenure-track助理教授和博士生导师。在回国加入北大之前,他曾在Facebook AI Research(现Meta AI)担任研究员,长期致力于大规模图学习系统、图神经网络及其相关核心算法的前沿研究。

根据Google Scholar最新数据,其发表的学术论文总引用量已超过13000次,其中两篇一作文章的引用量分别达到3100+和2400+次,并连续多年入选Elsevier发布的全球前2%顶尖科学家(生涯影响力榜单),在人工智能领域享有较高的学术声誉。本论文的共同第一作者是Yufei Xu(徐宇飞)和Fanxu Meng(孟繁续)。