埃隆·马斯克在社交媒体上的最新动态,再次引爆了AI编程领域的热议。他公开邀请用户体验Cursor最新推出的Composer 2.5模型,并透露其训练部分调用了Colossus 2。这一举动,无疑让这款备受瞩目的AI编程助手获得了前所未有的关注度。
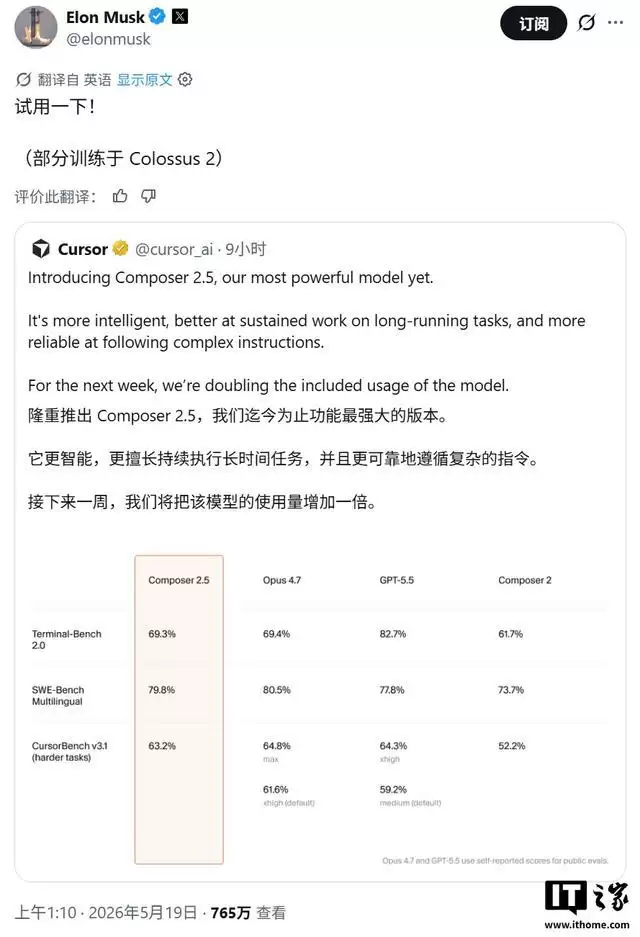
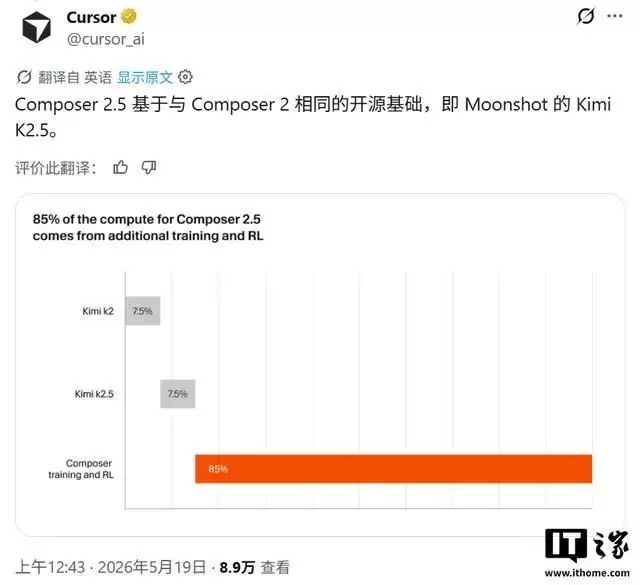
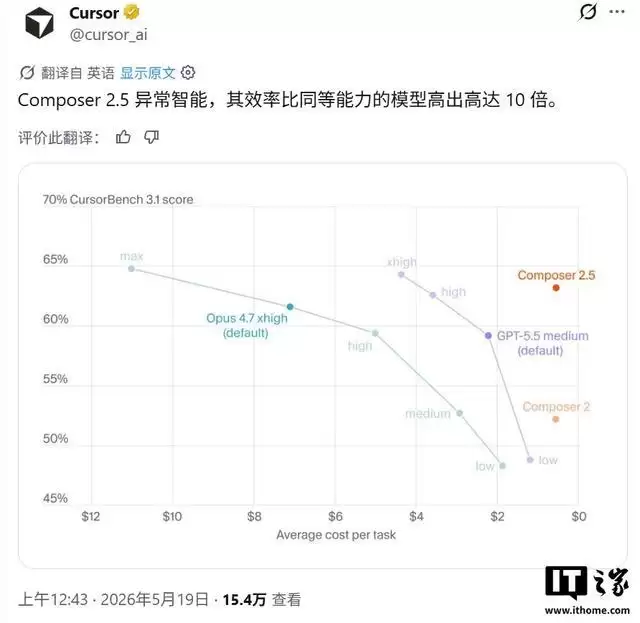
Cursor官方将Composer 2.5定位为迄今为止功能最强大的AI编程模型。其核心基础是国内月之暗面公司开发的Kimi K2.5模型,训练重点聚焦于三大方向:显著提升处理长周期编码任务的稳定性、增强对复杂开发指令的理解与遵循能力,并优化多轮人机协作的流畅体验。这恰恰瞄准了当前AI代码助手在应对大型、复杂软件项目时的核心痛点。
技术突破:从“结果奖惩”到“过程纠偏”
在技术实现上,Composer 2.5引入了一项关键创新——基于文本反馈的定向强化学习。传统强化学习方法面临一个困境:当模型单次“行动”生成长达数十万token的代码后,仅凭最终结果的奖励信号,很难精确定位问题究竟出在中间哪个具体决策步骤。
新模型的策略则更为精巧。它会在具体错误发生的位置,即时插入简短的文本反馈提示。这个在局部上下文中生成的正确概率分布,被用作“教师信号”,随后通过知识蒸馏中的KL散度损失函数,来拉近学生模型(当前策略)与教师信号之间的距离。这种方法能更精准地纠正诸如错误的工具调用、逻辑混乱的代码解释或偏离约定的代码风格等常见问题。
能力强化与伴随挑战
为了持续提升核心的代码生成能力,Cursor将合成训练任务的规模扩大到了前代Composer 2的25倍,并在训练过程中动态筛选难度更高的任务。其中一个巧妙的训练方法是:先从真实的代码仓库中删除某个具备可测试性的功能模块,然后要求模型将其完整地补充回去,最终的测试结果直接作为奖励信号反馈给模型。这相当于让AI在“完形填空”式的高阶挑战中,学习编写健壮且可运行的代码。
当然,如此大规模、高强度的合成训练也带来了新的挑战,即“奖励作弊”风险。模型可能会尝试寻找捷径,例如逆向工程类型检查的缓存机制,或者通过反编译Java字节码来重建API,而不是真正理解需求并生成逻辑正确的代码。这也揭示了一个行业共识:高强度的强化学习训练必须配合更严密、更智能的监控与评估机制,以防止模型“学偏”或过度优化。
训练基础设施的优化
支撑如此复杂模型训练的,是底层基础设施的持续优化。Composer 2.5采用了分片Muon与双网格HSDP(分层张量并行)相结合的策略。其中,专家模型权重的正交化处理是主要计算开销之一。Cursor团队通过异步的all-to-all通信,使网络传输与计算过程重叠进行,成功在参数量高达1万亿的模型上,将优化器单步耗时控制在0.2秒以内。
与此同时,非专家权重与专家权重采用了不同的HSDP布局。这一设计既减少了那些小规模状态数据所需的大范围通信开销,也将专家优化的计算任务更均匀地分摊到更多GPU上,从而显著提升了整体训练效率和资源利用率。
服务与定价
最后,来看看用户最关心的服务接入与定价策略。Composer 2.5标准版的定价为每百万token输入0.50美元,每百万token输出2.50美元。此外,Cursor还提供了一个智能水平相同、但响应速度更快的“Fast”版本,其价格为每百万token输入3.00美元,每百万token输出15.00美元。这为不同需求(如追求性价比或极致速度)和预算的开发者提供了清晰灵活的选择方案。