2026年4月,备受关注的SuperCLUE-VLM中文多模态大模型评测榜单正式发布,结果揭示出行业竞争格局的新变化。国产AI模型阵营实现了集体突破,表现尤为抢眼。其中,字节跳动旗下的豆包大模型(Doubao-Seed-2.0-Pro-260215)以90.66的综合得分荣登榜首,超越了谷歌的Gemini-3.1-Pro-Preview(89.35分),展现出强大的技术实力。
本次评测汇聚了全球范围内17款主流视觉语言模型(VLM)。一个显著的结论是,中国自主研发的模型整体表现突出。阿里巴巴的通义千问Qwen3.5系列、商汤科技的SenseNova、智谱AI的GLM等国内核心厂商的模型均位列榜单前茅。相比之下,OpenAI的GPT-5.4、X.AI的Grok等国际顶尖模型此次排名处于中游位置,标志着在中文多模态赛道,国产模型已实现整体性的追赶与超越。
此次评测具体考察了哪些能力?整个评估体系围绕三大核心维度构建:基础视觉认知、复杂视觉逻辑推理以及视觉实际应用能力。具体涵盖了通用图像识别、图文图表深度分析、医学影像辅助判读等高达25项细分任务。从得分分布来看,国产模型在图像基础感知、数据图表解析等任务上优势显著,平均得分突破90分,体现了其出色的系统鲁棒性与任务完成稳定性。然而,在需要多步复杂推理的视觉问题解答,以及工业质检、临床辅助诊断等高精度专业场景中,模型性能仍有提升潜力,部分垂直领域的得分表现有待进一步强化。
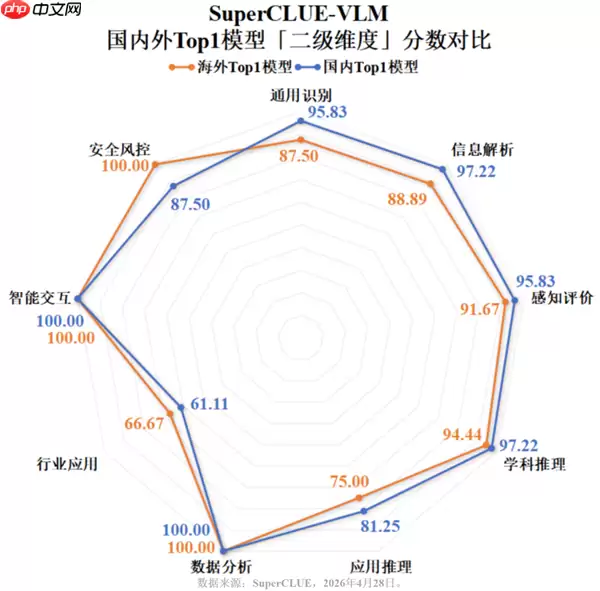
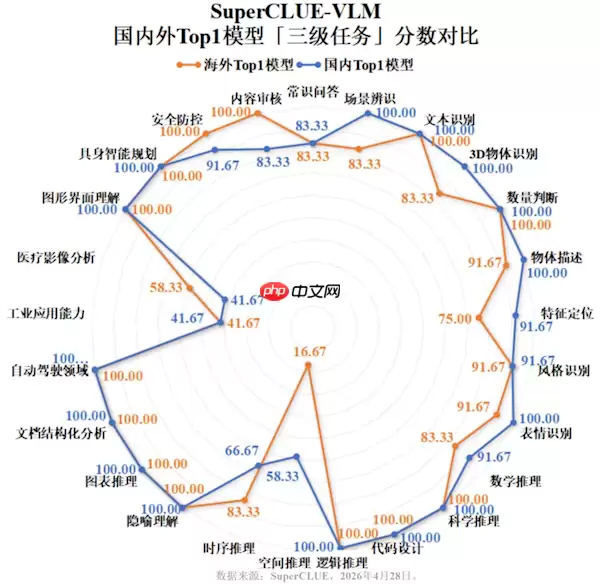
总体而言,这份最新的中文多模态模型排行榜单可能预示着行业进入了新的发展阶段。国产模型在中文语境下的语义理解深度、视觉与语言信息的跨模态对齐能力,以及对本土化应用需求的精准适配方面,已呈现出全面的领先优势。这不仅仅是评测分数上的反超,更是其底层技术路线日趋完善、应用生态持续成熟的综合体现。





