
让AI进入手术室,从来都不是一件可以掉以轻心的事。技术的每一次激进尝试,背后都关乎着生命的重量。
今年二月,路透社的一篇调查报道,标题就足够引人深思——《当AI进入手术室:手术失误及人体部位识别错误的报告频发》。报道指出,在美国,一些医疗设备厂商正急于将尚不成熟的AI技术整合进手术产品中,随之而来的误判案例也在增加,例如系统错误识别了人体部位,或在机器人辅助手术中间出现了本可避免的操作失误。
医疗器械厂商正争相将AI整合进其产品之中。尽管支持者坚信这项新技术将碘伏医疗领域,但监管机构收到的关于患者受伤的指控却在持续攀升。
这些直接应用于临床的医学AI,其核心大多依赖于视觉和图像识别技术。尽管学术界在通用视频大模型上已成果斐然,但镜头一旦转向专业的手术室,挑战便陡然升级。我们仍然面临几个根本性的难题:通用模型难以专精于复杂的医疗任务;高质量的医疗视频数据极度匮乏;更重要的是,大模型在真实医疗任务中的表现,缺乏一个统一、可靠的评估标准。
然而,让AI辅助医疗、提升效率、减轻医务人员的负担,其意义毋庸置疑。市场研究机构Global Information发布的报告也印证了这一趋势,预测基于AI的手术视频分析市场将迎来指数级增长。
基于人工智能(AI)的手术视频分析市场发展迅速,预计将从2025年的7.3亿美元增长到2026年的9.1亿美元,年复合增长率(CAGR)为24.1%。预计未来几年,人工智能(AI)增强型手术视频分析市场将呈指数级增长,到2030年市场规模将达到21.4亿美元,年复合增长率(CAGR)为23.8%。
令人振奋的是,破局的关键已经出现。全球首个规模最大、性能最强的医疗视频理解大模型——元智医疗视频理解大模型(uAI-NEXUS-MedVLM)已经正式发布并开源。这一模型直指前述三大痛点,为AI在医疗视频领域的大规模应用,真正敲开了大门。相关研究成果已被CVPR 2026收录。

把「不可解」变成「可解」
在过去,让大模型理解真实的临床医疗视频,几乎是一个“不可解”的命题。这不仅仅是图像识别那么简单,它需要模型同时攻克空间、时间和语义的三重复杂性。手术中的每一个细节都至关重要,任何疏忽都可能带来无法挽回的后果。
空间上,模型必须精确识别手术器械、器官组织的精确位置及其相互关系;时间上,需要理解动态的操作流程和步骤序列;语义上,则要求模型具备深厚的医学背景知识,能理解每个动作的临床意义。这种“空间-时间-语义”的复杂叠加,让即便是GPT-5.4、Gemini-3.1这样的通用模型巨头,在面对真实手术视频时也几乎全面溃败。
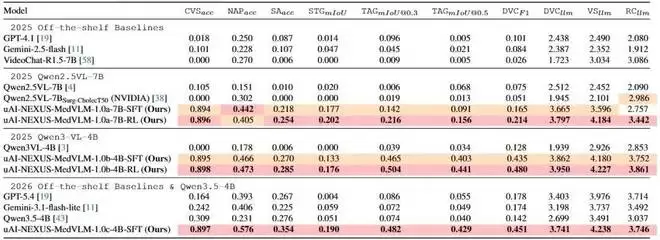
图1:在MedVidBench 8项任务上的主要结果。
数据最能说明问题。在关键安全视野评估(CVS)任务上,GPT-5.4的准确率仅为16.4%,Gemini-3.1为24.2%,近乎随机猜测。在时空动作定位(STG)任务中,预测区域与真实区域的交并比(mIoU)低到可以忽略不计。即便是相对简单的视频摘要生成任务,在满分5分的情况下,主流通用模型的表现也远未达到理想水平。
面对这片“视觉理解的无人区”,联影智能的研究团队选择了一条全新的突破路径。他们的方案可以概括为三件事:建立一把全球公认的“标尺”,构建一套高质量的数据,并发明一种全新的训练方法。
MedVidBench:全球公共标尺
任何领域的进步,都离不开一个统一的评测基准。ImageNet定义了图像分类,GLUE奠定了自然语言理解的基础,但在医疗视频理解领域,长期以来却缺少这样一把“标尺”。
为此,研究团队构建了MedVidBench,一个包含53万余条视频-指令对的大规模基准数据集。它覆盖了8个专业医学数据源,横跨腹腔镜、开放手术、机器人手术及护理操作等核心临床场景。
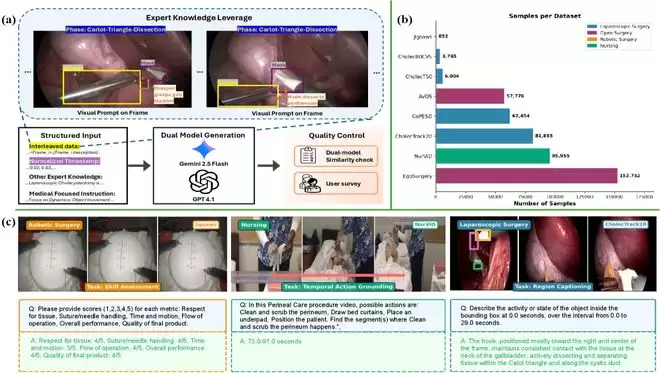
图2:MedVidBench概述。
MedVidBench的关键不仅在于“量大”,更在于其“质优”和“结构完整”。它包含了8个不同的数据集,并设计了“视频级-片段级-帧级”三层评估架构,完整模拟了人类医生由整体到细节的认知过程。为确保数据质量,团队采用了专家引导式提示词工程与双模型交叉验证的严格流程。
GRPO:好上加好
有了高质量的数据,下一个核心问题是:如何训练出最好的模型?
最直观的方法是在特定数据集上进行监督微调(SFT)。基于Qwen2.5-VL-7B模型在MedVidBench上进行SFT后,结果已经相当惊艳,在全部8项任务上全面超越了当时的通用大模型。
但SFT存在性能上限。为了寻求突破,团队引入了强化学习(RL)。然而,标准RL方法在医疗视频这种多任务、多数据集的场景下遇到了致命问题:不同任务难度差异巨大,奖励信号尺度失衡,导致简单任务的梯度会淹没困难任务,最终引发训练崩溃。
团队的解决方案是MedGRPO,其核心是两项关键算法创新。
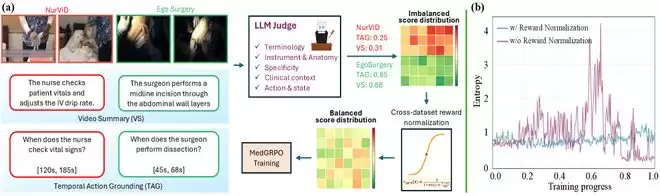
图3:MedGRPO概述。
第一项:跨数据集奖励归一化。 其核心思想是“中位数公平性”——让所有数据集-任务对在中位性能处获得相等的归一化奖励,从而消除梯度更新中的偏差。团队设计了一个基于Logistic函数的归一化方法,确保了训练的稳定与公平。
第二项:医学LLM评审。 这是最具洞察力的创新。团队发现,传统的语义相似度指标根本无法评估医学描述的临床正确性。例如,“工具在上方区域抓取组织”与“抓钳在右上象限分离胆囊管”语义相似度可能很高,但医学准确性天差地别。为此,团队设计了基于GPT-4.1的评审系统,从医学术语精确性、器械与解剖结构识别等五个临床维度进行评判,并与传统指标结合,形成最终的混合评分。
实际效果
那么,这套结合了完善数据集与创新训练方法的模型,表现究竟如何?答案在图1中已经非常清晰:经过完整训练的元智医疗视频理解大模型,在各项任务上的表现远远领先于通用大模型。
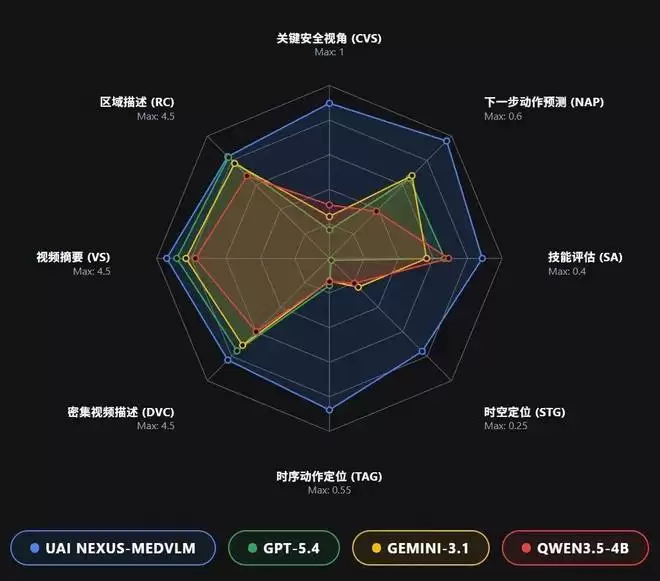
图4:四个模型在MedVidBench上8个任务的主要结果。
这张多维雷达图将模型的优势展现得淋漓尽致,几乎接近“八边形战士”。而以GPT-5.4、Gemini-3.1为代表的通用大模型则表现出明显的“偏科”,即便在其相对擅长的视频摘要任务中,也未能超越专精的医疗模型。
定性的对比更能直观感受模型的进化。以临床护理中的“青霉素皮试”操作为例:

图6:临床护理区域描述任务实验结果
通用大模型在描述中间出现了时间标记错误、动作重复描述甚至“排除残留空气”等幻觉现象。而uAI-NEXUS-MedVLM模型则能准确识别关键步骤的时间位置,精确描述人体部位和专业术语,其输出已从表层动作识别,进阶到对护理操作逻辑的深度理解。
更值得注意的是,MedGRPO方法展现了优秀的泛化能力。在参数更小的4B模型上,通过强化学习训练后,其在多数任务上的表现已经超过了7B参数的SFT基线模型。这说明,高效的医疗视频理解未必需要一味堆叠参数,正确的训练方法论同样至关重要。
广发「英雄帖」,共建基础设施
标尺已经确立,探索有了依据。但要真正推动医疗AI走向实用,就需要全行业共同使用这把标尺,一起推进模型进步和基础设施建设。
为此,团队上线了MedVidBench公开排行榜,向全球开发者发出邀请。任何团队都可以提交自己模型的测试结果,系统将基于统一标准自动评分并动态更新榜单。这不仅仅是一个排行榜,更是一个持续运转的全球竞技平台和信任构建机制。
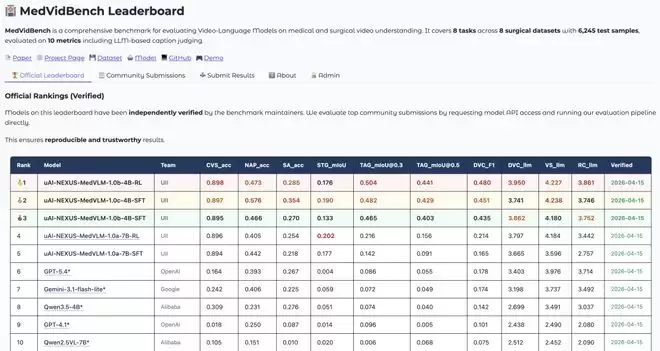
作为该领域首个完善的评测体系,其意义深远:它构建了一个可信的统一评测框架,让所有参与者站在同一起跑线上;它以开放的竞技模式,吸引全球开发者共同挑战,驱动领域快速进步;从更宏观的视角看,一个被广泛使用的基准,意味着其打造者正在从一家公司,转变为全球医疗视频理解领域的基础设施提供者。
技术突破背后的系统性能力
医疗AI发展至今,竞争焦点早已超越单项指标或单次榜单成绩,而在于技术突破背后,是否具备连接真实临床场景、医学数据、算法研究与工程落地的综合能力。
此次实现突破的元智医疗视频理解大模型,其研发团队来自长期深耕AI与医疗融合的创新企业——联影智能。作为联影集团旗下公司,联影智能专注于医疗数字化与智能化。去年发布的“元智”医疗大模型体系,构成了其数智化体系的基座,而本次开源的视频理解大模型,正是其视觉大模型能力的关键延展。
为何是联影智能攻克了这一公认难题?这并非偶然,而是长期、系统性投入的厚积薄发。
第一层,是真实临床场景的长期浸润。 团队在真实医疗环境中积累了海量多模态数据与应用经验,对临床需求有深刻洞察,这让模型从诞生之初就带有“临床可用性”的基因。
第二层,是顶会级算法研究的持续输出。 团队在计算机视觉与医学影像分析领域有深厚积累,相关成果持续发表于CVPR、NeurIPS等顶级会议,确保了方法论的前沿性。
第三层,也是最关键的一环,是从数据源头到模型落地的完整闭环。 团队能够对海量医疗视频进行逐帧级、多维度的高颗粒度精细标注,这种能力使模型从训练伊始就建立在强大的视觉理解基础之上,逐步构建出覆盖“感知-推理-决策”的完整能力体系。
通用大模型在互联网内容上高歌猛进之时,手术室里的摄像机仍在静静记录。在这里,语言的华丽毫无意义,毫米级的精度和对生命的绝对敬畏才是唯一金标准。
展望未来,元智医疗视频理解大模型有潜力与具身智能深度融合,成为打通医疗影像、临床决策与物理执行的智能枢纽,推动复杂医疗操作迈向全面的数字化与智能化。
医疗AI的落地是一场漫长的接力赛。如今,联影智能将模型与数据开源,相当于把“接力棒”递到了全行业手中。毕竟,手术刀尖上的事,唯有汇聚全行业的力量,才能让AI从冷冰冰的论文数据,真正转变为手术室里那盏照亮生命、守护安全的“无影灯”。