近期关于苹果Vision Pro项目被搁置的传闻,可以暂时画上句号了。多项最新公开的研究成果显示,苹果在空间计算领域的探索不仅没有停滞,反而正在向更深层次、更核心的技术难题发起攻关。
上月曾有消息称,苹果内部研发重心已从新款Vision Pro转向了Siri与AI智能眼镜,这引发了外界对其头显项目是否暂停的猜测。然而,最新公示的三项研究论文给出了截然不同的信号。这些研究分别聚焦于多模态大模型的空间功能推理评测、美国手语的自动化视频标注,以及大规模高质量的3D头部重建——每一项都精准指向了下一代空间计算体验的核心技术瓶颈。
从“物体在哪”到“能做什么”:重新定义空间AI的智商基准
最直接相关的一项研究,是苹果在其机器学习研究博客上发布的论文《从物体所在之处到其功能用途》。该论文提出了一个名为“SFI-Bench”的全新评测基准,其目标非常明确:评估多模态大模型是否不仅能理解空间布局,更能深入理解物体的功能用途与交互逻辑。
这套基准包含134段室内环境视频扫描数据,并由此衍生出1555道由专家精心标注的问题。其独特之处在于,提问方式超越了传统的“这是什么?它在哪里?”,转而深入追问“这个东西具体怎么使用?”甚至“如果它出现故障,该如何排查解决?”。
例如,模型可能需要从橱柜中识别出同品牌数量最多的一组瓶子,理解如何取消一台正在运行的洗衣机的当前程序,或者判断电视遥控器上某个特定按钮的具体功能。这种评测思路,显然比单纯的空间物体识别更贴近真实的家庭生活与交互场景,也更接近于未来空间计算智能助手所需处理的复杂现实任务。

苹果人工智能研究团队测试大语言模型对物理世界的理解能力。图源:苹果公司
在最终的评测结果中,Google的Gemini 3.1 Pro总分最高,OpenAI的GPT-5.4-High位列第二,Gemini-3.1-Flash-Lite排名第三。但论文也明确指出了当前主流模型的共同短板:几乎所有模型在处理“带条件的全局计数”任务时都表现不佳,并且在空间记忆、功能知识整合,以及将视觉场景与外部知识库进行有效关联的能力上,仍有显著的提升空间。
降低技术门槛:利用AI为手语标注“减负增效”
另一项研究《利用手语模型自举生成手语标注》则着眼于无障碍交互领域。其核心创新思路是利用AI模型自动生成候选标注,从而将手语视频标注从一项需要耗费数百小时人工的繁重工作中解放出来,大幅提升效率。
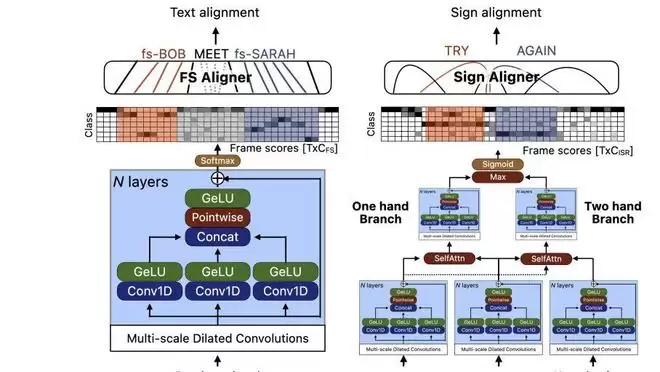
苹果研究人员探索使用人工智能模型进行美国手语(ASL)自动化标注的可能性。图源:苹果公司
研究团队首先建立了近500条从人工标注的英文字词到专业术语的映射对,并以此为基础,将自动化标注范围扩展至超过300小时的ASL STEM Wiki数据和7.5小时的FLEURS-ASL数据。最终,其研发的手指拼写模型在FSBoard数据集上达到了6.7%的字符错误率(CER),在ASL Citizen数据集上则实现了74%的Top-1准确率。这项技术若能成熟落地,将为听障人士带来更流畅、更便捷的沉浸式交互体验,而这正是Vision Pro等头戴式沉浸设备需要攻克的关键无障碍课题之一。
打造逼真数字分身:高质量3D头部重建的技术突破
第三项研究《基于多视角采集的大规模高质量3D高斯头部重建》聚焦于虚拟形象(Avatar)的逼真度与实时渲染。苹果提出了一种名为“HeadsUp”的创新方法,能够从大规模的多摄像头同步采集数据中,高效重建出高质量的3D高斯散射头部模型。
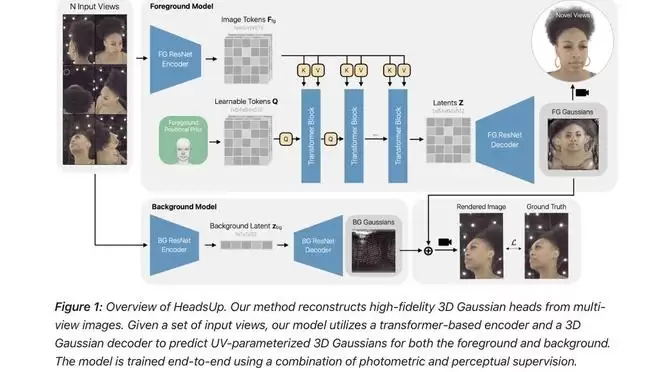
苹果人工智能研究人员探索如何利用多视角图像创建高保真3D头部模型。图源:苹果公司。
这项研究使用了一个包含超过10000名受试者的内部数据集,其数据规模比现有的公开多视角人头数据集高出一个数量级。不难推断,这项技术的突破,与Vision Pro的“Persona”(虚拟人物)功能,或是未来visionOS生态中更自然、更实时的人脸捕捉与微表情渲染息息相关。更逼真、更具表现力的数字分身,无疑是消除虚拟与现实隔阂、提升远程社交临场感的核心技术要素。
苹果全球营销高级副总裁格雷格·乔斯维亚克(Greg Joswiak)此前曾表示,Vision Pro展示了数字世界与物理世界融合的未来形态,并认为这种融合是必然趋势。当被问及具体时间表时,他坦言无法精确预测“空间计算”何时能成为主流,但坚信这一技术方向不可逆转。如今看来,这些扎实而前沿的基础研究,正是苹果为那个“不可逆转”的混合现实未来所埋下的关键伏笔与坚实注脚。




