生成式AI的竞争焦点,正从静态图像快速转向动态视频领域。如果说2024年仍是文生图模型主导市场,那么从2024到2025年,高保真视频生成技术无疑迎来了关键的“爆发拐点”。在这场变革中,谷歌推出的Veo模型正成为行业标杆——它不仅能够生成电影级别的1080p高清视频,更通过与多模态大模型Gemini的深度协同,将AI视频创作从基础的“指令执行”升级为有“智能导演”参与的全局创意编排。

本文将深入解析Veo的核心技术架构,探讨Gemini如何为创意流程注入灵魂,并展示开发者如何通过Vertex AI平台,将这套前沿的视频生成技术转化为实际的生产力工具。
视频生成技术的演进:从生成对抗网络到潜在扩散模型
要理解Veo的突破性,首先需要厘清它解决了哪些行业痛点。早期的视频生成主要依赖生成对抗网络(GAN)。这类模型生成速度虽快,却存在一个根本性缺陷——“时序闪烁问题”。具体表现为,视频中的人物或物体在帧与帧之间会出现不连贯的形变或抖动,严重影响观感。
Veo选择了一条更具挑战但效果更优的技术路径:潜在扩散模型(LDM)。其核心创新在于,不再将视频视为一系列连续的二维图片,而是将其作为一个三维的体积数据(高度×宽度×时间)进行处理。更重要的是,Veo的扩散过程发生在经过压缩的“潜在空间”内,而非直接处理海量的原始像素数据。这就像是在一张精密的蓝图基础上进行创作,而非直接堆砌砖块,从而在生成高分辨率内容的同时,显著降低了计算成本。
协同增效:Gemini作为语义理解桥梁
过去,视频生成模型最常被诟病的问题之一是“提示词误解”。例如,用户输入“一个雨夜,新黑色电影风格下,机器人在东京街头喝咖啡的电影镜头”。模型可能只捕捉到“机器人”和“街头”,却完全丢失了“新黑色”风格特有的高对比度光影和“雨夜”的潮湿氛围感。
这正是Gemini发挥关键作用的地方。它扮演的远不止是“翻译官”的角色。当接收到用户请求时,Gemini会进行深度的语义理解和创意扩展:它将一段模糊的文本描述,拆解并转化为一系列专业的影视制作指令——例如,应使用何种色调的灯光、摄像机应如何运动、焦距参数该如何设定。然后,它将这些高精度的“条件控制信号”精准地传递给Veo。可以说,Gemini让Veo从一个被动执行的画师,转变为一个能理解导演意图的创意合作伙伴。
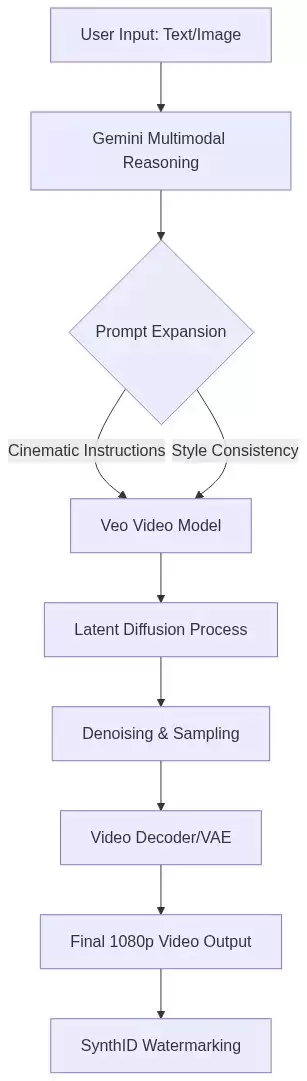
深入解析Veo技术架构
那么,Veo自身是如何确保视频在长时间序列中保持高度一致性的呢?这背后是多项核心技术的协同作用。
时空变换器
Veo的核心网络基于Transformer架构构建,但它创新性地在“空间注意力”和“时间注意力”机制之间交替工作。空间注意力负责理解单帧画面内的结构(例如一棵树或一个人物),而时间注意力则专门追踪这些元素在连续帧之间的运动轨迹。这确保了当一个角色从树后走过并被短暂遮挡后,再次出现时,其外观特征能保持严格一致,不会出现不合理的“变脸”现象。
高分辨率潜在空间
传统的扩散模型为了提升效率,通常会将图像压缩到64×64或128×128这样的低维潜在表示中,导致大量细节丢失。Veo采用了一种更先进的变分自动编码器(VAE),能够在压缩过程中有效保留皮肤纹理、毛发细节,乃至烟雾、水流等复杂流体运动的细微特征——这些正是以往AI模型最难逼真模拟的部分。
灵活的条件控制机制
Veo支持多种灵活的输入模式,以适应不同的创作需求:
- 文本生成视频(T2V):最经典的模式,通过高级语义描述驱动视频创作。
- 图像生成视频(I2V):以一张参考图像为起点或风格指南,生成动态内容。
- 视频生成视频(V2V):对现有视频素材进行风格化编辑或特定对象修改。
基于Vertex AI的集成开发流程
对于开发者而言,Gemini与Veo的集成能力通过谷歌云的Vertex AI平台变得易于调用。以下Python示例清晰地展示了如何利用SDK启动一个视频生成任务。请注意,Gemini会首先对用户的原始提示进行“编剧式”的润色和扩展,然后再交由Veo执行生成。
前提条件:一个已启用Vertex AI API的谷歌云项目,以及Python 3.9+的运行环境。
import vertexai
from vertexai.generative_models import GenerativeModel
# 注意:Veo集成具体使用Vertex AI Model Garden中的‘veo-001’或类似端点(可用性因地区而异)
def generate_cinematic_video(user_prompt):
vertexai.init(project="your-project-id", location="us-central1")
# 第一步:使用Gemini扩展提示词,以获得更佳的电影化效果
director_model = GenerativeModel("gemini-1.5-pro")
expansion_query = f"""
Convert the following basic prompt into a detailed cinematic description for a video model:
Prompt: '{user_prompt}'
Include details on lighting, camera movement (e.g., tracking shot), and atmospheric conditions.
"""
expanded_prompt_response = director_model.generate_content(expansion_query)
refined_prompt = expanded_prompt_response.text
print(f"Refined Director Prompt: {refined_prompt}")
# 第二步:调用视频生成模型(Veo)
# 这是一个基于Vertex AI视频生成SDK的概念性实现
# 待Veo API全面开放后,需替换为具体的API调用
try:
# Veo视频生成调用的占位符
# video_model = VideoGenerationModel("veo-001")
# video_job = video_model.generate_video(
# prompt=refined_prompt,
# duration_seconds=5,
# aspect_ratio="16:9",
# resolution="1080p"
# )
# video_job.wait_for_completion()
print("Video generation request sent successfully.")
return "video_output_path.mp4"
except Exception as e:
print(f"Error generating video: {e}")
return None
# 执行示例
output = generate_cinematic_video("A futuristic drone flying through a neon forest")代码逻辑解析
这段示例代码体现了两个核心设计理念:
1. 提示词工程优化:让gemini-1.5-pro扮演“智能编剧”角色。它将“无人机穿越霓虹森林”这样简单的指令,扩展为包含“变形镜头光晕、4K纹理细节和潮湿地面反光”的丰富描述。这为下游的Veo模型提供了远更精细的条件信号,直接提升了最终视频的质感与叙事性。
2. 资源与参数管理:视频生成是计算密集型任务,因此管道被设计为异步作业。客户端提交请求后即可轮询结果,无需保持长时间的同步连接等待。同时,Veo提供了对关键参数(如宽高比、时长、分辨率)的精细控制,打破了传统黑盒模型参数不可调的局限。
视频生成请求的生命周期
当一个生成请求抵达Veo API时,它并非立即开始渲染。相反,它会经历一个严谨的处理周期,以确保生成内容既高质量又安全可靠。这个过程通常包括提示词安全审核、语义解析与扩展、潜在空间扩散生成、后处理优化以及最终的内容安全与水印添加等环节。
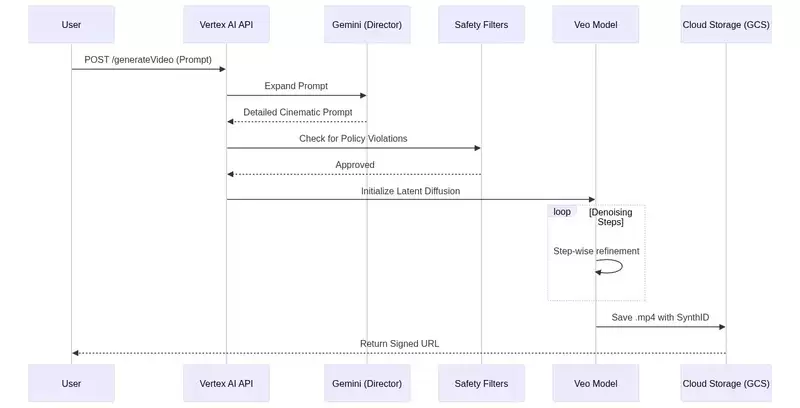
核心技术挑战与突破
在实现电影级视频生成的道路上,研发团队主要攻克了以下几大技术难题:
时间一致性与因果建模:生成单张图片时,模型无需考虑“之前”和“之后”的状态。但在生成视频时,第N帧的内容必须严格遵循第N-1帧的逻辑。Veo通过采用“因果3D卷积”技术解决了这一问题。在训练过程中,模型会被屏蔽掉“未来”帧的信息,迫使它学会仅依据“过去”的帧来预测下一帧,从而模拟出真实世界中的视觉记忆和因果逻辑。
运动控制与物理规律模拟:让AI理解并模拟物理规律,例如物体下坠的加速度、头发飘动的轨迹,是极具挑战的。Veo的优势在于其训练数据——它使用了海量的高动态范围、高清晰度的专业影视资料进行学习,从而内化了经典力学的基本法则。当提示词是“玻璃杯摔碎在大理石地面上”时,模型能够精准模拟碎片飞溅的抛物线以及石材表面瞬间的锐利反光。
SynthID:负责任AI的实践:面对深度伪造技术带来的挑战,谷歌将SynthID数字水印技术直接集成到了Veo的生产管道中。这种水印对人眼不可见,但可通过专用算法检测,即使视频被压缩、裁剪或调色,水印依然存在。这为AI生成内容的溯源和版权认证提供了关键的技术保障。
生成模式对比:文本生成视频与图像生成视频
Veo支持的两种主要模式,各有其技术侧重点和应用场景。
文本生成视频(T2V):在此模式下,模型的创作自由度最高。它需要从零开始“构思”整个场景、角色和动作。这非常适合快速原型设计、创意脑暴等需要高度想象力的场景。
图像生成视频(I2V):这种模式的技术挑战其实更大。模型被给定一张参考图像作为“先验”,它必须在严格保持主体(如人物面部)特征和背景布局不变的前提下,生成合理且连贯的运动。Veo采用了一种类似ControlNet的条件控制机制,让时空变换器在计算运动信息时,能牢牢“锚定”源图像的空间特征,从而确保了极高的视觉一致性。
开发者应用路线图
随着Veo模型能力的逐步开放,开发者若想高效利用其潜力,建议重点关注以下三个优化方向:
1. 视频提示词工程:与大型语言模型(LLM)不同,视频模型对描述空间关系、视觉属性的术语(如“前景虚化”、“背景推移”、“镜头拉近”)反应更佳,而对过于抽象概念的理解则相对较弱。精心设计和优化提示词是提升输出质量的第一步。
2. 异步交互与延迟管理:生成一段高质量视频可能需要数分钟。为应用构建健壮的异步交互界面(例如使用WebSockets或Pub/Sub进行任务状态通知)对于生产级应用的用户体验至关重要。
3. 成本优化策略:生成1080p高清视频的算力成本远高于生成文本。开发者需要通过实现缓存策略来优化资源使用,例如,为相似度高的用户提示复用已生成的视频片段,从而有效控制运营成本。
结语
Gemini与Veo的深度结合,标志着生成式媒体领域的一次重要范式转移。通过将大语言模型的深层语义理解能力,与潜在扩散模型精准的时空建模能力相融合,谷歌构建了一条能够有效弥合简单文本输入与电影级视频输出之间鸿沟的智能创作管道。
对于技术团队和创作者而言,这意味着自动化营销内容制作、动态游戏场景生成、个性化教育视频创作等广阔的应用场景正在成为现实。而这一切,是在严格遵循现代网络所需的安全与可追溯性标准的前提下实现的。这不仅仅是单一技术的进步,更是一套面向未来、负责任的内容创作新基建的雏形。