在探讨人工智能技术时,大语言模型(LLM)无疑是其核心组成部分与关键驱动力。两者之间并非简单的从属关系,而是一种深度融合、相互促进的共生生态。
从技术本质来看,大语言模型是人工智能,特别是深度学习与自然语言处理(NLP)领域发展到高级阶段的标志性成果。其核心原理在于:通过对海量文本数据进行预训练,模型能够学习并掌握人类语言的语法结构、语义逻辑与知识体系,从而具备出色的自然语言生成、深度理解与智能处理能力。正是凭借这些能力,大语言模型已成为AI执行各类语言任务的“核心引擎”——无论是智能摘要、精准问答、代码生成,还是多语言翻译,其卓越表现都离不开大语言模型的底层支持。

与此同时,大语言模型的快速发展,也反过来成为推动人工智能整体进步的核心动力。这形成了一个持续强化的正向循环。
随着模型参数规模持续扩大、训练算法不断优化,大语言模型在知识更新、复杂指令遵循、多模态理解(如图文关联)等方面的能力取得显著突破。这些进步直接提升了集成该技术的人工智能系统的整体性能与智能化水平,使得AI应用更加“聪慧”与“实用”。
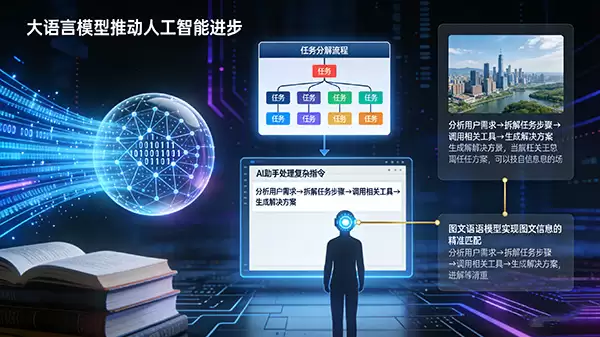
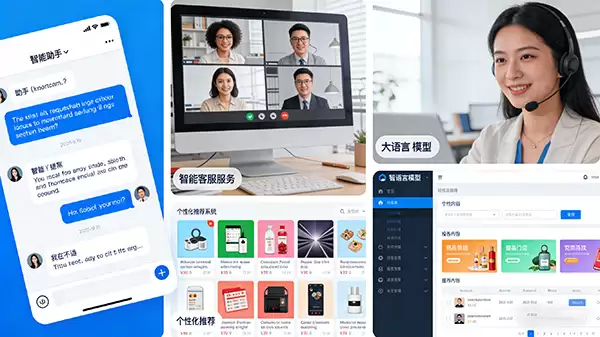
在应用层面,大语言模型的渗透尤为明显。如今,从智能手机中的语音助手、企业级智能客服系统,到个性化内容推荐引擎,大语言模型技术已广泛应用于各行各业。它已从学术研究走向产业落地,为众多业务场景提供高效的AI解决方案,切实提升了工作效率与用户体验。
更为关键的是,大语言模型发展过程中遇到的挑战,持续驱动着人工智能底层技术的创新。面对自然语言的复杂性,为了实现更精准的语义理解、更可靠的文本生成、更高效的逻辑推理等目标,研发人员必须在模型架构、训练策略、评估标准等方面进行持续探索。这些为解决现实问题而诞生的技术创新,也在为人工智能的未来演进开拓新的方向与可能。

综上所述,大语言模型与人工智能正处于协同演进、相互赋能的关键阶段。前者是后者能力输出的前沿代表,后者则为前者提供了持续发展的基础与环境。随着技术迭代加速与应用场景不断拓展,这种深度协同的关系将进一步释放巨大潜力,为社会数字化转型与日常生活变革带来更深远的影响。




