
“我很庆幸能陪在你身边,通过你的目光看世界。”这句源自电影《Her》的经典对白,道出了人们对AI语音助手的终极期待。影片中的Samantha,不仅是一位高效的个人助理,更是一位能够深度共情、提供情感支持的心灵伴侣。
这种理想化的智能交互体验,正是当前AI对话系统研发的核心目标。清华大学计算机系黄民烈教授,作为国内自然语言处理领域的权威专家,在探讨对话AI的未来时也曾提及此片。他所带领团队开发的AI情绪对话机器人Emohaa,正是将技术前沿指向了情感计算与心理健康支持这一关键领域。
这引发了一个核心议题:要让AI对话系统达到Samantha那样善解人意的程度,究竟面临哪些挑战?这种技术差距能否被清晰度量?我们又该如何科学评估一个对话AI的真实水平,判断其是否趋近于那个理想的智能体?
事实上,建立一套客观的评估体系已刻不容缓。当前,从智能音箱内置的语音助手,到各大科技公司推出的开放域聊天机器人,AI对话产品呈现爆发式增长。然而,行业长期缺乏统一、公认的能力评估标准,导致产品性能良莠不齐,评测维度混乱。这不仅阻碍了技术研发的共识形成与良性竞争,也引发了关于AI伦理、安全与边界的广泛社会讨论。
许多一线开发者亦坦言,有时难以精准评估自家系统的真实能力上限。业界普遍呼吁,亟需一套清晰、可操作的分级标准,为AI对话系统的能力成长划定里程碑,让研发、评测与商业化应用有章可循。
正是基于这一迫切需求,黄民烈教授联合学界与产业界的研究力量,参考自动驾驶L0-L5分级框架的成功经验,主导制定了全球首个《AI对话系统分级定义》。该标准已于近期正式发布,旨在为纷繁复杂的对话AI市场,提供一把权威、统一的“度量尺”。
这份分级定义的发布具有里程碑意义。它有望显著推动AI对话技术在多个垂直领域的精准落地,包括智能个人助理、智能家居控制、车载语音交互、情感陪伴以及心理健康服务等。同时,它将加速下一代更智能、更拟人化系统的研发进程,为学术界和工业界提供一个至关重要的参考框架与发展指南。
围绕这份分级标准的核心逻辑与具体内涵,我们与黄民烈教授进行了一次深度访谈。
对话系统分级标准:为何至关重要?
谈及制定标准的初衷,黄民烈教授直接指出了当前行业的核心痛点:技术路径多样,但评估方法却碎片化。
“目前存在一个显著瓶颈,”他分析道,“不同的系统架构与技术路线之间,缺乏公平、有效的横向比较基准。例如,如何评判一个任务型智能音箱与一个开放域聊天机器人,谁的对话能力更强?由于缺乏统一的能力定义与评测体系,导致行业发展水平不一,业界认知也难以对齐。”
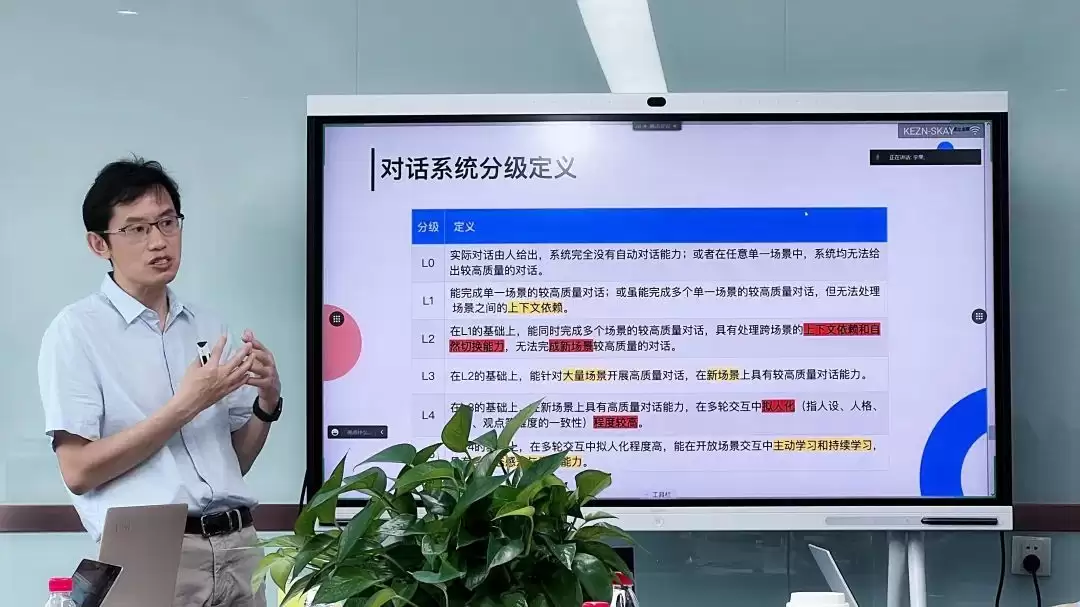
具体而言,任务型对话、开放域闲聊、知识问答等不同技术方向,目前各有其评价指标。但这些指标之间如何关联与换算,一直悬而未决。而这正是《AI对话系统分级定义》旨在攻克的核心难题。因此,团队借鉴了自动驾驶从L0(无自动化)到L5(完全自动化)的分级思想,为对话AI同样规划了六个渐进的能力等级。
解读L0至L5:对话AI的能力进化之路
当然,对话系统的复杂性远超驾驶场景。自动驾驶分级主要关注控制权的移交,维度相对单一。而对话系统则涉及意图理解、上下文管理、知识运用、情感表达、人格一致性等多重复杂维度。
经过深入研讨,团队确立了制定分级的五项核心原则:
第一,聚焦于完全由机器主导的自动化对话系统,人机混合模式暂不纳入;第二,从系统最终呈现给用户的能力和体验出发,而非拘泥于底层技术实现;第三,每个等级所对应的能力必须是可观测、可测试、可量化的;第四,不预先严格划分任务类型,统一以“对话场景”来涵盖;第五,分级标准应对未来的技术研究与应用部署,具备前瞻性的指导价值。
基于这五大原则,AI对话系统从L0到L5的能力蓝图得以清晰绘制:
L0级:无自动对话能力。 对话实质上完全由人工完成。系统要么不具备自动化对话功能,要么在任何单一场景下都无法产出质量合格的对话内容。
L1级:单一场景专家。 能够在某个特定场景(如查天气、设闹钟)下完成高质量对话。但其局限在于:无法理解和处理跨场景的上下文关联。例如,用户先询问“北京天气如何”,接着问“那需要带伞吗?”,L1系统可能无法将“下雨可能性”与“带伞”建议自然关联。
L2级:多场景协调专家。 在L1基础上,能够同时处理多个已知场景的高质量对话,并具备跨场景的上下文理解与无缝切换能力。例如,用户从“预订航班”切换到“预订目的地酒店”,再询问“当地景点推荐”,L2系统能够理解这些请求服务于同一出行计划。但其能力边界在于:无法处理训练数据之外的全新、未知场景。
L3级:未知场景探索者。 这是能力的关键分水岭。在具备L2能力的同时,L3系统在面对大量未见过的、全新的对话场景时,依然能够进行较高质量的交互。标准对“大量”未作僵化数字限定,以保持普适性,但其核心标志——“处理新场景的泛化能力”——非常明确。
L4级:初具人格的智能体。 在L3的基础上,对系统的拟人化与一致性提出了更高要求。它需要在长程多轮对话中,稳定维持特定的人设、性格、情感基调与观点立场。例如,一个设定为“乐观助手”的AI,不应在后续对话中突然变得悲观或冷漠。维持稳定可信的“人格”,是当前对话AI面临的主要挑战之一。
L5级:持续进化的多模态伙伴。 这是对话系统的终极形态。在满足L4所有要求的基础上,L5系统需在开放环境的交互中具备主动学习与持续进化能力,并能进行多模态的感知与表达(如理解语调、表情、手势,生成相应的语音、图像或动作)。这意味着它能像人类一样,通过交互积累经验,并融入元宇宙、超写实虚拟人等前沿应用,实现真正的“全息智能交互”。
从执行固定任务的L1,到应对未知的L3,再到具备人格一致性与多模态能力的L4、L5,这套分级标准清晰地勾勒了AI对话系统从“专用工具”到“通用伙伴”的演进路径。它不仅为技术研发设立了清晰目标,为产品评测提供了客观依据,也让我们向着《Her》中所描绘的、充满温度的人机共生未来,迈出了坚实的一步。